

前言
Linux的基本特点之一是一切皆文件,在系统管理过程中难免会需要查找特定类型的文件,那么问题来了:如何进行有效且准确的查找呢?本文将对Linux系统中的文件查找工具及用法进行详细讲解。
常用工具对比
常用的文件查找工具主要有locate(非实时查找)和find(实时查找)。locate查找依赖于索引,而索引构建相当占用资源,索引的创建是在系统空闲时由系统自动进行(每天任务),手动进行创建则可使用updatedb命令,查找速度快但结果非精确,即为模糊查找。而find相对于locate而言,是遍历所有文件进行条件匹配,查找速度慢但结果精确,即为精准查找。简言之,对于实际生产环境,find(实时查找)无疑是最有效的文件查找工具。
find的用法
命令格式:
find [options] [查找路径] [查找条件] [处理动作]
查找路径:默认为当前目录
查找条件:默认为指定路径下的所有文件
处理动作:默认为显示至屏幕
条件查找
-name "文件名称":支持使用globbing字符
*:任意长度任意字符
?:任意单个字符
[]:范围内任意字符
[^]:范围外任意字符
-iname "文件名称":查找时忽略字符大小写
-user USERNAME: 根据文件的属主查找
-group GRPNAME: 根据文件的属组查找
-uid UID:根据用户UID查找
-gid GID:根据用户GID查找
-nouser: 查找没有属主的文件
-nogroup: 查找没有属组的文件
组合条件查找
-a:与,同时满足 -o:或,满足一个即可 -not:!非,条件取反
文件类型查找
-type TYPE:根据文件类型查找
f:普通文件
d:目录文件
l:符号链接
b:块设备
c:字符设备
s:套接字文件
p:命名管道
-size [+|-]#UNIT:根据文件大小查找
常用单位:k,M,G
#UNIT:#-1<x<=#
-#UNIT:x<=#-1
+#UNIT:x>#
(x为匹配到的文件大小)
时间戳查找
以“天”为单位
-atime(访问时间) [+|-]#
+#:x>=#+1
-#:x<#
#:#<=x<#+1
(x为匹配到的文件时间)
-mtime(修改时间)
-ctime(改变时间)
以“分钟”为单位
-atime
-mtime
-ctime
(用法同上)
权限查找
-perm [+|-]MODE
MODE:与MODE精确匹配
+MODE: 任何一类用户的权限只要能包含对其指定的任何一位权限即可
-MODE:每类用户指定的检查权限都匹配
处理动作
-print: 默认处理动作,显示
-ls:类似于ls -l
-exec COMMAND {} \;
-ok COMMAND {} \;
find一次性查找符合条件的所有文件,并一同传递给给-exec或-ok后面指定的命令,但有些命令不能接受过长的参数,此时使用另一种方式:
find | xargs COMMAND
find实战
#查找/scripts/目录中包含s以.sh结尾的文件并复制到/tmp目录


#查找/var/目录属主为root且属组为mail的所有文件

#查找/usr目录下不属于root、bin或scholar的所用文件

#查找/tmp/目录下最近一周内其内容修改过的,且不属于root且不属于scholar的文件

#查找当前系统上没有属主或属组,且最近1个月内曾被访问过的文件
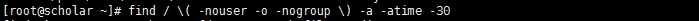
#查找/etc/目录下大于1M且类型为普通文件的所有文件

#查找/etc/目录所有用户都没有写权限的文件
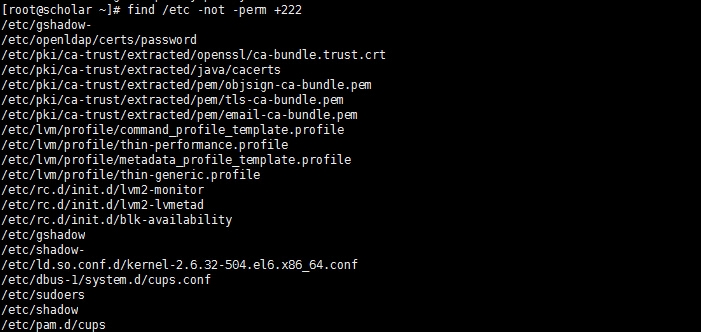
#查找/etc/目录下至少有一类用户没有写权限 #由于文件过多,已重定向

#查找/etc/rc.d/目录下,所有用户都有执行权限且其它用户有写权限的文件 #由于文件过多,已重定向

The end
对于权限查找+222和-222的取反匹配,学习时错误的只对+222和-222取反,可懵了好一会才想明白。最后在啰嗦一句,切记:权限查找取反是对全局匹配取反,而不是只对权限取反!!!
以上只是学习总结,如有错漏,大神勿喷~~~
本文出自 “北城书生” 博客,请务必保留此出处http://scholar.blog.51cto.com/9985645/1623450
原创文章,作者:书生,如若转载,请注明出处:http://www.178linux.com/1368

评论列表(3条)
帮你重新格式化了代码段,进行了部分字体格式和大小调整,整体缩进段距,看起来要稍好些,加没
@stanley:3Q :mrgreen: :mrgreen: :mrgreen:
mark