

我们都知道,计算机只能识别二进制程序,而程序员编写的源代码都是以纯文本形式存在,因此,要想让计算机识别并运行这些源代码程序,就必须通过中间的转换机制让源代码变为二进制程序文件,而这种转换过程就称为编译过程。Linux的各发行版本中由于各厂商的编译过程不尽相同,因此就诞生了各种不同的软件管理包组件。其中我们最熟知的就要数Redhat系列的rpm包了。
rpm包是通过预先编译并打包成为rpm文件格式,再加以安装到系统的方式,并且还能够进行数据库的记载,因此,rpm有很多优点:
- rpm内含有已经编译过的程序与配置文件等数据,可以让使用者免去重新编译的困扰;
- rpm在被安装之前,会先检查系统的硬盘容量、操作系统版本号等,可避免文件被错误安装;
- rpm文件本身提供软件版本信息、依赖性关系、软件用途说明、软件所含文件等,便于了解软件;
- rpm管理的方式使用数据库记录rpm文件的相关参数,便于升级、移除、查询和验证等。
既然rpm包这么重要,那么接下来就来聊一聊如何管理rpm类型的软件。rpm类型的软件管理工具为rpm命令,有安装、升级、卸载、查询和校验等功能操作。
安装
rpm {-i|–install} [install-options] PACKAGE_FILE
安装选项:
- -h:以#来表示安装进度;
- -v:显示安装过程中的详细信息;
- –test:测试安装,检查并报告依赖关系及冲突消息等;
- –nodeps:忽略依赖关系;
- –replacepkgs:重新安装并覆盖原有文件;
- –force:强制安装
升级
rpm {-U|–upgrade} [install-options] PACKAGE_FILE
rpm {-F|–freshen} [install-options] PACKAGE_FILE
此处的-U表示升级或安装,而-F仅表示升级之意。
卸载
rpm {-e|–erase} [–allmatches] [–nodeps] [–noscripts] [–test] PACKAGE_NAME
选项:
- –allmatches:卸载所有匹配指定名称的程序包的各个版本;
- –nodeps:卸载时忽略依赖关系;
- –test:测试卸载;
查询
rpm {-q|–query} [select-options] [query-options]
选择选项:
- -a, –all:查询所有已经安装过的包;
- -f FILE:查询某文件由哪个程序包安装生成;
- -p PACKAGE_FILE:用于实现对未安装的程序包执行查询操作;
查询选项:
- –changelog:查询rpm包的changlog;
- -l, –list:程序安装生成的所有文件列表;
- -i, –info:程序包相关的信息,版本号、大小、所属的包组;
- -c, –configfiles:查询指定的程序包提供的配置文件;
- -d, –docfiles:查询指定的程序包提供的文档;
- -R, –requires:查询指定的程序包的依赖关系;
校验
rpm {-V|–verify} [select-options] [verify-options]
在实际的使用中,因为rpm包是不会自动解决依赖关系,因此在rpm包的管理中往往会遇到各种依赖关系,那么有没有办法自动解决这些依赖关系呢?答案当然是有,yum就是这样一个工具,yum其实是rpm的前端管理工具,能够从指定的服务器自动下载RPM包并安装,可以自动处理依赖性关系,并且一次性安装所有依赖的软件包。
yum命令的用法非常简单:yum [options] [command] [package …],主要有如下功能选项:
- 显示仓库列表: yum repolist [all|enabled|disabled]
- 显示程序包:yum list [all | glob_exp1] [glob_exp2]或者yum list {available|installed|updates} [glob_exp1]
- 安装程序包:yum install package
- 升级程序包:yum update package
- 卸载程序包:yum remove | erase package
- 查看程序包信息:yum info package
- 构建本地缓存:yum makecache
- 清理本地缓存:yum clean
- 列出所有包组:yum grouplist
- 显示指定包组详情:yum groupinfo group_name
- 安装包组:yum groupinstall group_name
- 卸载包组:yum groupremove group_name
- 升级包组:yum groupupdate group_name
- 安装本地程序包文件:yum localinstall rpmfile
虽然yum可以很方便的安装软件,但是yum严重依赖于yum仓库,如果仓库里面没有对应指定的软件,那么安装时不会成功的,因此我们在安装之前必须给yum配置好对应的软件仓库。yum仓库的位置及其相关的各种配置信息保存在yum的配置文件中,各仓库的定义主要在/etc/yum.repo.d/*.repo文件中。在此文件中主要要定义几个内容:
- [repositoryid]:对于当前系统的yum来说,此repositoryid用于唯一标识此repository指向,因此,必须唯一;
- name:当前仓库的描述信息;
- baseurl:指明仓库的访问路径,可以是ftp服务器、http服务器或者本地的目录;
- enabled:指明此仓库是否可被使用;
- gpgcheck:是否对程序包做校验;
- gpgkey:指明校验文件的路径;
- cost:指明当前仓库的访问开销,默认为1000;
因此如果要指定一个网络源仓库,则可以在/etc/yum.repo.d/路径下新建以.repo结尾的文件,文件内容如下(163仓库为例):
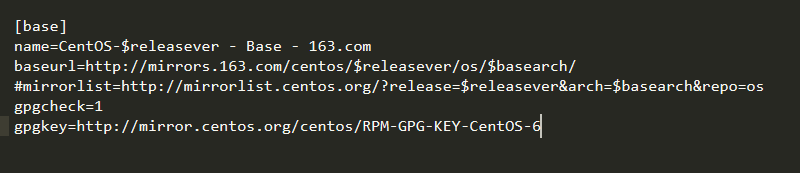

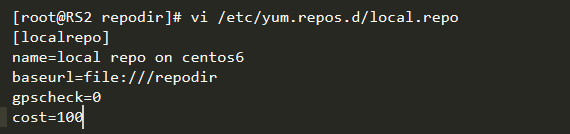
在实际的工作中,如果你作为一个企业的网络管理员,为了方便公司内部网络中的服务器安装软件,同时也为了节约网络带宽,通常需要在公司内部创建一个yum仓库,下面就谈谈如何创建本地yum仓库。
- 安装createrepo软件用于生成yum的软件元数据信息;
- 确定repository的输出方式:本地file的形式输出或者本地网络的方式输出;
- 在准备的目录下放置下载好的rpm程序包文件;
- 在此目录下运行createrepo命令;
通过以上步骤就已经完成yum仓库的创建了。

本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/90805
