

正则表达式入门
谈到正则表达式,我们就得先了解一下POSIX。POSIX的全称是Portable Operating System Interface for
uniX,它由一系列规范构成,定义了UNIX,linux操作系统应当支持的功能,它定义了BRE(Basic Regular Expression,基本型正则表达式)和ERE(Extended Regular Express,扩展型正则表达式)两大流派。
正则表达式由只代表自身的字面值和代表特定含义的元字符组成,除非特别说明,正则表达式严格区分大小写。正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,遵循量词或边界指定的规则来匹配。

基础正则表达式中,如果你想使用? + () {},因为他们表示特殊含义,所以你需要将他们转义
而扩展正则表达式中,如果你想使用? + () {} ,就没必要加“\”了,进化版的正则表达式在这方面给我们提供了很大的便利
所谓特殊含义,就是正则表达式中的含义。非特殊含义,就是这个符号本身。
+,和*中大家会遇到贪婪模式的说法,也有称最长匹配原则,本质就是趋向于最大长度匹配。”.*”这个组合几乎可以匹配所有,贪婪性赤裸裸的暴露出来了。
基本正则表达式(BRE)
字符匹配
(匹配的时候需要使用两个方括号,如[[ :alpha:]]) . 表示任意单个字符,.会匹配除了换行符的任意字符 [ ] 表示匹配范围内的任意单个字符 [^ ] 表示匹配范围外的任意单个字符 [:alpha:] 任意一个字母(相当于a-zA-Z) [:upper:] 任意一个大写字母(相当于A-Z) [:lower:] 任意一个小写字母(相当于a-z) [:digit:] 任意一个数字(相当于0-9) [:space:] 水平和垂直的空白字符(比blank包含的更多) [:blank:] 空白字符(空格和制表符) [:punct:] 标点符号 [:alnum:] 任意字母和数字(相当于0-9a-zA-Z) [:print:] 可打印字符
匹配次数
* 表示*号前面的一个字符的0-N次(它有一个贪婪模式,会尽量匹配最长)
.* 表示任意多个长度的字符
\? 表示\?符号前的字符0-1次
\+ 匹配\+前的字符至少1次
\{m,n\} 表示\{m,n\}符号前的字符的m-n次
\{m\} 表示{m\}符号前的字符m次
\{n,\} 表示匹配前面字符至少n次
\{,n} 表示匹配前面字符最多n次
位置锚定
^ 之后接字符 表示^ 之后的字符出现在行首 $ 之前接字符 表示$之前的字符出现在行尾 \> 表示\> 符号之后的字符出现在单词的尾部 \< 表示\< 之前的字符出现在单词的首部 \<字符 \> 表示只有小于号和大于号之间的字符
分组
分组 : \(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如 : \(root\)+ 后向引用 : 引用前面的分组括号中的模式所匹配字符,而非模式本身 或者 : \|
拓展正则表达式(ERE)
字符匹配
. 表示任意单个字符,.会匹配除了换行符的任意字符 [] 匹配指定范围内的任意单个字符 [^] 匹配指定范围外的任意单个字符 [ :alnum : ] 字母和数字 [ :alpha : ] 代表任何英文大小写字符,亦即 A-Z, a-z [ :lower : ] 小写字母 [ :upper : ] 大写字母 [ :blank : ] 空白字符(空格和制表符) [ :digit : ] 十进制数字 [ :xdigit : ] 十六进制数字 [ : graph :] 可打印的非空白字符 [ :print :] 可打印字符 [ :punct :] 标点符号
匹配次数
* 匹配前面字符任意次,包括0次
? 0或1次
+: 1次或多次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次,至多n次
{,n} 匹配前面的字符至多n次
{n,} 匹配前面的字符至少n次
位置锚定
^ 行首锚定,用于模式的最左侧 $ 行尾锚定,用于模式的最右侧 \< 或 \b 词首锚定,用于单词模式的左侧 \> 或 \b 词尾锚定;用于单词模式的右侧 \<PATTERN\> 匹配整个单词
分组
():分组,后面可以使用1 ,2 ,3...引用前面的分组 a|b : a或b
优先级
|
优先级 |
符号 |
|
1 |
\ |
|
2 |
( )、(?: )、(?= )、[ ] |
|
3 |
*、+、?、{n}、{n,}、{m,n} |
|
4 |
^、$ |
|
5 |
| |
实战
(思考的出发点不同,过程也就不尽相同,过程和结果同样重要)
1找出/etc/rc.d/init.d/functions的基名(basename可以直接获取)。

2 找出/etc/rc.d/init.d/functions的目录名(dirname可以直接获取)。

3 统计last命令中以root用户登录的每个主机IP登录次数。

4 显示ifconfig命令中所有的IPV4地址。
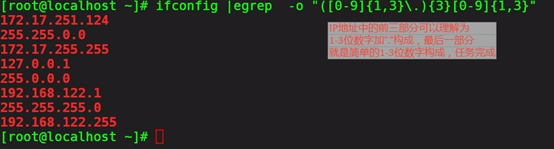
5显示/etc/passwd中以/bin/bash结尾的行。

基于最近的学习整理的资料,尚有诸多不足之处,还望大佬们多多指点!
原创文章,作者:LinuxWalker,如若转载,请注明出处:http://www.178linux.com/83036
