

一:答疑解惑:
这是因为该文件所在分区的inode号被用尽,虽然分区的剩余容量还有很多。
二:基本原理:
inode为何物block又为何物?以及,inode都有哪些特征?
①我们知道,在linux文件系统中,文件名只是计算机用来给人看,而计算机本身只识别文件所对应的数字或编号,而这个编号或数字就是inode(大小为128bytes)。inode用来记录文件的属性,一个文件占用一个inode,同时inode还记录此文件的数据所在的block号码。
※注:文件属性大致包括:
1.文件的访问模式
2.文件所有者和所属组
3.文件大小
4.时间戳(atime,mtime,ctime)
5.定义文件特征的标志(flag),如SetID等。
6.文件真正内容的指向
②block也叫做数据块,用来存放文件中的数据。当文件大小大于block大小事,则一个block文件可占用多个block块,呈上,如果文件小于block,则该block剩余空间将不能被使用。
好,如果到这里,你还有些似懂非懂,那就废话不多说,直接上图:
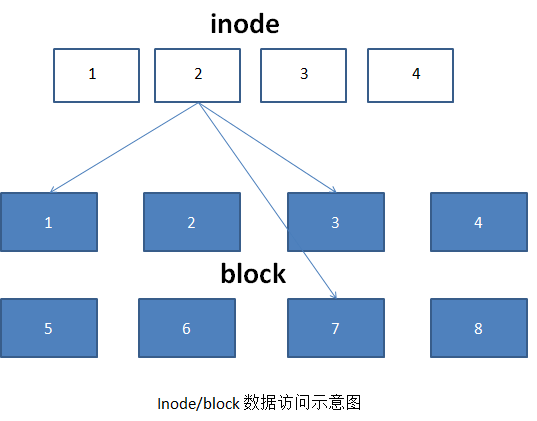

③inode的特点:
1.每个inode大小为均为128bytes
2.每个文件只会占用一个inode,而一个inode可以被多个文件名所引用,而后面的这种属性也就是硬链接(hard link)的原理。
3.每个分区都有固定的inode数量,因此,文件系统能够创建的文件数量与inode的数量有关,所以,当文件系统inode号被用光后,就无法再添加新的文件。
4.系统读取文件的顺序;找到文件名所对应inode–>分析inode所记录的文件权限是否与用户权限相符合–>若符合,则读取inode所对应的block。
好了,都说光说不练假把式,要想了解inode的真正含义,还得实践出真知,实验如下:
三:实验:
第一步:将/dev/sda1 挂载到新创建的目录 /zdd 下,并通过df -h 和 df -i 查看此分区的磁盘内存使用情况和磁盘inode使用情况:
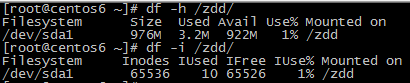
图一
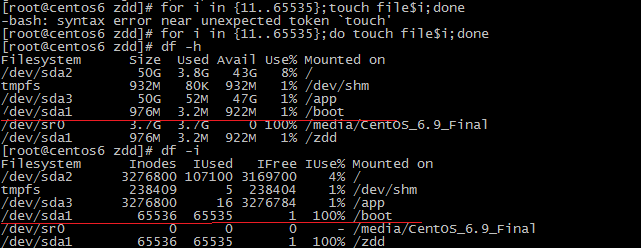
第二步:从图一中我们看到,此分区的内存和inode号还有很大剩余,那么,接下来就在/zdd 下创建65525个文件,文件名分别是file{11..65535}:
图二
第三步:由图二可以看出,创建大量文件后,/dev/sda1虽然磁盘空间仅用了将近1%,但inode号却用了将近100%,只剩下1个可以使用,所以,在创建到第二个新文件时,意料之中就会发生图三创建失败的结果:

图三
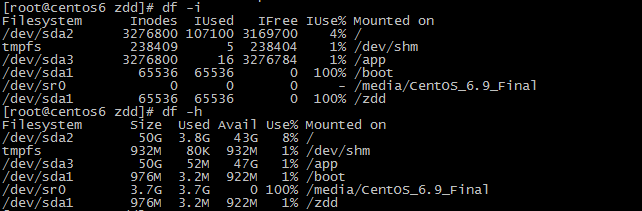
图四
好了,到这里,标题中的问题基本上已经得到了解决,而有关inode和block的相关内容事实上远不止这些,所以,骚年,静下心来多学习思考吧,只有丰富了头脑,才能拥有一身本事报效我们可爱的祖国 ,来,跟着我一起念:富强、民主、文明、和谐、敬业、、、、、、、、、、、、、、
,来,跟着我一起念:富强、民主、文明、和谐、敬业、、、、、、、、、、、、、、
原创文章,作者:yunyunyu,如若转载,请注明出处:http://www.178linux.com/82233
