

我们之前已经解释过了分布式存储,分布式存储有很多的解决方案,其中有个开源程序叫做HDFS,HDFS+MAPREDUCE=hadoop。
hadoop不算是单存的分布式存储,我们之前提到的Mogilefs和Fastdfs都是分布式存储。hadoop属于分布式计算,MAPREDUCE是一个编程的框架,使得程序可以并行计算。
HDFS适用于存储单个大文件,在存储中内置块大小为64M,会将大文件分片存储,同时也支持存储海量的文件。
MAPREDUCE就是基于上面存储的文件进行处理,分析。
上面提到了hadoop是由mapreduce+hdfs组成,因此他也是两个集群,hdfs分成了一个主节点和N个从节点,从节点主要用于存储数据,主节点存储从节点的元数据信息,有点类似于之前介绍的fastdfs由从节点向主节点汇报自己的状态,存储的文件等等。mapreduce(hadoop2.0以后)也分为了两块,一块称为RM(resource manager)一般运行与单个主机上,一块称为NM(node manager)运行在每个存储节点之上,RM负责接收用户的任务,并将任务发往NM之上,在NM之上又会生成一个AM(application manager),再由AM管理具体任务的执行。
接下来就来简单配置一个伪分布式的hadoop(因为上述所有进程都运行在一个主机上,因此命名为伪分布式)
下载官网的tar包。
hadoop运行与java虚拟机之上,所以先得去配置java环境
[root@localhost ~]# yum -y install java-1.8.0-openjdk-devel java-1.8.0-openjdk
[root@localhost ~]# vi /etc/profile.d/java.sh
[root@localhost ~]# cat /etc/profile.d/java.sh
export JAVA_HOME=/usr #此处指明java目录即可,hadoop在运行时会自动找java目录下bin/java
export HADOOP_PREFIX=/usr/local/hadoop-2.7.1
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_MAPPERD_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
配置java以及hadoop配置环境
编辑hadoop目录中etc/hadoop/core-site.xml文件,添加一下内容。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
<final>true</final>
</property>
hadoop的配置文件格式name相当于一个指令,value就是指令值。
同目录下yarn.site.xml添加此段
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.20.105:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
同目录下hdfs.site.xml添加此段
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hdfs/snn</value>
</property>
[root@localhost hadoop-2.7.1]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@localhost hadoop-2.7.1]# vi etc/hadoop/mapred-site.xml
复制此模板文件,并编辑此文件,添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
所有配置文件就准备好了,每个配置文件中都有很多参数,具体参数详情查看以下官方文档。(网上也有很多别人翻译好的)
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/core-default.xml
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
http://hadoop.apache.org/docs/r2.7.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
http://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
创建配置文件中指定的目录
[root@localhost sbin]# mkdir /data/hdfs/{nn,sn,dn} -pv
[root@localhost hadoop-2.7.1]# mkdir logs #创建日志目录,日志会保存到这里
[root@localhost hadoop-2.7.1]# hdfs namenode -format #格式化NN
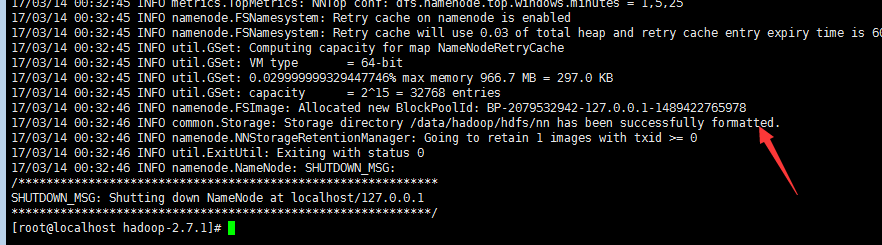

看到箭头那行证明格式化成功,接着启动所有服务
[root@localhost hadoop-2.7.1]# hadoop-daemons.sh start datanode
[root@localhost hadoop-2.7.1]# hadoop-daemons.sh start name
[root@localhost hadoop-2.7.1]# yarn-daemon.sh start resourcemanager
[root@localhost hadoop-2.7.1]# yarn-daemon.sh start nodemanager
启动服务时回要求输入密码,因为默认是通过ssh协议链接到个节点的主机上启动,另外启动secondary时会报错提示找不到secondary节点,这里我们不用管它
[root@localhost hadoop-2.7.1]# vi etc/hadoop/hadoop-env.sh #启动服务时提示找不到JAVAHOME ,我核实了多遍,发现没有问题,结果发现这个文件里面定义了一个JAVA_HOME,把他改一下即可
接着可以看到起来了一大堆端口,其中关注最多的应该是
50070:监控存储节点的web接口
8088:监控运行任务的web接口
其他80的基本是程序员写程序调用的接口
其他50的基本是hdfs通讯所用到的接口
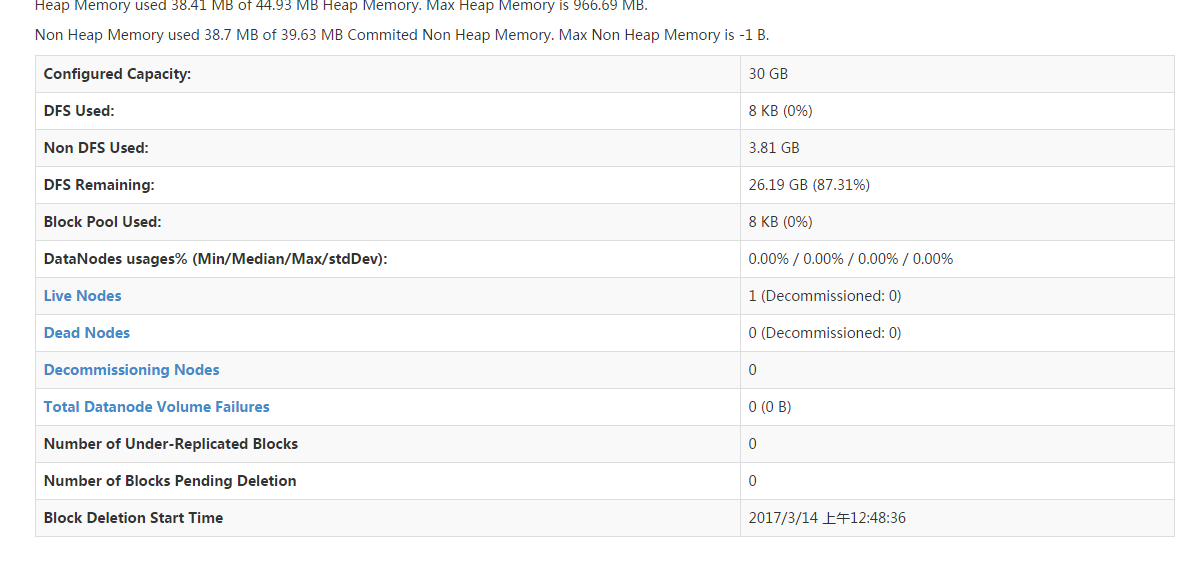
存储的状态界面
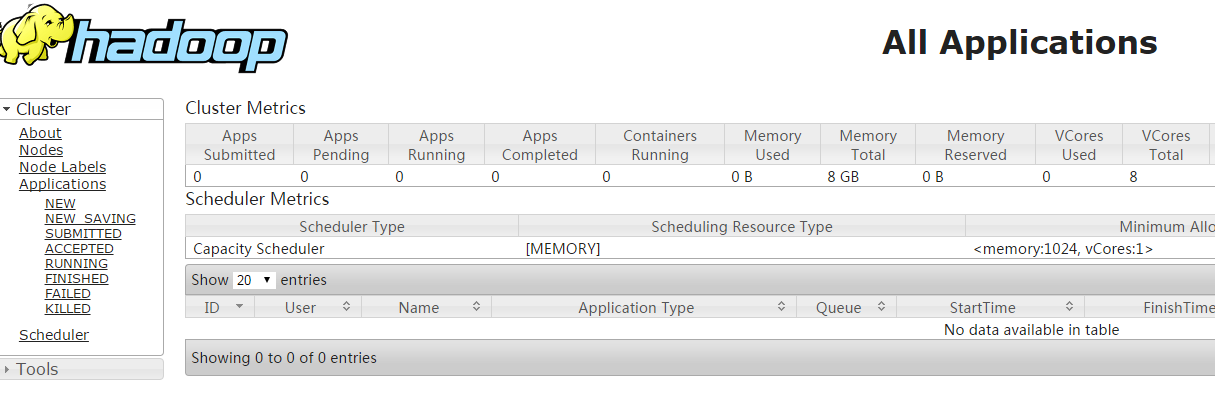
运行任务的状态界面
实际应用中出于安全考虑应该以普通用户的身份启动各服务。
有一点没需求,就当是学习完整理下思路。
原创文章,作者:N24_Ghost,如若转载,请注明出处:http://www.178linux.com/71067

评论列表(1条)
对hadoop的基础配置描述的非常详细清晰,继续加油。