

本次实验基于【MHA+keepalive 高可用MYSQL集群】(续)
一、恢复背景
二、修复故障节点及MHA集群
三、提升已修复的节点为master
四、注意事项
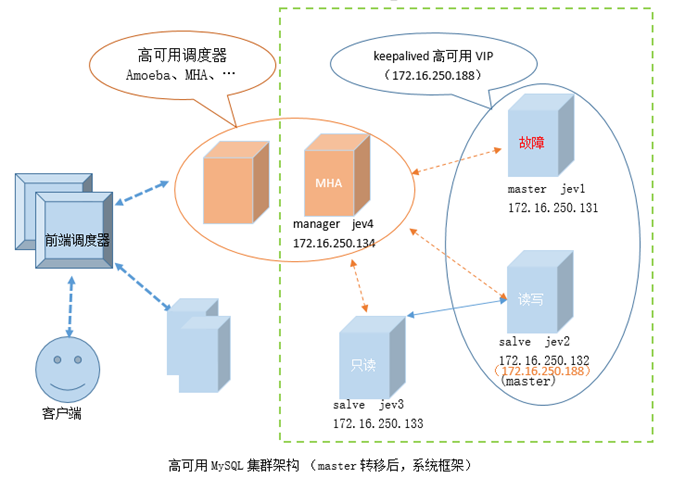

一、恢复背景
1、设备清单
2、:percona-xtrabackup-2.3.2
(注:生产环境应定时备份;不应等到数据库DOWN后才备份,以免加剧集群的压力)
备份数据库操作:
[root@jev72 ~]#innobackupex --user=root --password=centos /data/ 。 。 。 xtrabackup: innodb_log_file_size = 5242880 #注意记录该日志文件大小值 。 。 。
以上为故障前,数据库备份操作,这里写出来是为了便于说明后面调节日志大小操作;
二、修复故障节点及MHA集群
1、恢复前备份文件准备:
将备份文件拷贝到jev1(故障master)上:
[root@jev72 ~]#scp -r /data/2017-02-27_21-23-44 172.16.250.131:/data/
模拟生产环境,在备份后,对数据库进行写操作:
[root@jev6 ~]#mysql -umhaadmin -h172.16.250.188 -pmhapass mysql> show databases ; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | | test2 | +--------------------+ 5 rows in set (0.00 sec) #新建test3数据库 mysql> create database test3; Query OK, 1 row affected (0.00 sec)
2、修改日志大小配置,及清空数据库
此处用直接在故障master操作,如果用新主机需要重新搭建系统环境,注意停止mariadb服务;
将日志大小配置为xtrabackup备份时使用的大小5242880
[root@jev71 ~]#vim /etc/my.cnf.d/server.cnf [mysqld] nnodb_log_file_size=5242880 #清空原数据库文件(生成环境,建议先挪走再删除,以防误删) [root@jev71 ~]#rm -rf /var/lib/mysql/
3、恢复数据
[root@jev71 ~]#innobackupex --copy-back /data/2017-02-27_21-23-44/ 。 。 。 170227 22:07:12 completed OK!
4、予mysql权限,启动mariadb,并查看数据库状态
[root@jev71 ~]#chown -R mysql:mysql /var/lib/mysql [root@jev71 ~]#systemctl start mariadb [root@jev71 ~]#mysql MariaDB [(none)]> show databases ; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | | test2 | +--------------------+ 5 rows in set (0.00 sec)
5、查看时二进制文件位置并进行事务回放重写
(注,如果备份点之后服务器的写操作比较少,可以在恢复节点(jev1)直接指定master日志复制位置直接复制(合并到集群),如果期间产生的二进制文件较大,需要先拷贝备份点之后的所有二进制文件,进行日志重写再合并到集群)
[root@jev71 ~]#cat /data/2017-02-27_21-23-44/xtrabackup_binlog_info master-log.000004 245
备份点之后的所有二进制文件拷贝到恢复节点上(jev1)
[root@jev73 ~]#scp /var/lib/mysql/master-log.000004 172.16.250.131:/tmp/
将备份备份点之后的二进制文件保存到文件中(如果是误删的话,需要将其中的误删的语句删除)
[root@jev71 ~]#mysqlbinlog /tmp/master-log.000004 --start-position=245 >/tmp/myqlsbinlog.001 [root@jev71 ~]#mysql #关闭二进制日志; MariaDB [(none)]> set @@session.sql_log_bin=0 ; #事务回放重写 MariaDB [(none)]> source /tmp/myqlsbinlog.001 ;
6、故障节点修复后以slave的身份并入集群;
将/etc/my.cnf.d/repl.cnf配置为slave:
[root@jev71 ~]#vim /etc/my.cnf.d/repl.cnf [mysqld] server-id=1 log-bin=master-log relay-log=relay-log relay_log_purge=0 read_only=1 innodb_file_per_table=1 skip_name_resolve=1 #重启mariadb服务; [root@jev71 ~]#systemctl restart mariadb && systemctl status mariadb
确定二进制文件最后复制位置,查看用于恢复节点(jev1)的二进制日志最后一个end_log_pos 的值,确定复制起点;
[root@jev71 ~]# mysqlbinlog /tmp/master-log.000004 --start-position=245 。 。 。 #170227 21:34:17 server id 2 end_log_pos 415 Query thread_id=39 exec_time=0 error_code 。 。 。 [root@jev71 ~]#mysql #设置复制起点 MariaDB [(none)]> change master to master_host='172.16.250.132',master_user='repluser',master_password='replpass',master_log_file='master-log.000004',master_log_pos=415; #开启从节点复制线程 MariaDB [(none)]> start slave ; #查看slave状态,确保slave工作正常,关键项如下状态为正常; MariaDB [(none)]> show slave status G Slave_IO_State: Waiting for master to send event Slave_IO_Running: Yes Slave_SQL_Running: Yes #再次查看数据库状态 MariaDB [(none)]> show databases ; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | | test2 | | test3 | +--------------------+ 6 rows in set (0.00 sec)
7、manager上查看MHA集群状态
[root@jev74 ~]#masterha_check_repl --conf=/etc/masterha/app1.cnf 。 。 。 172.16.250.132(172.16.250.132:3306) (current master) +--172.16.250.131(172.16.250.131:3306) +--172.16.250.133(172.16.250.133:3306) 。 。 。 MySQL Replication Health is OK.
可以看到修复节点已经成功并入集群;
此时应该对数据库进行一次全库备份(建议在备用master,即刚刚恢复的数据库);
8、配置keepalived,完善MHA集群
启动masterha_manager
[root@jev74 ~]# masterha_manager --conf=/etc/masterha/app1.cnf
配置keepalived;(注,权重需要低于现在运行中的master,并开启抢占模式)
[root@jev71 ~]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id mysql
vrrp_mcast_group4 224.0.88.88
}
vrrp_script chk_mysqld {
script "killall -0 mysqld && exit 0 || exit 1"
interval 1
weight -5
fall 2
}
vrrp_instance VI_1 {
state BACKUP
interface eno16777736
virtual_router_id 8
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass mysqlvipass
}
track_script {
chk_mysqld
}
virtual_ipaddress {
172.16.250.188/16 dev eno16777736 #高可用的VIP地址
}
}
#启动keepalived
[root@jev71 ~]#systemctl start keepalived && systemctl status keepalived
到此MHA集群已经完全修复
三、提升已修复的节点为master
【注意】:下面环节,除非迫不得已,不建议在生产环境做
如果目前主节点一修复节点(就master)的性能相当,那么就没必要将master切换回去;如需切换,只需关闭当前master上mariadb服务,重复MHA自动迁移master(应在业务低谷期进行)
1、确保masterha_manager正常运行
[root@jev74 ~]#masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:6416) is running(0:PING_OK), master:172.16.250.132
2、关闭当前master(jev2)上的mariadb跟keepalived服务,触发masterha_manager进行master转移
[root@jev72 ~]#systemctl stop mariadb && systemctl stop keepalived
3、将(jev2)keepalived的权重降低,比(jev1)
[root@jev72 ~]#vim /etc/keepalived/keepalived.conf
4、重新开启jev2的mariadb进程
[root@jev72 ~]#systemctl start mariadb && systemctl status mariadb
5、此时在manager上检查MHA集群状态的话,会报错提示目前集群有两的非slave节点:
[root@jev74 ~]#masterha_check_repl --conf=/etc/masterha/app1.cnf [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln653] There are 2 non-slave servers! MHA manages at most one non-slave server. Check configurations.
6、配置jev2为slave节点
此时查看新master(jev1)上的二进制日志与从库对比,在relay log文尾的end_log_pos表示最后读到binlog的位置,通过最新的relay_log中的binlog file和end_log_pos位置来对比还有哪些events缺失,以及旧master(jev2)需要重新并入集群的复制起点;
[root@jev72 ~]#mysql MariaDB [(none)]> change master to master_host='172.16.250.131',master_user='repluser',master_password='replpass',master_log_file='master-log.000001',master_log_pos=245; #开启从节点复制线程 MariaDB [(none)]> start slave ; #查看slave状态,确保slave工作正常,关键项如下状态为正常; MariaDB [(none)]> show slave status G Slave_IO_State: Waiting for master to send event Slave_IO_Running: Yes Slave_SQL_Running: Yes
7、此时在manager上检查MHA集群状态,已显示为健康状态:
[root@jev74 ~]#masterha_check_repl --conf=/etc/masterha/app1.cnf 172.16.250.131(172.16.250.131:3306) (current master) +--172.16.250.132(172.16.250.132:3306) +--172.16.250.133(172.16.250.133:3306) MySQL Replication Health is OK.
四、注意事项:
本文试验基于测试环境操作,虽然力求模拟生产环境,但跟生产环境还是有区别的;
对于数据库的VIP高可用,本文为了方便使用keepalived,但生产环境应该用corosync等重量级应用;
生产环境应该在MHA中配置相关VIP转移脚本,进一步确保VIP正常转移;
生产环境中需要将数据跟二进制日志放在独立磁盘上;
每次主从切换后都必须对比二进制文件,确认是否有事务缺失;
每次主从切换,都不能确保没有事务丢失,故在关键业务还需要增加操作日志;
由于MHA集群要求保留足够中继日志,故需要手动定期清理,目前常用的做法为创建软连接再删除;
[root@jev71 ~]#mysqlbinlog /var/lib/mysql/master-log.000001
2.切换之后需要删除手工删除/data/masterha/app1/app1.failover.complete,才能进行第二次测试
(锁定8小时)
MHA工作原理
主库挂了,但是主库的binlog都被全部从库接收,此时会选中应用binlog最全的一台从库作为新的主库,其他从主只需要重新指定一下主库即可(因为此时,所有从库都是一致的,所以只需要重新指定一下从库即可)。
主库挂了,所有的binlog都已经被从库接收了,但是,主库上有几条记录还没有sync到binlog中,所以从库也没有接收到这个event,如果此时做切换,会丢失这个event。此时,如果主库还可以通过ssh访问到,binlog文件可以查看,那么先copy该event到所有的从库上,最后再切换主库。如果使用半同步复制,可以极大的减少此类风险。
主库挂了,从库上有部分从库没有接收到所有的events,选择出最新的slave,从中拷贝其他从所缺少的events。
问题1、
如何确定哪些event没有成功接收。
问题2、
如何让所有从库保持一致。
导致复制问题的原因是因为MySQL采用异步复制,并不保证所有事件被从库接收,对于此类问题的解决方案:
1、Heartbeat + DRBD
代价:额外的被动master,并且不处理任何流量。
性能:为了保证事件被及时写入,innodb_flush_log_at_trx_commit=1,sync_binlog=1. 这样就会导致性能急速下降。
2、MySQL Cluster
真正的高可用,但是只支持InnoDB。
3、Semi_synchronous Replication (5.5+)
半同步复制极大减少了”binlog事件只存在于master上”的风险。保证至少有一台从库接收到了提交的binlog事件。其他的从可能没有接收,但是不影响提交了。
4、Global Transaction ID
由谷歌开发的插件。
MHA的切换步骤
1、从down的主上面获取到binlog事件。
2、确定最新(最全)的从库。
3、分别应用不同的relay log事件到其他从库。
4、应用从主库上获取的binlog事件(发生故障时的事件)。
5、提升一个从库为新的主库(此时从库已经一致)。
6、将其他从库的主库重新指定,同时,自动检测主库故障。
如何确定最近从库以及丢失的events
1、Master_Log_File,Read_Master_Log_Pos 可以确定(从库的IO线程)读取主库的binlog的最新进度。
2、Relay_Log_File,Relay_Log_Pos 确定SQL线程执行本地Relay_Log的最新进度。
3、由于Relay_Log的进度和binlog是不一样的。所以如果只看Relay_Log的信息无法确定执行事件的实际位置,Relay_Master_Log_File,Exec_Master_Log_Pos 本地SQL线程实际上执行binlog位置(用于计算seconds_behind_master)。
4、各个从库之间,比较Master_Log_File,Read_Master_Log_Pos可以确定哪台从库接收到的日志是最完整的。
5、当找出最新最全的从库之后,应用diff到其他从库。
仅仅比较上面2个参数是不够确定具体缺失的events,在relay log中日志开头会指定是读哪个binlog,文尾的end_log_pos表示最后读到binlog的位置。通过对比不同从库上,最新的relay_log中的binlog file和end_log_pos位置来对比还有哪些events缺失(每个at xxx就是一个event)。如果是一个很大的事务,产生了很多日志信息(事务只会保存在一个binlog文件中,但是会出现在2个relay_log中。)面对这种情形,如果只接受到了部分的events信息。从库是不会重做这些relay_log。此时的Master_Log_File,Read_Master_Log_Pos 会指向读取到的binlog的最新位置(这是IO线程负责的),而Relay_Master_Log_File,Exec_Master_Log_Pos只会指向最后执行的commit事务。这样就保证了不会使数据库进入不一致状态。那么在接受到其他从库最新日志的时候,也是完整的执行一次该事务(即使自己的Relay log已经有部分记录了)。
MHA需要考虑的注意事项
1、如果使用mysqlbinlog打开binlog和relaylog,会自动在文本里面添加rollback关键字所以要在日志中清理掉由mysqlbinlog添加的rollback。
ROLLBACK /* added by mysqlbinlog */
2、由于mha默认关闭relay_log_purge。所以要手动定期清理。为了保证在发生故障时,能有足够多的relay log用户恢复,所以不应该自动清理。关闭这个参数之后,SQL线程不会定期清理Relay_log,所以很快会填满磁盘空间。Relay_log没有像binlog一样有自动过期参数expire_logs_days。
定期清理的方式:
set global relay_log_purge=1;
flush logs;/* SQL线程会自动清理多余的Relay_Log_File */
set global relay_log_purge=0;
如果有较大的日志,让SQL线程自动删,会导致SQL线程锁住,从库落后主库。
ln relay-log.* /tmp/archive_dir/
mysql -e”set global relay_log_purge=1;flush logs;set global relay_log_purge=0;”
rm -rf /tmp/archive_dir/* */
这样就不会占用宝贵的SQL线程了。即便如此也不要在所有的从库上同一时间执行一个计划任务(清除Relay_Log),否则会导致没有Relay_Log用户恢复的情形出现。
3、要确定SQL线程是否执行完所有的events。
(1)、等待事物执行。
(2)、select MASTER_POS_WAIT(master_log_file,read_master_log_pos);如果所有从库已经与主库一致了,上面的命令失效,如果只有部分事物日志传送到从库,SQL线程也不会同步到Read_Master_Log_Pos。
(3)、show processlist查看输出。提示:”Has read all relay log;waiting for the slave I/O thread to update it”
(4)、要处理恶意查询,恶意查询:insert into t1 values(0,0,”ROLLBACK”);
(5)、有多个从库时,并行恢复。
(6)、采用ROW FORMAT,对于采用row格式记录的日志,可能出现多个”#at”条目+相同的”end_log_pos”条目。Table_map+Write_rows+STMT_END
故障自动转移的内容
1、检测master failure。
2、Node Fencing(通过干掉故障master 避免脑裂)。
3、更新写入IP(VIP)。
通过脚本完成自动转移,同时在故障发生时要自动调用脚本。
(1)、确保文件和对应的目录存在,SSH互信成功—-避免因为低级错误导致转移失败。
(2)、如果有从库服务器挂掉,或者SQL线程挂掉,或者在8个小时内发生过转移了—-都不再执行故障转移。
如果发生故障:发送邮件报警,停掉新主库上的备份任务,更新内部工具的管理地址(从旧库指向新库)。
MHA工具介绍
在manager上
master_monitor:检测master状态。
master_switch:执行故障转移(手动执行,如果自动则要使用masterha_manager)。
masterha_manager:启动mha,执行mha的管理操作。
在node上
save_binary_logs:复制主库二进制日志。
apply_diff_relay_logs:从最全的slave上生成diff Relay log,应用所有从主库copy来的的binlog中的events。
filter_mysqlbinlog:清理掉有mysqlbinlog工具带来的ROLLBACK events。
purge_relay_logs:在不停止SQL线程的前提下删除Relay_log。
MHA处理案例
master上内核崩溃,10内检查master状态,确定master不可用之后power off,选择新的master,recovery,并行恢复其他从库。
MHA的限制
不支持多级复制 M->M->S。且不支持日志为statment级别(SBR)的load data infile和MySQL5.0以前的版本。
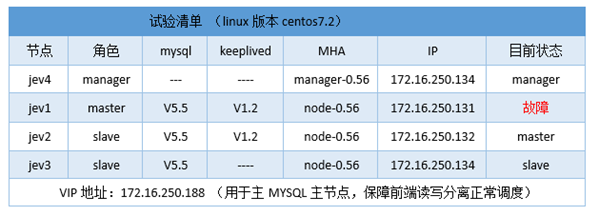
|
试验清单 (linux版本centos7.2) |
||||||
|
节点 |
角色 |
mysql |
keeplived |
MHA |
IP |
目前状态 |
|
jev4 |
manager |
— |
—- |
manager-0.56 |
172.16.250.134 |
manager |
|
jev1 |
master |
V5.5 |
V1.2 |
node-0.56 |
172.16.250.131 |
故障 |
|
jev2 |
slave |
V5.5 |
V1.2 |
node-0.56 |
172.16.250.132 |
master |
|
jev3 |
slave |
V5.5 |
—- |
node-0.56 |
172.16.250.134 |
slave |
|
VIP地址:172.16.250.188 (用于主MYSQL主节点,保障前端读写分离正常调度) |
||||||
2.切换之后需要删除手工删除/data/masterha/app1/app1.failover.complete,才能进行第二次测试
mamy—-从节点没装好:
[root@jev74 ~]#masterha_check_repl –conf=/etc/masterha/app1.cnf
Sun Feb 26 04:44:14 2017 – [warning] Global configuration file /etc/masterha_default.cnf not foun
d. Skipping.Sun Feb 26 04:44:14 2017 – [info] Reading application default configuration from /etc/masterha/ap
p1.cnf..Sun Feb 26 04:44:14 2017 – [info] Reading server configuration from /etc/masterha/app1.cnf..
Sun Feb 26 04:44:14 2017 – [info] MHA::MasterMonitor version 0.56.
Sun Feb 26 04:44:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln193] Ther
e is no alive slave. We can’t do failoverSun Feb 26 04:44:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Erro
r happened on checking configurations. at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 326.Sun Feb 26 04:44:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Erro
r happened on monitoring servers.Sun Feb 26 04:44:14 2017 – [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
从节点没装好:
Sun Feb 26 17:03:13 2017 – [info] Checking SSH publickey authentication settings on the current m
aster..Sun Feb 26 17:03:13 2017 – [info] HealthCheck: SSH to jev71.com is reachable.
Sun Feb 26 17:03:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln122] Got er
ror when getting node version. Error:Sun Feb 26 17:03:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln123]
bash: apply_diff_relay_logs: command not found
Sun Feb 26 17:03:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln132] Fail
ed to get MHA node version on the current master even though current master is reachable via SSH!Sun Feb 26 17:03:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Erro
r happened on checking configurations. at /usr/bin/masterha_check_repl line 48.Sun Feb 26 17:03:14 2017 – [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Erro
r happened on monitoring servers.Sun Feb 26 17:03:14 2017 – [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性,有时候可故意设置从节点慢于主节点,当发生意外删除数据库倒是数据丢失时可从从节点二进制日志中恢复。
[root@jev71 ~]#chown -R mysql:mysql /var/lib/mysql
[root@jev71 ~]#systemctl status mariadb
● mariadb.service – MariaDB database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Mon 2017-02-27 22:11:37 CST; 2min 0s ago
Process: 4831 ExecStartPost=/usr/libexec/mariadb-wait-ready $MAINPID (code=exited, status=1/FAI
LURE) Process: 4830 ExecStart=/usr/bin/mysqld_safe –basedir=/usr (code=exited, status=0/SUCCESS)
Process: 4803 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir %n (code=exited, status=0/SUCCES
S) Main PID: 4830 (code=exited, status=0/SUCCESS)
Feb 27 22:11:35 jev71.com systemd[1]: Starting MariaDB database server…
Feb 27 22:11:36 jev71.com mysqld_safe[4830]: 170227 22:11:36 mysqld_safe Logging to ‘/var/l…g’.
Feb 27 22:11:36 jev71.com mysqld_safe[4830]: 170227 22:11:36 mysqld_safe Starting mysqld da…sql
Feb 27 22:11:37 jev71.com systemd[1]: mariadb.service: control process exited, code=exited …s=1
Feb 27 22:11:37 jev71.com systemd[1]: Failed to start MariaDB database server.
Feb 27 22:11:37 jev71.com systemd[1]: Unit mariadb.service entered failed state.
Feb 27 22:11:37 jev71.com systemd[1]: mariadb.service failed.
Hint: Some lines were ellipsized, use -l to show in full.
[root@jev71 ~]#tail /var/log/mariadb/mariadb.log
170227 22:11:36 InnoDB: Database was not shut down normally!
InnoDB: Starting crash recovery.
InnoDB: Reading tablespace information from the .ibd files…
170227 22:11:36 InnoDB: Operating system error number 13 in a file operation.
InnoDB: The error means mysqld does not have the access rights to
InnoDB: the directory.
InnoDB: File name .
InnoDB: File operation call: ‘opendir’.
InnoDB: Cannot continue operation.
170227 22:11:36 mysqld_safe mysqld from pid file /var/run/mariadb/mariadb.pid ended
[root@jev71 ~]#systemctl stop mariadb
[root@jev71 ~]#systemctl start mariadb
Job for mariadb.service failed because the control process exited with error code. See “systemctl
status mariadb.service” and “journalctl -xe” for details.
删库重装
[root@jev71 ~]#chcon -R -u system_u -r object_r -t mysqld_db_t /var/lib/mysql
source test.sql
ERROR:
ASCII ” appeared in the statement, but this is not allowed unless option
–binary-mode is enabled and mysql is run in non-interactive mode. Set –bin
ary-mode to 1 if ASCII ” is expected. Query: ”.
日格式不对,没有通过mysql
原创文章,作者:Jev Tse,如若转载,请注明出处:http://www.178linux.com/70305
