

本节索引:
一、Elastic Stack介绍
二、核心组件之ElasticSearch
三、核心组件之Logstash
四、核心组件之Kibana
五、核心组件之Filebeat
一、Elastic Stack介绍
官方网站:https://www.elastic.co/products
主要功能:
(1)日志存储和分析
如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁
琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集
汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux
命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的
方法难免有点力不从心。
开源实时日志分析elastic stack平台能够完美的解决我们上述的问题
(2)站内内容搜索
大型搜索引擎需用到实时计算
中小型企业站内搜索不需要实时计算,过去的解决方案一般为:Solr
ElasticSearch出现后,由于其支持弹性搜索引擎,分布式运行,可运行在多个节点上的优势,逐渐占领
了站内搜索领域,Solr解决方案慢慢被淘汰


搜索引擎一般由两部分组成:搜索组件与索引组件
搜索组件:提供用户友好的搜索界面,接入用户搜索信息
索引组件:分析、改造原始数据成为适合搜索引擎搜索的数据结构
早期ELK:核心组成由ElasticSearch、Logstash和Kibana三个开源工具组成
1、Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜
索)
2、ElasticSearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索
引副本机制,restful风格接口,多数据源,自动搜索负载等
3、Kibana也是一个开源和免费的工具,它可以为Logstash和ElasticSearch提供的日志分析友好的Web界
面,可以帮助你汇总、分析和搜索重要数据日志
后期在ELK的基础上加入了filebeat,并且改名为Elastic Stack
Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日
志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者
logstash中存放。
二、核心组件之ElasticSearch
ElasticSearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索
引副本机制,restful风格接口,多数据源,自动搜索负载等
监听端口:
9200:对客户端提供服务
9300:集群内部事务,选举谁是主节点
官网下载:https://www.elastic.co/downloads/past-releases
版本说明:ElasticSearch早期生产环境中由于ELK各核心版本不统一,以2版本居多,5版本之后各组件版
本进行了统一
本文实验均已ELK 5.6.8版本为准
实验:安装ElasticSearch集群
前期准备:
虚拟机3台
node1:192.168.30.10
node2:192.168.30.18
node3:192.168.30.27
具体步骤:
node1,node2,node3端操作:
安装jdk开发环境
yum install java-1.8.0-openjdk-devel -y
下载elasticsearch安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.8.rpm
安装elasticsearch
rpm -ivh elasticsearch-5.6.8.rpm
主要配置文件:
[root@node1 ~]#ls /etc/elasticsearch/
elasticsearch.yml jvm.options log4j2.properties scripts
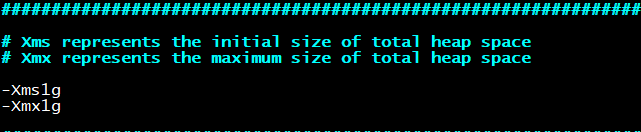
vim jvm.options
-Xms1g #修改初始内存大小
-Xmx1g
vim elasticsearch.yml
—————- Cluster ——————
cluster.name:wxlinux #集群名称,桥接环境下注意修改
————— Network —————–
network.host:本机IP地址
—————– Node ——————–
node.name:node1 or 2 or 3
—————– Paths ——————-
path.data:/myels/data
path.logs:/mysles/logs
————— Discovery —————
discovery.zen.ping.unicast.hosts: [“192.168.30.10”, “192.168.30.18”,”192.168.30.27″]
discovery.zen.minimum_master_nodes: 2
创建数据与日志目录:
mkdir -pv /myels/{data,logs}
chown elasticsearch.elasticsearch /myels/*
启动elasticsearch服务
systemctl start elasticsearch
查看对应端口是否处于监听状态
ss -ntl
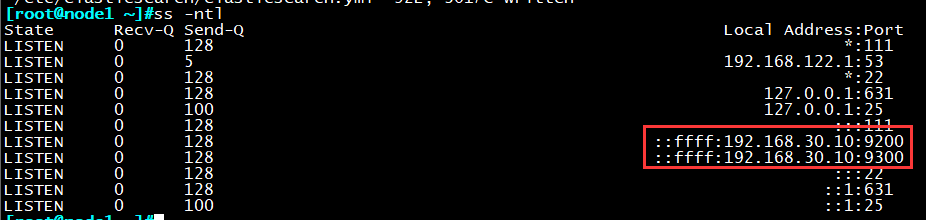
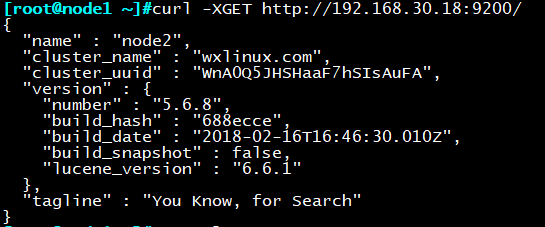
判定集群是否正常启动生效
curl -XGET http://192.168.30.18:9200/
三、核心组件之Logstash
Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜
索)
Logstash有三类插件:
1、输入插件:input,从指定的数据源抽取数据
2、过滤器插件:ouput,在本地进行格式转换
3、输出插件:filter,将处理后的结果保留在指定数据库
官方文档:https://www.elastic.co/guide/en/logstash-versioned-plugins/current/index.html
配置文件:
/etc/logstash.conf
/etc/logstash/conf.d/
注意:logstash配置conf.d目录不要求后缀,任意格式均生效
示例1:安装logstash
yum Install java-1.8.0-openjdk-devel
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.8.rpm
rpm -ivh logstash-5.6.8.rpm
添加到环境变量:
vim /etc/profile.d/logstash.sh
PATH=/usr/share/logstash/bin:$PATH
. /etc/profile.d/logstash.sh
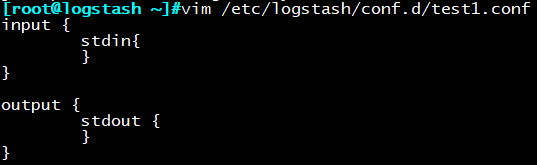
配置测试:
vim test1.conf
语法检查
logstash -f test1.conf -t
加载运行配置
logstash -f test1.conf
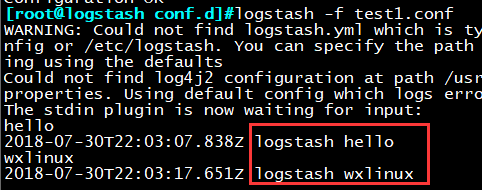
示例2:实现标准输出美观化
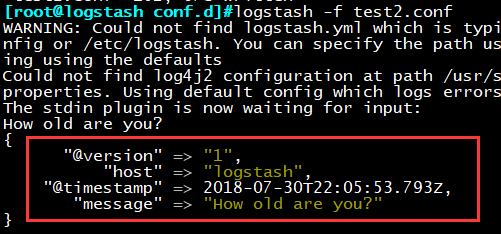
加载运行配置
logstash -f test2.conf
示例3:Logstash实现结构化日志输出
客户端模拟随机IP进行访问,在logstash端创建200个测试页面:
[root@logstash ~]#for i in {1..200};do echo “Test Page $i” > /var/www/html/test$i.html;done
修改http配置文件中的日志格式

[root@client ~]#while true;do client=$[$RANDOM%254+1];curl –header “X-Forwarded-For: 192.30.0.$client” http://192.168.30.10/test$client.html;sleep 1;done

Logstash端:
修改配置文件:
当客户端进行访问时,logstash将日志进行结构化输出
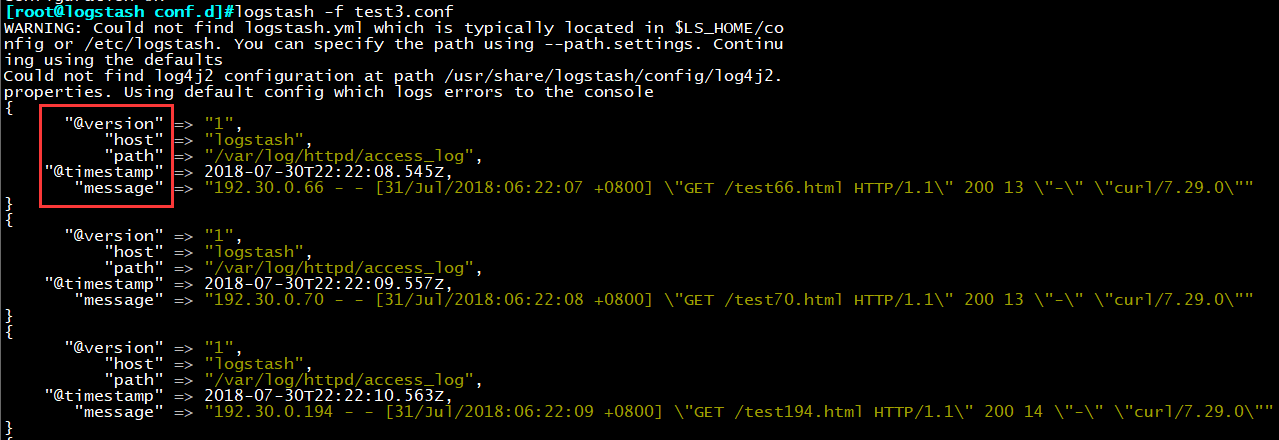
示例4:引入grok过滤器插件
功能:使非结构化日志转化为结构化日志格式
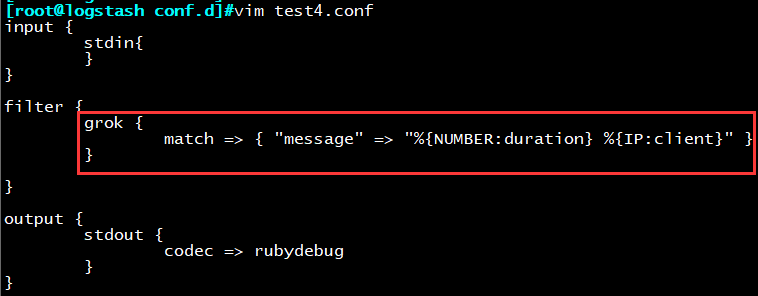
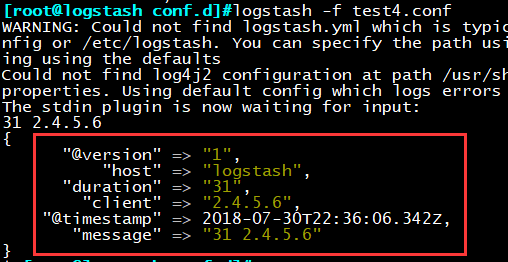
加载运行配置
logstash -f test4.conf
示例5:引用grok内置变量
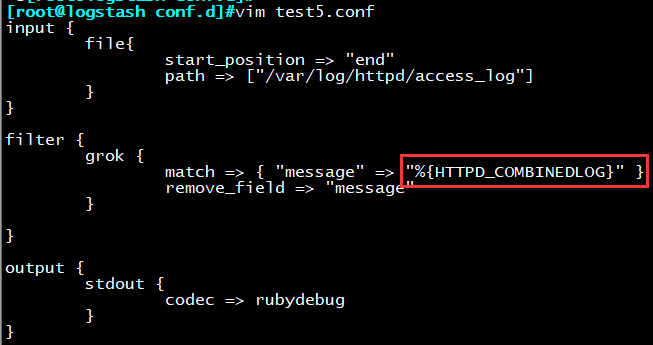
加载运行配置
logstash -f test5.conf
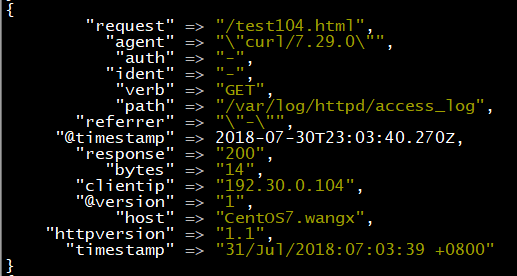
当日志来源有多个时,可加判断语句:

示例6:date filter插件示例
功能:将@timestamp的时间替换为timestamp字段,原@timestamp时间移除
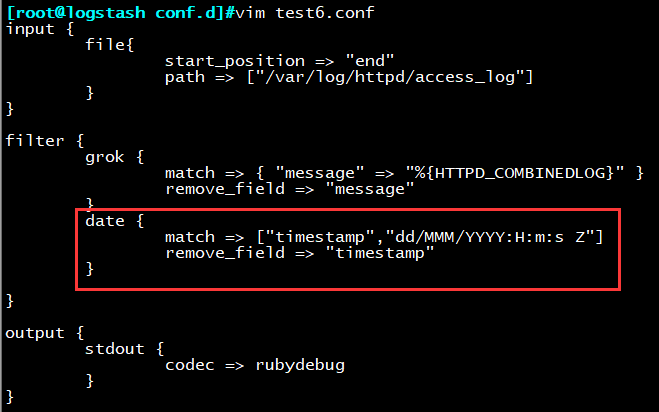
加载运行配置
logstash -f test5.conf
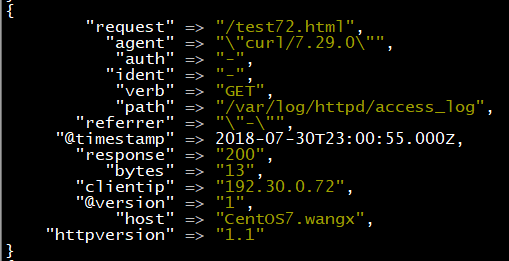
示例7:Geoip插件
功能:根据ip地址定位来自哪个地区或城市
下载IP地址信息库

查看配置

vim test6.conf

加载运行配置
logstash -f test6.conf

四、核心组件之Kibana
Kibana是一个开源和免费的工具,它可以为Logstash和ElasticSearch提供的日志分析友好的Web界面,可
以帮助你汇总、分析和搜索重要数据日志
默认监听5601端口,工作于http协议
示例:安装kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.6.8-x86_64.rpm
rpm -ivh kibana-5.6.8-x86_64.rpm
修改kibana配置文件
vim kibana.conf
server.port:5601
server.host:”0.0.0.0″ #5601监听的本地地址
server.name:”master.wxlinux.com”
elasticsearch.url:”http://node1:9200″
查看5601端口已处于监听状态
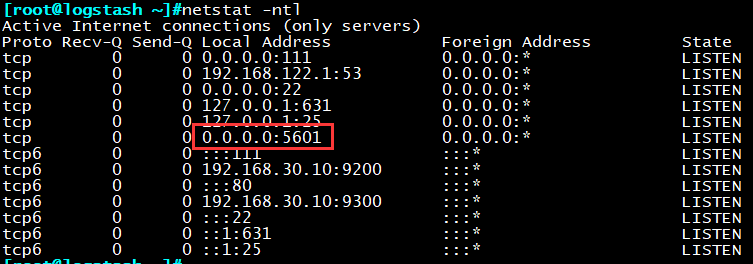
浏览器访问http://localhost:5601
进行一些相关设置即可正常使用
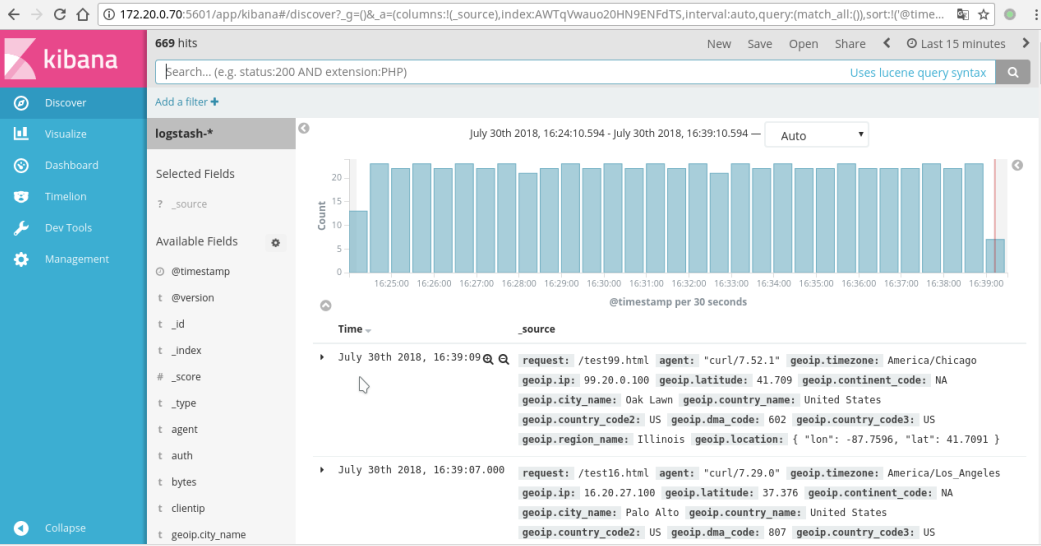
输入关键词可进行搜索
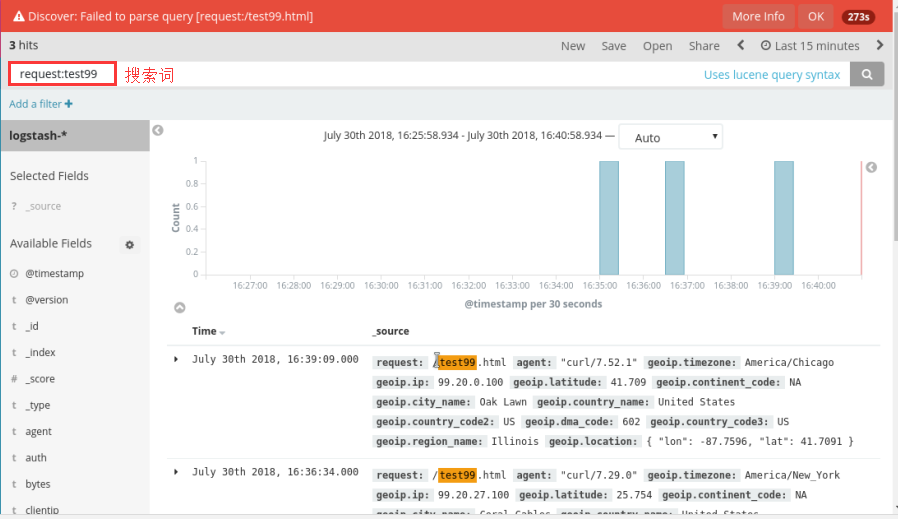
可根据状态码进行范围查询
生成统计表图结构
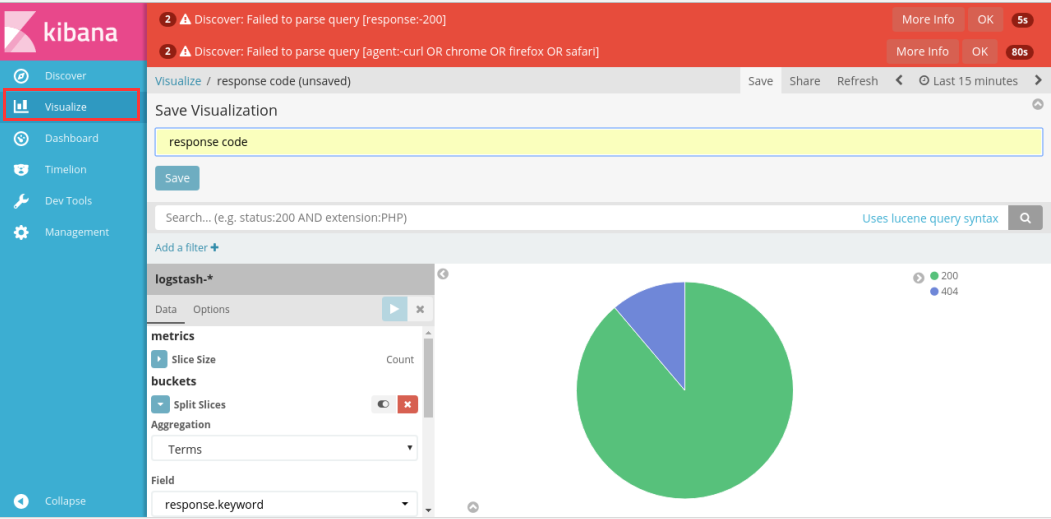
也可根据geoip信息生成位置访问统计
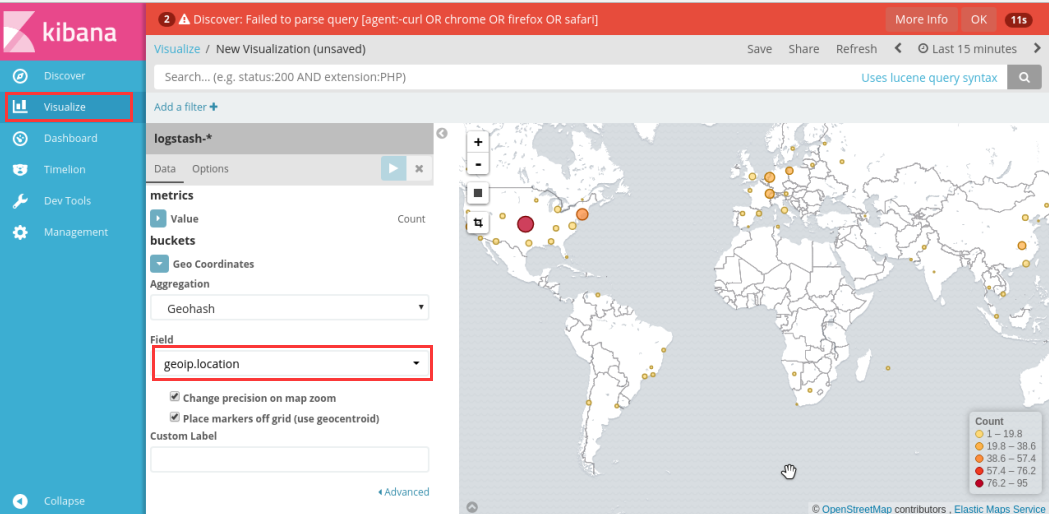
五、核心组件之Filebeat
Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日
志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者
logstash中存放。
早期部署ELK时,需要将Logstatsh安装于每台需要收集日志的服务器上,但由于Logstash属于重量级应
用。为了减少服务器的性能消耗,在filebeat出现后,一般利用filebeat用来替代过去logstash的收集、读取
日志功能,而将logstash分离出来做成集群专门来负责转换格式使用。
官网介绍:轻量级的数据搬用工具

示例:实现由filebeat收集服务器日志,转发给elasticsearch
前期准备:
虚拟机三台
filebeat:192.168.30.10
elasticsearch 1:192.168.30.18
elasticsearch 2:192.168.30.27
其中elasticsearch 1与elasticsearch 2组成一个elasticsearch集群
具体步骤
安装filebeat:
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.8-x86_64.rpm
rpm -ivh filebeat-5.6.8-x86_64.rpm
修改配置文件:
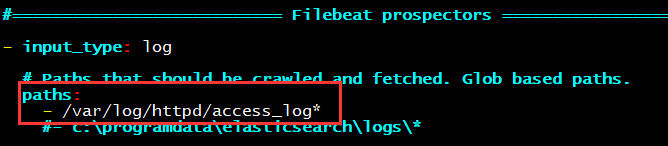
vim /etc/filebeat/filebeat.yml
修改输入类型为log,文件路径为httpd访问日志
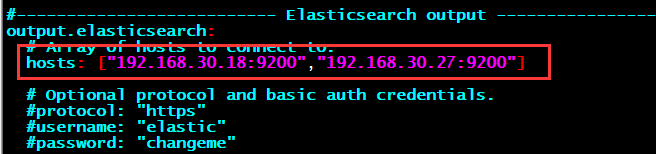
输出到elasticsearch,指定主机IP地址
启动filebeat服务
systemctl start filebeat
查看filebeat文件已在elasticsearch端生成,且不断增加中

本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/104311
