

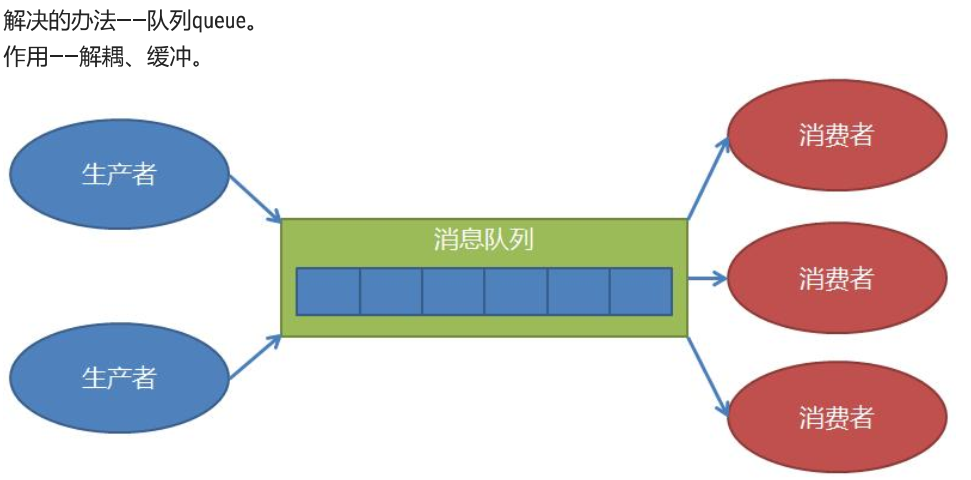

# 日志分析完整代码
import random
import datetime
import time
from queue import Queue
import threading
import re
from pathlib import Path
# 数据源
PATTERN = '''(?P<remote>[\d\.]{7,})\s-\s-\s-[(?P<datetime>[^\[\]]+)]\s\
"(?P<method>.*)\s(?P<url>.*)\s(?P<protocol>.*)"\s\
(?P<status>\d{3})\s(?P<size>\d+)\s"[^"]+"\s"(?P<useragent>[^"]+)"'''
regex = re.compile(PATTERN) # 编译
from user_agents import parse
ops = {
'datetime': lambda datestr: datetime.datetime.strptime(datestr , '%d/%b/%Y:%H:%M:%S %z') ,
'status': int ,
'size': int ,
'useragent': lambda ua: parse(ua)
}
def extract(line: str) -> dict:
matcher = regex.match(line)
if matcher:
return {name: ops.get(name , lambda x: x) for name , data in matcher.groupdict().items()}
# 装载文件
def openfile(path: str):
with open(path) as f:
for line in f:
fields = extract(line)
if fields:
yield fields
else:
continue # TODO 解析失败则抛弃或记录日志
def load(*paths):
for item in paths:
p = Path(item)
if not p.exists():
continue
if p.is_dir():
for file in p.iterdir():
if file.is_file():
yield from openfile(str(file))
elif p.is_file():
yield from openfile(str(p))
# 数据处理
def source(second=1):
"""生成数据"""
while True:
yield {
'datetime': datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=8))) ,
'value': random.randint(1 , 100)
}
time.sleep(second)
# 滑动窗口函数
def window(src: Queue , handler , width: int , interval: int):
"""
窗口函数
:param src: 数据源,缓存队列,用来拿数据
:param handler: 数据处理函数
:param width: 时间窗口宽度,秒
:param interval: 处理时间间隔,秒
"""
start = datetime.datetime.strptime('20170101 000000 +0800' , '%Y%m%d %H%M%S %z')
current = datetime.datetime.strptime('20170101 010000 +0800' , '%Y%m%d %H%M%S %z')
buffer = [] # 窗口中的待计算数据
delta = datetime.timedelta(seconds=width - interval)
while True:
# 从数据源获取数据
data = src.get()
if data:
buffer.append(data) # 存入临时缓冲等待计算
current = data['datetime']
# 每隔interval计算buffer中的数据一次
if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print('{}'.format(ret))
start = current
# 清除超出width的数据
buffer = [x for x in buffer if x['datetime'] > current - delta]
# 随机数平均数测试函数
def handler(iterable):
return sum(map(lambda x: x['value'] , iterable)) / len(iterable)
# 测试函数
def donothing_handler(iterable):
return iterable
# 状态码占比
def status_handler(iterable):
# 时间窗口内的一批数据
status = {}
for item in iterable:
key = item['status']
status[key] = status.get(key , 0) + 1
# total = sum(status.values())
total = len(iterable)
return {k: status[k] / total for k , v in status.items()}
allbrowsers = {}
# 浏览器分析
def browser_handler(iterable):
browsers = {}
for item in iterable:
ua = item['useragent']
key = (ua.browser.family , ua.browser.version_string)
browsers[key] = browsers.get(key , 0) + 1
allbrowsers[key] = allbrowsers.get(key , 0) + 1
print(sorted(allbrowsers.items() , key=lambda x: x[1] , reverse=True)[:10])
return browsers
# 分发器
def dispatcher(src):
# 分发器中记录handler, 同时保存各自的队列
handlers = []
queues = []
def reg(handler , width: int , interval: int):
"""
注册窗口处理函数
:param handler: 注册的数据处理函数
:param width: 时间窗口宽度
:param interval: 时间间隔
"""
q = Queue()
queues.append(q)
h = threading.Thread(target=window , args=(q , handler , width , interval))
handlers.append(h)
def run():
for t in handlers:
t.start() # 启动线程处理数据
for item in src: # 数据源取到的数据分发到所有队列中
for q in queues:
q.put(item)
return reg , run
if __name__ == "__main__":
import sys
# path = sys.argv[1]
path = 'test.log'
reg , run = dispatcher(load(path))
reg(status_handler , 10 , 5) # 注册
reg(browser_handler , 5 , 5)
run() # 运行
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/97752
