

一、内建函数
id 身份的唯一标示符。返回对象在内存中的地址。
hash () 返回一个对象的哈希值
type 返回对象的类型
类型转换。
输入input()函数
打印print()函数。
len(s)给一个容器返回元素的个数。
Isinstance()判断是 什么类型。 isinstance(‘abc’,str)
Issubclass()判断一个类型是不是一个类型的子类。issubclass(bool,bool)
abs绝对值
max() min()最大值最小值,
round() 四舍六入五取偶。不分正负数。
pow(x,y)x**y次幂函数。
divmod(x,y)等价于 tuple (x//y, x%y) divmod(54321,10000) (5, 4321)
sum(iterable[,start]) 对可迭代对象的所有数值元素求和。sum(range(1,100,2))
chr(i)返回的对应的字符。 chr(97)
ord(c)返回字符对应的数字。 ord(‘a’)
ascii() spr() str()
sorted()立即返回一个新的列表。
recersed(seq)是一个迭代器。翻转。
enumrate(seq,start=0)
迭代一个序列,返回索引数字和元组构成的二元组。
迭代器和取元素,iter(iterable),next()
Iter将一个可迭代对象封装成一个迭代器。
Next对一个迭代器取下一个元素,如果所有人元素都取过了,再次next将会报错,但是加上一个缺省值就不会报错。it=iter(reversed([1,3,5]))
next(it,100)
可迭代对象,能够通过迭代一次次返回不同的元素的对象。
所谓相同,不是指值是否相同,而是在元素的容器中是否是同一个。可以迭代,但是未必有序,未必可索引。
可迭代的对象有list、tuple,string,bytes,bytearray,range,set,dict,生成器等。
可以使用成员操作符in not in in本质上就是在遍历对象。3 in range(10) 3 in (x for x in range(10))
迭代器:特殊的对象,一定是可迭代对象,具备可迭代对象的特征。
通过iter方法把一个可迭代对象封装成迭代器。
通过next的方法,迭代迭代器对象。
生成器对象,就是迭代器对象。
zip函数。不是立即生成的。zip(range(10),range(10))
木桶原理。。
二、函数
1、函数,数学定义 y=f(x) y是x的函数,x是自变量。
Python函数:
由若干语句组成的语句块,函数名称,参数列表,组织代码的最小参数。完成一定的功能。
2、函数的作用:
结构化编程对代码的最基本的封装,一般按照功能组织一段代码。
封装的目的是为了复用,减少冗余代码。
代码更加简洁美丽、可读易懂。
3、函数分类
内建函数:max()
库函数:math() ceil()等
4、函数的定义、调用。
def语句定义函数:
def 函数名(参数列表):
函数体(代码块)
[return 返回值]
函数名就是标示符,命名要求一样。
语句块必须缩进,约定四个空格
Python的函数没有return语句,隐士会返回一个none值。
定义中的参数列表成为形式参数,只是一种符号表达,简称形参。
调用:函数定义,只是声明了一个函数,他不会被执行,需要调用。
调用方式,就是函数名加上小括号,括号内写上参数。
调用时候的参数就是实际参数,是实实在在的传入的值,称为实参。
定义的时候叫做形参。
调用的时候叫做实参
def add(x,y):
result = x+y
return result
out = add(4,5)
print(out)
函数是可调用的对象,利用callable()查询。
调用通过函数名add加两个参数,返回值可使用变量接收。
计算的结果,通过返回值进行返回。
必须加同类型的。复用的。
定义需要在调用前,也就是说调用的时候已经被定义过了,否则会抛出异常的。、
def add(x,y):
result = x+y
return result
out = add(‘a’,’b’)
print(out)
5、函数的参数
1)参数调用时传入的参数要和定义的个数匹配(可变参数除外)。
位置参数
2)def f(x,y)调用时使用 f(1,3)
按照参数的定义位置顺序传入实参。
6、关键字参数def(x,y,z)调用使用f(x=1,y=3,z=5)
使用形参的名字来出入实参的方式,使用了形参的名字,顺序可以定义的顺序不一。
7、传参
f(z=none,y=10,x=[1])
f((1,) z=6,y=4.1 )
要求位置参数必须在关键字参数之前,位置参数的按照位置对应的。
位置在前 关键字在后。
8、函数参数默认值
add()可以使用 默认使用缺省值。
参数默认值(缺省值)
定义时,在形参后跟上一个值
def add(x=4, y=5):
return x+y
测试调用 add(6, 10) 、add(6, y=7) 、add(x=5) 、add()、add(y=7)、 {add(x=5, 6) 、add(y=8,4)不可以的类型。型}
add(x=5, y=6)、add(y=5, x=6)
测试定义后面这样的函数 def add(x=4,y)定义的时候也是不可以的。
作用:参数的默认值可以在未传入足够的实参的时候,对没有给定的参数赋值为默认值
参数非常多的时候,并不需要用户每次都输入所有的参数,简化函数调用
9、函数参数默认值:
#代码例子
def login(host=’192.168.133.128′,port=’8888′,username=’wcl’,password=’wwww’):
print(‘{}:{}@{}/{}’.format(host, port, username, password))
login()
login(‘127.0.0.1’, 80, ‘wcl’, ‘wcl’)
login(‘127.0.0.1′, username=’root’)
login(‘localhost’, port=80,password=’com’)
login(port=80, password=’wcl’, host=’www’)
#打印出来的
192.168.133.128:8888@wcl/wwww
127.0.0.1:80@wcl/wcl
127.0.0.1:8888@root/wwww
localhost:80@wcl/com
www:80@wcl/wcl
最常用的,常见的参数放在前面。
缺省值往往都会使用。
10、可变参数
问题:有多个数没需要累加求和。
def add(nums):
传入的参数是一个,可以是列表,集合或者是元组。
#代码例子
def add(nums):
sum = 0
for i in nums:
sum+=i
return sum
add([1,2,3])
#例子
def add(nums):
sum = 0
for i in nums:
sum+=i
return sum
add((1,2,3))
1)可变参数:
一个形参可以匹配任意个参数。
位置参数的可变参数:
有多个数,在形参前面使用*标示该形参是可变参数,可以接收多个实参。
收集多个实参为一个tuple
没有return的返回的是一个值none。
#代码示例
def add(*nums):
sum =0
for i in nums:
sum +=i
print(sum)
add(3,5,6)
14
2)关键字参数的可变参数。
形参前使用**符号,表示可以接手多个关键字参数。
收集 的实参名称和值组成一个字典。
不带*号的往前放,*号多的放后面。
#代码例子
def showconfig(**kwargs):
for k,v in kwargs.items():
print(‘{}={}’.format(k,v))
showconfig(host=’192.168.133.128′,port=’8888′,usrname=’root’,passeord=’wwww’)
#打印出的结果;
host=192.168.133.128
passeord=wwww
usrname=root
port=8888
#位置参数和关键字参数混合
def showconfig(nsername,*args,**kwsrgs):
#def showconfig(x,y,*args,**kwargs):
print(x)
print(y)
print(args)
print(kwargs)
showconfig(3,4,6,7,8,a=1,b=’python’)
#打印
3
4
(6, 7, 8)
{‘b’: ‘python’, ‘a’: 1}
11、可变参数的总结
有位置可变参数和关键字可变参数。
位置参数在可变参数的形参前面使用一个*。
关键字可变参数在形参前面使用两个**。
位置可变参数和关键字,都可以收集如干个实参,位置参数收集形成一个tuple 关键字参数收集形成一个dict。
混合使用参数的时候,可变参数要放到参数列表的最后,普通参数需要放到参数列表前面,位置可变参数需要在关键字可变参数
12、keyword-only参数
如果在一个星号参数后,或者一个位置可变参数后,出现的普通参数,实际上已经不是普通的参数了,而是keyword-only参数.
#例子
def fn(*args,x):
print(x)
print(args)
fn(3,5,x=7)
13、def fn(*,x,y):
*号之后,普通形参都(变成了关键字参数,不在是位置参数了)。都必须给出keyword-noly。
只有可变的才可以给0个,不可变对的必须给定其值。
14、def可变参数和默认值。
#例子
def fn(*args,x=5):
print(x)
print(args)
fn(1,12,4,x=3)
15、参数规则
参数列表参数一般顺序是:普通参数、缺省参数,可变位置参数,keyword-only参数(可带缺省值),可变关键字参数。
#代码示例
def fn(x,y,z=3,*arg,m=4,n,**kwargs):
print(x,y,z,m,n)
print(args)
print(kwargs)
fn(1,2,n=3)
16、参数解构
不仅可以解构数据类型,还可以解构可迭代对象。
给函数提供实参的时候,可以在集合类型前面使用*或者**。
非字典类型使用*
字典类型使用**
提出出来的元素数目要和形参需要的参数一致。
#代码练习
def add(x,y,*args):
return x+y
add(*[1,2,3,4,5])
#代码练习
def add(x,y,*args):
return x+y
add(**{‘x’:3,’y’:5})
#结构字典
d1={‘x’:3,’y’:5}
def add(x,y,*args):
return x+y
add(*d1.keys())
#结构字典
d1={‘x’:3,’y’:5}
def add(x,y,*args):
return x+y
add(*d1.values())
传参时候的方式,
结构,配参。
17、python插入式排序。
1)直接插入排序。
直接插入排序原理。
在未排序的序列中,构建一个子排序序列,直至全部数据按照要求排序完成。
将待排序的数,插入到已经排序的序列中合适的位置。
增加一个哨兵,放入待比较值,让他和后面已经排好序的序列比较,插入合适的地方。
2)原理:增加一个哨兵位,每轮比较将待比较数放入。
哨兵依次和待比较的前一个数据比较,大的数靠右移动,找到哨兵中的值插入位置》
每一轮结束后,得到一个从开始到待比较数的位置的一个有序序列。
3)总结
最好情况,正好是升序排列,比较迭代n-1次。
最差情况,正好是降序排列,比较迭代1,2,,…..n-1即n(n-1)/2
使用两层嵌套循环,时间复杂度O(n**2)
稳定排序算法。
使用在小规模数据比较
优化点:
如果比较操作耗时大的话,可以采用二分查找的方式来提高效率。
#代码练习
h5=[5,6,3,7,8,9,1,2,4,0]
nums1=[0]+h5
length=len(nums1)
for i in range(2,length):
nums1[0]=nums1[i]
j=i-1
if nums1[j]>nums1[0]:
while nums1[j]>nums1[0]:
nums1[j+1]=nums1[j]
j-=1
nums1[j+1]=nums1[0]
print(nums1[1:])
18、函数的返回值及作用域
1)里面包含隐式转换。
return只会返回一个。
ruturn 语句的本质也是打断。
#def showplus(x):
print(x)
return x+1
showplus(5)
print会执行语句。
#def showplus(x):
print(x)
return x+1
print(x+1)
后面的print不会执行,遇到return其实就是打断。相当于break。
#def showplus(x):
print(x)
return x+1
return x+2
只有一个返回语句,第一个返回就相当于被打断。
2)总结
使用return语句返回“返回值”
所有函数都有返回值,如果没有return返回语句,返回的是none.
Return 并一定是函数语句块的最后一条语句。
一个函数存在多个return语句,但是只一条可以被执行。没有return语句,返回的none
如果有必要,可以显示调用return none,可以简写为return。
如果函数执行了return语句,函数就会返回返回值,后面的语句就不会被执行。
作用:结束函数调用,返回值。
3)函数的返回值
#def showlist():
return [1,3,5]
返回多个值
函数不能同时返回多个值,return[1,3,5]是指明返回一个列表,是一个列表对象。
return1,3,5看似是多个值,但是隐士的被封装了。
#def showlist():
return 1,3,5
#(1, 3, 5)
X,y,z=shoulist()使用结构提取更方便。
4)函数的嵌套。
函数内可以定义函数。
#def f1():
def f2():
print(‘f2’)
print(‘f1’)
f2()
f1()
#调用f2()的时候就会报错,因为f2()是在内层函数中定义的。
函数有可见范围,这就是作用域概念。
内部函数不能直接被外部使用,会抛出nameError异常。
19、作用域。***
函数内在函数外是找不到的。
外部在内部是可见的。
概念:一个标示符的可见范围,这就是标示符的作用域,一般指的是变量的作用范围。
全局作用域:在整个程序运行环境中都可见。globl
局部作用域:在函数、类等内部可见。局部变量使用范围内不能超过其所在的局部作用域。local.
#def fn1():
x=1
def fn2():
print(x)
fn2()
fn1()
#def f3():
o=65
def f4():
print(‘f4:{}’.format(o))
print(chr(o))
print(‘f3:{}’.format(o))
f4()
f3()
#f3:65
f4:65
A
内部函数o使用外层函数定义的o的值。
#def f3():
o=65
def f4():
o=97
print(‘f4:{}’.format(o))
print(chr(o))
print(‘f3:{}’.format(o))
f4()
f3()
#f3:65
f4:97
a
赋值即定义。
#
x=5
def foo():
x+=1
print(x)
foo()
本地变量x没有被定义,就拿出使用,本地的x只是空的值。
#
x=5
def foo():
y=x+1
print(y)
foo()
本地可以,因为这样的利用的全局变量x。
在小环境中必须重新进行定义的。
20、全局变量global
#例子
x=5
def foo():
global x
x+=1
print(x)
foo()
使用global关键字的变量,将foo内的x声明为使用外部的全局作用域。
#x=5
def foo():
global x
x=10
x+=1
print(x)
foo()
利用global把x定义为了全局变量,但是内部函数在定义x=10是没有作用的。
内部作用域使用x=5之类的赋值语句会重新定义局部变量x。如果利用global 把x一旦声明为全局变量,那么x=5相当于为全局作用域赋值。
global总结
x+=1这种特殊的形式产生错误的原因,先引用后赋值,python是赋值才算定义。才能被引用。
global的使用原则:基本不使用。
外部作用域变量会内部作用域可见,但是也不要在这个内部的局部作用域内直接使用,因为函数的目的就是为了封装。
如果需要外部全局变量,使用函数传参的方式。
21、闭包
自由变量:未在本地作用域中定义的变量,例如定义在内层函数外的外层函数的作用域中的变量。
闭包:就是一个概念,出现在嵌套函数中,指的是内层函数引用到了外层函数的的自自由变量,就是形成了闭包。(内层函数用到了外层函数的自由变量)
#def f1():
c = [0](是一个自由变量)
def f2():
c[0] +=1
return c[0]
return f2
f=f1()
print(f(),f())
print(f())
Python3中可以使用nonlocal来实现闭包
global只是在声明的和最外部的作用。
使用global可以解决,但是这种使用的是全局变量,而不是闭包。
22、nonlocal
使用了nonlocal关键字,将变量标记在上级的局部作用域中定义,但不能不是全局作用域中定义。
#def counter():
count=0
def inc():
nonlocal count (利用nonlocal)
count +=1
return count
return inc
foo = counter()
foo()
foo()
Count是外层函数的局部变量,被内存函数引用。
内部函数使用nonlocal关键字声明变量count在上级作用域中而非在本地中定义。
代码可以运行,并形成闭包。
nonlocal不是全局作用域中的。
23、默认值作用域
#def foo(xyz=[]):
xyz.append(1)
print(xyz)
foo()
foo()
Print(xyz)#只会报错,因为未定义变量xyz。Xyz知识本地变量。
属性,多次打印的数值会变化。
#例子题
def foo (xyz=1):
print(xyz)
foo()
foo()
print(xyz)
Print(xyz)#只会报错,因为未定义变量xyz。Xyz知识本地变量。
为什么第二次打印是list中元素增加呢?
因为函数也是对象,把函数的默认值放在了属性中,这个属性就伴随着这个函数对象整个生命周期。 查看属性:foo._defaults_
函数的地址并没有改变,就是说函数的对象没有变,调用它,他的属性利用元素来保存所有的默认值。Xyz只是默认值的引用类型,引用类型的元素变动,而不是整个元组变动。
#例子。
def foo(xyz=[],u=’abc’,z=123):
xyz.append(1)
return xyz
print(foo(),id(foo))
print(foo.__defaults__)
print(foo(),id(foo))
print(foo.__defaults__)
#out
[1] 140682069694800
([1], ‘abc’, 123)
[1, 1] 140682069694800
([1, 1], ‘abc’, 123)
属性__defaults__中使用元组保存所有位置参数默认值,他不会因为在函数体内使用了他而发生改变。
#例题
def foo(w,u=’abc’,*,z=123,zz=[456]):
u=’xyz’
z=789
zz.append(1)
print(w,u,z,zz)
print(foo.__defaults__)
foo(‘magedu’)
print(foo.__defaults__)
属性__defaults__中使用元组保存所有位置参数默认值。
属性__kwdefaults__中使用字典保存所有keyword-noly参数的默认值。
默认值的作用域
使用可变类型作为默认值,就可以修改这个值。
有些时候有用,有些时候特性不好,有副作用。
改变的话有两种方法。
24、改变特性的两个方式。
第一种方法:使用影子拷贝创建一个新的对象,永远不能改变传入的参数。
函数体内,不改变默认值。
xyz都是传入参数或者默认参数的副本,如就想修改参数,无能为力。
#例题:
def foo (xyz=[],u=’abc’,z=123):
xyz = xyz[:]
xyz.append(1)
print(xyz)
foo()
print(foo.__defaults__)
foo()
print(foo.__defaults__)
foo()
foo([10])
print(foo.__defaults__)
foo([10,5])
print(foo.__defaults__)
第二种方法:通过值得判断就可以灵活的选择创建或者修改传入的对象。(最常用)
很多函数 的定义,都可以看到使用None这个不可变的值作为默认参数,一种惯用方式。
使用不可变类型的默认值
如果使用缺省值None就创建一个列表
如果传入一个列表,就修改这个列表。
#例题
def fn(xyz=None,u=’abc’,z=123):
if xyz is None:
xyz=[]
xyz.append(1)
return xyz
lst = fn()
a=foo(lst)
print(a)
#输出结果
[1, 1]
None
25、函数的销毁
1)全局函数销毁
重新定义同名函数
Del语句删除函数对象
程序结束时
#例题
def foo(xyz=[],u=’abc’,z=123):
xyz.append(1)
return xyz
print(foo(),id(foo),foo.__defaults__)
def foo(xyz=[],u=’abc’,z=123):
xyz.append(1)
return xyz
print(foo(),id(foo),foo.__defaults__)
del foo
print(foo(),id(foo),foo.__defaults__)
2)局部函数销毁
重新在上级作用域中进行定义同名函数。
del删除语句删除函数对象
上级作用域销毁时。
#试题:
def foo(xyz=[],u=’abc’,z=123):
xyz.append(1)
def inner(a=10):
pass
print(inner)
def inner(a=100):
print(xyz)
print(inner)
return inner
bar=foo()
print(id(foo),id(bar),foo.__defaults__,bar.__defaults__)
del bar
print(id(foo),id(bar),foo.__defaults__,bar.__defaults__)
26、树
1)非线性结构,每个元素可以有多个前驱和后继。
2)树是n(n>=0)个元素的集合。
n=0时,称为空树。
树只有一个特殊的没有前驱的元素,称为树的根root。
树中除了根节点外,其余元素只能有一个前驱,可以有零个或者多个后继。
3)递归定义
树T是n(n>=0)个元素的集合,n=0时,称为空树。
有且只有一个特殊元素根,剩余元素都可以被划分为m个互不相交的集合T1、T2、T3、…..、Tm,而每个元素都是树,称为T的子树。
子树也有自己的根。
4)树的概念
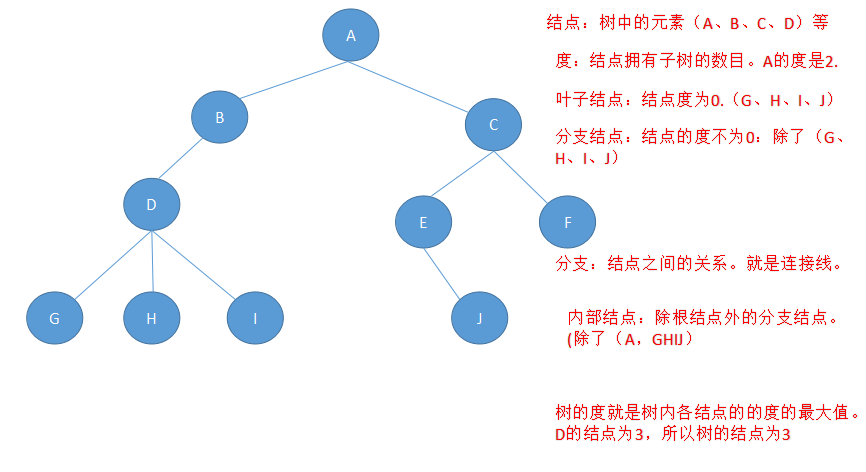
结点:树中的数据元素。
结点的度degree:结点拥有子树的树木称为度。记作d(v)。
叶子结点:结点度为0,称为叶子结点leaf、终端结点、末端结点。
分支结点::结点的度不为0,称为非终端结点或分支结点。
分支:结点之间的关系
内部结点:除了根结点外的分支结点,不包括子结点。
树的度是树内各结点的度的最大值。D的结点度最大为3,树的度数就是3.
孩子结点:结点的子树的根结点成为该结点的孩子。
双亲结点:一个结点是它各子树的根结点的双亲。
兄弟结点:具有相同双亲结点的结点:
祖先结点:祖先结点:从根结点到该结点所经分支上所有的结点。A、B、D都是G的祖先结点。
子孙结点:结点的所有子树上的结点都是该结点的子孙》B的子孙是DGHI
结点的层次:根结点为第一层,根的孩子为第二层,依次类推,记作L(v)
树的深度(高度Depth):树的层次的最大值,上图的树深度为4
堂兄弟:双亲的同一层的结点
有序树:结点的子树是有顺序的(兄弟有大小,有先后次序),不能交换。
无序树:结点的子树是有无序的,可以交换。
路径:树中的k个结点n1、n2、….、nk。满足ni是n(i+1)的双亲,成为你到nk的一条路径。就是一条线串下来的,前一个都是后一个的父(前驱)结点。 路径就是一串从上到下:a到g。
路径长度=路径上的结点树-1,也是分支树。长度就是-1.
森林:m(m》=0)棵不相交的树的集合,对于结点而言,其树的集合就是森林。A的结点的2棵子树的集合就是森林。
5)树的特点
唯一的根
子树不相交
除了根以外。每个元素只能有一个前驱,可以有零个或者多个后继。
根结点就没有双亲结点(前驱),叶子结点没有孩子结点(后继)
Vi是vj的双亲,则L(vi)=L(vi)-1,也就是双亲比孩子结点的层次小1.
堂兄弟的双亲不一定是兄弟关系。

27、二叉树
1)每个结点最多两棵子树。(二叉树不存在度数大于2的结点)
是有序树,左子树,右子树是顺序的,不能交换次序。
即使某个结点只有一个结点,也要确定其为左子树还是右子树。
2)二叉树的五种基本形态。
空二叉树
只有一个根结点
根结点只有左子树
根结点只有右子树
根结点左右都有子树。
3)斜树:
左斜树,所有结点都在左结点。
右斜树,所有结点都在右结点。
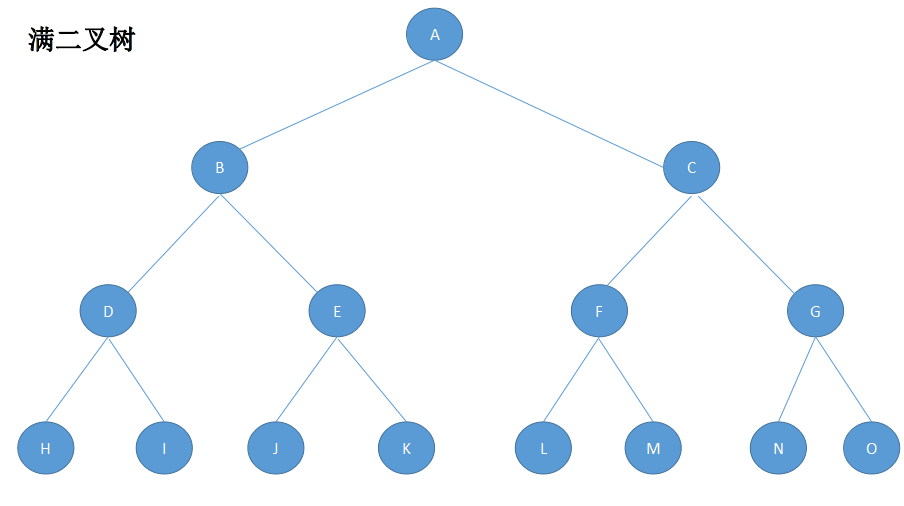
4)满二叉树
一颗二叉树的所有分支结点都存在左子树和右子树,并且所有叶子结点只是存在最下面一层。
K为深度 ,结点总数为(2**k)-1
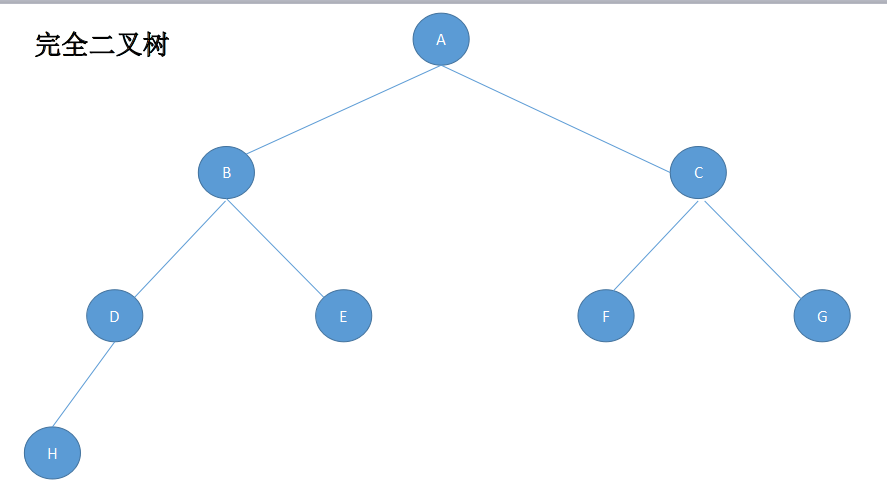
5)完全二叉树:(满二叉树是完全二叉树,但是完全二叉树不一定是满二叉树。)
若二叉树的深度为k,二叉树的层数从1到k-1层的结点树都达到了最大数,在第k层的所有的结点都集中在左边,这就是完全二叉树.
完全二叉树由满二叉树引出.
K为深度(1<=k<=n\),则结点总数的最大值为2**k-1,当达到最大值的时候就是满二叉树.
6)二叉树的性质:
性质1:在二叉树的第i层上至多有2^i -1个结点(i》=1) #例如第二层有两个结点.
性质2:深度为k的二叉树,至多有2**k-1个结点,一层:2-1 二层 4-1=1+2+3 三层8-1=1+2+4=7
性质3:对任何一颗二叉树T,如果其终端结点树为n0,度数为2的结点为n2,则有n0=n2+1(就是叶子树结点的树-1就等于度数为2的结点树.
证明:总结点数n=n1+n2+n3.
一棵树的分支数为n-1,因为除了根结点外。其余结点都有一个分支,n0+n1+n2-1.
分支数还等于n0*0+n1*1+n2*2,n2是2分支结点所以乘以2,2*n2+n1.
可得2*n2+n1=n0+n1+n2-1=>n2=n0-1
7)其它性质:
高度为k的二叉树,至少有k个结点
含有n(n>=1)的结点的二叉树高度至多为n。
含有n(n>=1)的结点树的二叉树的高度至多为n,最小为math.ceil(log2(n+1)),不小于对数值的最小整数, 向上取整。层次树是取整.
如果是8个结点,向上取整为4,为4层.
性质4:具有n个结点的完全二叉树的深度为int(log.n)+1或者math.ceil(log2(n+1))
性质5:如果有一颗n个结点的完全二叉树(深度为性质4),结点按照层序编号.
如果i=1,则结点i是二叉树的根,无双亲,;如果i>1,则双亲是int(i/2),向下取整。就是子结点的编号整除2得到的就是父结点的编号,父结点如果是i,那么左孩子的结点就是2i,右结点是2i+1.
如果2i》n,则结点i无左孩子,即结点为叶子结点,否则其左孩子结点存在编号为2i
如果2i+1》n,则结点i无右孩子,不能说明结点i没有左孩子,否则右孩子的结点存在编号为2i+1.
28、试题练习
#打印三角数字序列
def fn(n):
f1=” “.join([str(i)for i in range(n,0,-1)])
length=len(f1)
for i in range(1,n):
print(‘{:>{}}’.format(” “.join([str(j) for j in range(i,0,-1)]),length))
print(f1)
fn(12)
#打印三角数字序列
def showtail(n):
tail = ” “.join([str(i)for i in range(n,0,-1)])
print(tail)
for i in range(len(tail)):
if tail[i] == ‘ ‘:
print(‘ ‘*i,tail[i+1:])
showtail(12)
#打印输入至少是哪个数字,返回极大值和极小值。
def fn(a,b,*args):
print(max(a,b,*args))
print(min(a,b,*args))
#插入排序
h5=[5,6,3,7,8,9,1,2,4,0]
nums=[0]+h5
length=len(nums)
for i in range(2,length):
nums[0]=nums[i]
j=i-1
if nums[j]>nums[0]:
while nums[j]>nums[0]:
nums[j+1]=nums[j]
j -=1
nums[j+1]=nums[0]
print(nums[1:])
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/96187
