

1. tr命令
tr 转换和删除字符 tr [OPTION]… SET1 [SET2]
选项: -c –C –complement:取字符集的补集(取反的意思)
-d –delete:删除所有属于第一字符集的字符
-s –squeeze-repeats:把连续重复的字符以单独一个字符表示
-t –truncate-set1:将第一个字符集对应字符转化为第二字符集对应的字符.
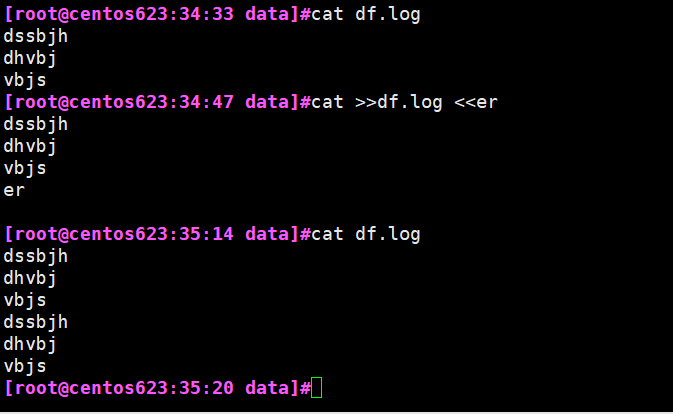
2. 多行重定向需要在后面加个终止符 <<加随意字符即可。
例如 ;cat > fn1 <<dv 中就是以dv为结束符的 ,结束符的前面后面不可加任何东西。

3. 管道命令符
命令1 |命令2 既把前一个的命令标准输出作为命令2的标准输入,错的输出则不可执行。
练习
1、将/etc/issue文件中的内容转换为大写后保存至/tmp/issue.out文件中
2、将当前系统登录用户的信息转换为大写后保存至/tmp/who.out文件中
3、一个linux用户给root发邮件,要求邮件标题为”help”,邮件正文如下: Hello, I am 用户名,The system version is here,please help me to check it ,thanks! 操作系统版本信息
4、将/root/下文件列表,显示成一行,并文件名之间用空格隔开 ( ls /root | tr ‘ \n’ ‘ ‘)
5、计算1+2+3+..+99+100的总和 ( echo {1..100} | tr ‘ ‘ ‘ +’ | bc)
6、删除Windows文本文件中的‘^M’字符 (tr -d ‘\r’ <windown)
7、处理字符串“xt.,l 1 jr#!$mn 2 c*/fe 3 uz 4”,只保留其中的数字和空格 (echo ‘……’ | tr -dc ‘ 0-9’ ‘ ‘ )
8、将PATH变量每个目录显示在独立的一行 (echo $PATH |tr ‘ :’‘ \n’ )
9、将指定文件中0-9分别替代成a-j (tr ‘0-9’ ‘a-j’ )
10、将文件/etc/centos-release中每个单词(由字母组成)显示在独立的一行,并无空行( tr ‘ ‘ ‘\n’ <fn)
4 .用户组和权限
管理员:uid 0
系统用户: uid 1-499 1-999
普通用户: uid 500+ 1000+
组的类别
Linux组的类别
用户的主要组(primary group) 用户必须属于一个且只有一个主组 组名同用户名,且仅包含一个用户,私有组
用户的附加组(supplementary group) 一个用户可以属于零个或多个辅助组
用户和组的配置文件
Linux用户和组的主要配置文件:
/etc/passwd:用户及其属性信息(名称、UID、主组ID等)(用户名,密码,UID,GID,描述信息,家目录路径,shell类型)七个信息。
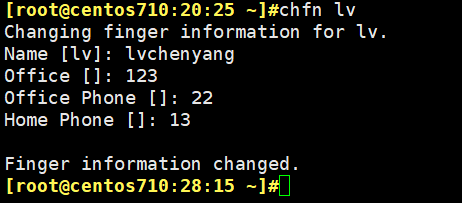
描述信息可用命令修改 chfn lv 例如下图 chsh -s /bin/csh lv 该lv账号的shell类型。
/etc/group:组及其属性信息
/shadow文件格式 登录用名 用户密码:一般用sha512加密 从1970年1月1日起到密码最近一次被更改的时间 密码再过几天可以被变更(0表示随时可被变更) 密码再过几天必须被变更(99999表示永不过期) 密码过期前几天系统提醒用户(默认为一周) 密码过期几天后帐号会被锁定 从1970年1月1日算起,多少天后帐号失效 etc/shadow:用户密码及其相关属性。
立即登陆该口令 即将99999改为0 既命令立即过期了 。用命令 passwd -e lv
/etc/gshadow:组密码及其相关属性
给用户加密码 passwd + 用户名 添加用户useradd +用户名
给组加密码 gpasswd + 组名 组在用户创建时自动生成组
加入其他组 newgrp +组名 然后输入组的密码即可
vipw和vigr 更改用户和组的配置文件的命令
pwck和grpck 用来检查更改后的配置文件的检查
用户创建useradd(只能一次创建一个用户) 组的创建 groupadd
useradd [options] LOGIN -u UID
-o 配合-u 选项,不检查UID的唯一性
-g GID:指明用户所属基本组,可为组名,也可以GID
-c “COMMENT”:用户的注释信息
-d HOME_DIR: 以指定的路径(不存在)为家目录
-s SHELL: 指明用户的默认shell程序 可用列表在/etc/shells文件中 (创建不可交互系统 -s /sbin/nologin)
-G GROUP1[,GROUP2,…]:为用户指明附加组,组须事先存在
-N 不创建私用组做主组,使用users组做主组
-r: 创建系统用户 CentOS 6: ID<500,CentOS 7: ID<1000 -m 创建家目录,用于系统用户
-M 不创建家目录,用于非系统用户
默认值设定:/etc/default/useradd文件中 显示或更改默认设置
useradd -D
useradd –D -s SHELL
useradd –D –b BASE_DIR
useradd –D –g GROUP
批量该口令 首先创建一个文本文档 paa用nano 编辑 将用户名和密码写里面例如 hh:12345 bb:12345 保存
之后用以下命令来更改。cat paa | chpasswd
批量用户创建 newusers +f1 其中f1 文件为/etc/passwd/文件下显示的用户格式才行
用户属性修改
usermod [OPTION] login
-u UID: 新UID -g GID: 新主组
-G GROUP1[,GROUP2,…[,GROUPN]]]:新附加组,原来的附加组将会被覆盖; 若保留原有,则要同时使用-a选项(usermod -G hh lv 将 lv加入hh组中 。 组和用户都必须事先存在的)。如果再加一个则会覆盖,要不想覆盖,需要加-a来完成)或者还有其他两种方法:groupmems -a 用户 -g 组, gpasswd -a 用户 组 ) 想要用户 退出某个已加入的组 可用 usermod -G ” 用户 用空格替换掉原先的组)
-s SHELL:新的默认SHELL
-c ‘COMMENT’:新的注释信息
-d HOME: 新家目录不会自动创建;若要创建新家目录并移动原家数据,同时使 用-m选项
-l login_name: 新的名字;
-L: lock指定用户,在/etc/shadow 密码栏的增加 !
-U: unlock指定用户,将 /etc/shadow 密码栏的 ! 拿掉
-e YYYY-MM-DD: 指明用户账号过期日期
-f INACTIVE: 设定非活动期限
更改和查看组成员
groupmems [options] [action] options:
-g, –group groupname 更改为指定组 (只有root) Actions:
-a, –add username 指定用户加入组
-d, –delete username 从组中删除用户
-p, –purge 从组中清除所有成员
-l, –list 显示组成员列表
groups [OPTION].[USERNAME]… 查看用户所属组列表
查看hh组中的成员 用命令 groupmems -l -g hh 就可以了
查看用户跟那个组 groups +用户
5 。 文件的权限管理设置
文件属性操作
chown 设置文件的所有者 (chown hh txt 把txt的所有者改为hh. 用户应该是已存在的)
chgrp 设置文件的属组信息 (chgrp rpc txt 把txt文件的所有组改为rpc 组也应该是存在的)
chmod u-/+ (rwx) 文件名 chmod 642 文件名 (r=4 w=2 x=1)
g-/+(rwx) 文件名
0-/+(rwx) 文件名 ( -R 递归操作)递归是+X 只是针对目录加执行权限,文件不加 但文件本身有执行权限,就会对其补加齐执行权限。
默认新建的文件及目录权限值计算公式和umask 值有关 直接输入umask 可以看出值。
;然后 文件默认权限 + umask 值= 文件是666 目录是777
当文件算出的值中有奇数 奇数自动加1 即可 要想存住,可保存在 .bashrc 文件里。
例如 umask=则215 则文件默认权限值为666-216=450 奇数加1 为460 ,及 有u=w g=wx o= 空)
目录的权限为777-215=562 则权限值为526 目录不用奇数加1 )
ACL
如果想要除了(u g o )三种人以外的用户设定文件的权限则需要使用ACL权限来实现。
例如 ;想要第四个用户拥有读写的权限 setfacl -m u:第四个用户 :rw fn文件)
ACL执行的顺序 文件所有着,自定义用户,自定义组,其他人。
用getfacl 文件名 可查看文件的第四个用户访问权限。
setfacl -b fn 即删除fn文件的ACL访问控制列表。
设定文件特定属性
chattr +i 不能删除,改名,更改
chattr +a 只能追加内容
lsattr 显示特定属性
三种特殊权限
suid 继承所有者的权限 (及其他两类用户都有所有者的权限)只是应二进制可执行程序上 4+原有的数字表示 及46422. chmod 4622 f1
sgid 继承所有组的权限 2+755 如上文
sticky 粘滞位 当 目录的三个权限为777是则其他人也可操作或删除自己的文件 加上sticky权限后只能自己删除自己的文件了 字母 o+t 数字 1 表示 chmod 1775 f1(只作用于目录)
chattr +i 不能删除,改名,更改
chattr +a 只能追加内容
lsattr 显示特定属性
习题
2、备份/testdir/dir里所有文件的ACL权限到/root/acl.txt中,清除 /testdir/dir中所有ACL权限,最后还原ACL权限
首先创建目录 mkdir -p /testdir/dir 其次创建文件 touch /root/acl.txt
然后备份 getfacl -R /testdir/dir > /root/acl.txt 中去
然后清除权限 setfacl -b /testdir/dir
最后还原权限 setfacl –restore /root/dir
1、在/testdir/dir里创建的新文件自动属于webs组,组apps的成员如: tomcat能对这些新文件有读写权限,组dbs的成员如:mysql只能对新文 件有读权限,其它用户(不属于webs,apps,dbs)不能访问这个文件夹
首先建目录 mkdir -p /tesedir/dir
再依次建三个组 groupadd webs groupadd apps groupadd dbs
再建两个用户 useradd tomcat useradd mysqul
之后将目录所有者更换到webs组中去 chgrp webs /testdir/dir
下一步 设置 目录/testdir/dir的权限 chmod 770 /testdir/dir
之后将tomcat mysqul 添加到组中 usermod -G apps tomcat usermod -G dbs mysql
在后 用ACL权限更改 apps,dbs组的权限 setfacl -m g:apps:rw /testdir/dir setfacl -m g:dbs:r /testdir/dir
6 . 文本处理工具
1.cat
-E 显示换行符$
-v 显示^M
-T 显示^I即tab
-A = -EvT
-n 输出的结果前显示行号
-b 输出的结果前显示行号,非空行不参与排列
-s 将连续的空行压缩为一行
查看文件可用 more 和less 分页查看
2.sort
-n 按数字排列
-r 倒序排列,默认升序
-t 指定分隔符
-k 指定哪一列
-f 忽略大小写
-u 删除重复行
3.head -n 10 /ect/fstab:输出文件前10行
-c 10 文件名 按字节查看前10个字节
tail -n 10 /ect/fstab:输出文件后10行
-c 10 文件名 :按字节查看后10个字节。
-f 文件名:动态显示,可用来查看日志。
cut
-d 指定分隔符(默认为tab)
-f 取第几列
-c 安字符切割
–output-delimiter=STRING 指定输出的分隔符
paste:合并两个文件同一行号到一行。
-d 指定分隔符
-s 压缩连续的空行成一行
例: paste file1 file2 -d:
练习:(1)利用df,取出分区利用率的最大值,只要数字。
df |tr -s ” ” : |cut -d: -f5 |sort -n |tail -n 1 |cut -d% -f1
(2)列出当前系统中的所有用户的uid
cat /etc/passwd|cut -d: -f1,3 –output-delimiter=的UID是
4.wc:统计工具
-l 只计数行数
-w 只计数单词数
-c 字节
-m 字符
5.uniq
去除连续重复行,往往和sort配合使用,先排序,再去重
-c 显示重复的次数
-d 仅显示重复行
-u 仅显示非重复行
head [OPTION]… [FILE]…
-c #: 指定获取前#字节
-n #: 指定获取前#行 -#: 指定行数
tail [OPTION]… [FILE]…
-c #: 指定获取后#字节
-n #: 指定获取后#行 -#:
-f: 跟踪显示文件fd新追加的内容,常用日志监控 相当于 –follow=descriptor
-F: 跟踪文件名,相当于—follow=name –retry
tailf 类似tail –f,当文件不增长时并不访问文件
习题 截取IP地址
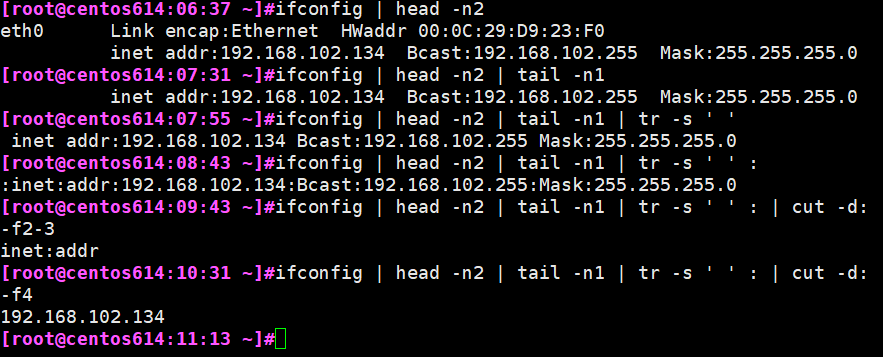
ifconfig | head -n2 | tail -n1 | tr -s ‘ ’ : | cut -d; -f4
对网站访问IP 地址列出前十名
如访问数据在2.log 文件中
cat 2.log | cut -d‘ ’ -f1 | uniq -c | sort -nr | head -n10
思路 截取每一行第一列数据,重复的统计压缩 并显示数字,排序,显示前十行的数据。
查出用户UID最大值的用户名、UID及shell类型
cat /etc/passwd | cut -d: -f1,3,7 | sort -t: -k2 -nr
4、查出/tmp的权限,以数字方式显示
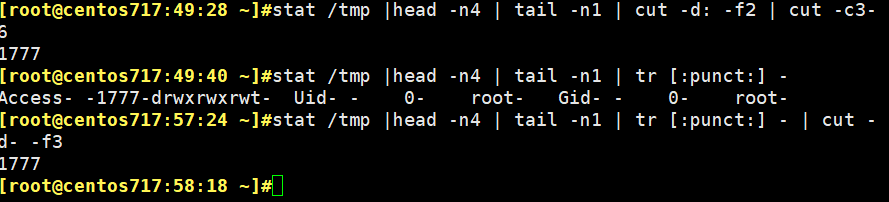
stat -c %a /tmp/ 最简单的方法
5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
netstat -tun | grep ESTAB | tr -s ‘ ‘ : | cut -d: -f6 |sort -nr | uniq -c
7 . 文本过滤工具 grep 和正则表达式
grep命令选项
–color=auto: 对匹配到的文本着色显示
-v: 显示不被pattern匹配到的行
-i: 忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数 (只显示有几行的数)
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-A #: after, 后#行 (例如: -A3 既包含字符串的后面3行)
-B #: before, 前#行 ( 例如 -B2既包含字符串的前面2行)
-C #:context, 前后各#行 (例如;-C4既前后各四行,共计8行的)
-e:实现多个选项间的逻辑or关系 grep –e ‘cat ’ -e ‘dog’ file (-eq -ew -ej 三个是或者的意思)
-w:匹配整个单词 (数字和字母以及下划线是不能区分单词的 ,既他们和字母或下划线及单词可组成一个字符串 例如 123root wer_12q 123_1qw 他们都属于整个单词。)
-E:使用ERE
-F:相当于fgrep,不支持正则表达式
正则表达式
字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次 贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
位置锚定:
定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\> 匹配整个单词
分组:
\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如: \(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这 些变量的命名方式为: \1, \2, \3, …
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(string1\+\(string2\)*\) \1 :string1\+\(string2\)* \2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身 或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
分组 \(asd\) \1 asd为整个字符 1代表和前面括号里一样的字符
习题
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
cat /proc/meminfo | grep -i ^s
2、显示/etc/passwd文件中不以/bin/bash结尾的行
cat /etc/passwd | grep -v “/bin/bash”$
3、显示用户rpc默认的shell程序
cat /etc/passwd | grep -w ^rpc | cut -d: -f7
4、找出/etc/passwd中的两位或三位数
cat /etc/passwd | grep -ow “[0-9]\{2,3\}
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非 空白字符的行
cat /etc/grub2.cfg | grep ‘^[[:space:]]\+[^[:space:]]’
6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
netstat -tan | grep -w “\<LISTEN\>[[:space:]]*$”
7、显示CentOS7上所有系统用户的用户名和UID
cat /etc/passwd | cut -d: -f1,3 | grep -w “[0-9]\{1,3\}” | sort -t: -k2 -nr |
8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找 出/etc/passwd用户名和shell同名的行 cat /etc/passwd | grep “^\(.*\):.*/\1$”
9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
df | grep /dev/sda |tr -s ‘ ‘ % | cut -d% -f5 |sort -nr | head -n1
正则表达式的分组
分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如: \(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这 些变量的命名方式为: \1, \2, \3, …
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(string1\+\(string2\)*\) \1 :string1\+\(string2\)* \2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
扩展的正则表达是
字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
次数匹配:
*:匹配前面字符任意次
?: 0或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
练习
1、显示三个用户root、mage、wang的UID和默认shell
cat /etc/passwd | grep -Ew “^(root|mage|wang)” | cut -d: -f1,7
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一 个小括号的行
cat /etc/rc.d/init.d/functions | grep “^[[:alnum:]_]\+()”
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
echo /etc/rc.d/init.d/functions |egrep -o “[^/]*/?$”
4、使用egrep取出上面路径的目录名
echo /etc/rc.d/init.d/functions |grep -E “^/.*/\<“
5、统计last命令中以root登录的每个主机IP地址登录次数
6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
[root@centos7 ~]# echo {1..100}| egrep -w [0-9]{1} -o
[root@centos7 ~]# echo {1..100}| egrep -w [1-9][0-9]
[root@centos7 ~]# echo {190..300}| egrep -w 2[0-4][0-9]
[root@centos7 ~]# echo {190..300}| egrep -w 25[0-5]
7、显示ifconfig命令结果中所有IPv4地址
ifconfig |sed -r -n ‘s/^(.*addr:)(.*)(Bcast.*)/\2/p’
ifconfig |egrep -o “\<(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>”
8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复 次数多的排到前面
echo “welcome to magedu linux” | grep -o “[[:alpha:]]” | sort | uniq | tr ‘\n’ ‘ ‘
8.文本编辑工具VIM
vim的三种工作模式 命令模式,编辑模式,扩展模式
1 命令模式 到编辑模式的转换
i: insert, 在光标所在处输入
I:在当前光标所在行的行首输入
a: append, 在光标所在处后面输入
A:在当前光标所在行的行尾输入
o: 在当前光标所在行的下方打开一个新行
O:在当前光标所在行的上方打开一个新行
最好在命令模式中退出保存 从其他模式中回到命令模式按esc键即可在按:可进入扩展模式 推出保存用以下按键来实现
扩展模式: :q 退出 :q! 强制退出,丢弃做出的修改 :wq 保存退出 :x 保存退出
w 写(存)磁盘文件
wq 写入并退出
x 写入并退出
q 退出
q! 不存盘退出,即使更改都将丢失
r filename 读文件内容到当前文件中
w filename 将当前文件内容写入另一个文件
!command 执行命令
命令模式光标跳转
字符间跳转: h: 左 l: 右 j: 下 k: 上
#COMMAND:跳转由#指定的个数的字符
单词间跳转: w:下一个单词的词首 e:当前或下一单词的词尾 b:当前或前一个单词的词首 #COMMAND:由#指定一次跳转的单词数
当前页跳转: H:页首 M:页中间行 L:页底
删除命令:
d: 删除命令,可结合光标跳转字符,实现范围删除
d$: 删除到行尾
d^:删除到非空行首
d0:删除到行首
dw: de: db: #COMMAND
dd: 删除光标所在的行
#dd:多行删除
D:从当前光标位置一直删除到行尾,留空行,等同于
d$ command 读入命令的输出
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/94734
