

一,list
1,列表的一些特性 :
- 一个队列,一个排列整齐的队伍
- 列表内的个体称作元素,由若干元素组成列表
- 元素可以是任意对象(数字、字符串、对象、列表等)
- 列表内元素有顺序,可以使用索引
- 线性的数据结构
- 列表是可变的
2,列表的定义 :
- lst = list()()可以是itertable
- lst = []
3,对列表的一些操作 :
- index(value,[start,[stop]])正负索引(正索引从0开始,负索引从-1开始),索引不可越界,否则回报indexerror
2.列表的索引访问用lst[ ]
3.count(value) 返回列表中匹配value的次数
4.时间复杂度index和count方法都是O(n)
5.随着列表数据规模的增大,而效率下降
6.元素个数查看用len()
7.列表修改 list[] = value 索引不可超界
1.增加元素 append()在尾部增加一个元素,就地修改,列表最常用的操作,时间复杂度是O(1)
2. insert(index, object) -> None
在指定的索引index处插入元素object
返回None就意味着没有新的列表产生,就地修改
时间复杂度是O(n)
索引能超上下界吗?
超越上界,尾部追加
超越下界,头部追加
3.extend(iteratable) -> None
将可迭代对象的元素追加进来,返回None
就地修改
+ -> list
连接操作,将两个列表连接起来
产生新的列表,原列表不变
本质上调用的是__add__()方法
* -> list
重复操作,将本列表元素重复n次,返回新的列表
在此要特别注意的是如果是*list其中还有列表如[1, [2,3 ],4 ]
那么复制的工程中套在其中的列表只会复制地址
4.remove(value) -> None
从左至右查找第一个匹配value的值,移除该元素,返回None
就地修改
效率?O(n)
pop([index]) -> item #常用
不指定索引index,就从列表尾部弹出一个元素
指定索引index,就从索引处弹出一个元素,索引超界抛出 IndexError错误
效率?指定索引的的时间复杂度?不指定索引呢?
clear() -> None
清除列表所有元素,剩下一个空列表
5.reverse() -> None
将列表元素反转,返回None
就地修改
sort(key=None, reverse=False) -> 对列表元素进行排序,就地修改,默认 升序
reverse为True,反转,降序
key一个函数,指定key如何排序
lst.sort(key=functionname)
in
[3,4] in [1, 2, [3,4]]
for x in [1,2,3,4]
- 列表的复制分为 shadowcopy(影子拷贝,又称浅拷贝)
deepcopy(深拷贝)#
copy模块提供了deepcopy
import copy
- 随机数 random模块
randint(a, b) 返回[a, b]之间的整数
2.choice(seq) 从非空序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。random.choice([1,3,5,7])
3.randrange ([start,] sto[,step]) 从指定范围内,按指基数递增的集合中获取一个随机数,基数缺省值random.randrange(1,7,2)
random.shuffle(list) ->None 就地打乱列表元素
4.sample(population, k) 从样本空间或总体(序列或者集合类型)中随机取出k个不同的元素,返回一个新的列表
二,tuple
- 元组和列表的区别 :
- 元组是不可变的
- 元组用()表示
- 命名元组 :
- 帮助文档中,查阅namedtuple,有使用例程namedtuple(typename, field_names, verbose=False,rename=False)
命名元组,返回一个元组的子类,并定义了字段
field_names可以是空白符或逗号分割的字段的字符串,可以是字段的列表
from collections import namedtuple
Point = namedtuple(‘_Point’,[‘x’,’y’]) # Point为返回的类
- 帮助文档中,查阅namedtuple,有使用例程namedtuple(typename, field_names, verbose=False,rename=False)
= Point(11, 22)
Student = namedtuple(‘Student’, ‘name age’)
tom = Student(‘tom’, 20)
jerry = Student(‘jerry’, 18)tom.name
三,字符串(str)
- 使用单引号、双引号、三引号引住的字符序列
- Python3起,字符串就是Unicode类型
- 字符串是不可变对象
- join连接
- “string”.join(iterable) -> str
b)将可迭代对象连接起来,使用string作为分隔符
c)可迭代对象本身元素都是字符串
d)返回一个新字符串 - +连接
拼接起来返回一个新的字符串
- 字符串分割
- (r)split系将字符串按照分隔符分割成若干字符串,并返回列表
- (r)partition系将字符串按照分隔符分割成2段,返回这2段和分隔符的元组
- 字符串大小写
- upper
- lower
- 字符串排版
- title() -> str标题的每个单词都大写
- capitalize() -> str首个单词大写
- center(width[, fillchar]) -> str
width 打印宽度
fillchar 填充的字符 - zfill(width) -> strwidth 打印宽度,居右,左边用0填充
- ljust(width[, fillchar]) -> str 左对齐
- rjust(width[, fillchar]) -> str 右对齐
- 字符串修改
- replace(old, new[, count]) -> str
字符串中找到匹配替换为新子串,返回新字符串
ount表示替换几次,不指定就是全部替换 - strip([chars]) -> str
从字符串两端去除指定的字符集chars中的所有字符
如果chars没有指定,去除两端的空白字符 - find(sub[, start[, end]]) -> int
在指定的区间[start, end),从左至右,查找子串sub。找到返回索引,没找到返回-1 - rfind(sub[, start[, end]]) -> int
在指定的区间[start, end),从右至左,查找子串sub。找到返回索引,没找到返回-1
- replace(old, new[, count]) -> str
10.字符串查找
- index(sub[, start[, end]]) -> int
在指定的区间[start, end),从左至右,查找子串sub。找到返回索引,没找到抛出异常ValueError - rindex(sub[, start[, end]]) -> int
在指定的区间[start, end),从左至右,查找子串sub。找到返回索引,没找到抛出异常ValueError - 时间复杂度
index和count方法都是O(n)
随着列表数据规模的增大,而效率下降 - len(string)
返回字符串的长度,即字符的个数 - count(sub[, start[, end]]) -> int
在指定的区间[start, end),从左至右,统计子串sub出现的次数
- 字符串判断
- endswith(suffix[, start[, end]]) -> bool
在指定的区间[start, end),字符串是否是suffix结尾 - startswith(prefix[, start[, end]]) -> bool
在指定的区间[start, end),字符串是否是prefix开头 - is系列
isalnum() -> bool 是否是字母和数字组成
isalpha() 是否是字母
isdecimal() 是否只包含十进制数字
isdigit() 是否全部数字(0~9)
isidentifier() 是不是字母和下划线开头,其他 都是字母、数字、下划线
islower() 是否都是小写
isupper() 是否全部大写
isspace() 是否只包含空白字符
- endswith(suffix[, start[, end]]) -> bool
- 字符串格式化
- format函数格式字符串语法——Python鼓励使用
“{} {xxx}”.format(*args, **kwargs) -> str
args是位置参数,是一个元组
kwargs是关键字参数,是一个字典
花括号表示占位符
{}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值
{xxx}表示在关键字参数中搜索名称一致的
{{}} 表示打印花括号 - 位置参数
“{}:{}”.format(‘192.168.1.100’,8888),这就是按照位置顺序用位置参数替换前面的格式字符串的占位符中 - 关键字参数或命名参数
“{server} {1}:{0}”.format(8888, ‘192.168.1.100’, server=’Web Server Info : ‘) ,位置参数按照序号匹配,关键字参数按照名词匹配 - 访问元素
“{0[0]}.{0[1]}”.format((‘magedu’,’com’)) - 对象属性访问
from collections import namedtuple
Point = namedtuple(‘Point’,’x y’)
= Point(4,5)
“{{{0.x},{0.y}}}”.format(p) - 对齐
‘{0}*{1}={2:<2}’.format(3,2,2*3)
‘{0}*{1}={2:<02}’.format(3,2,2*3)
‘{0}*{1}={2:>02}’.format(3,2,2*3)
‘{:^30}’.format(‘centered’)
‘{:*^30}’.format(‘centered’) - 进制
“int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}”.format(42)
“int: {0:d}; hex: {0:#x}; oct: {0:#o}; bin: {0:#b}”.format(42)
octets = [192, 168, 0, 1]
‘{:02X}{:02X}{:02X}{:02X}’.format(*octets)
- format函数格式字符串语法——Python鼓励使用
四,bytes和bytearray
- bytes
不可变字节序列
bytearray
字节数组
可变
五,set
- 约定
set 翻译为集合
collection 翻译为集合类型,是一个大概念 - set
可变的、无序的、不重复的元素的集合 - 定义
set() {a,} #注意:{}空的花括号是字典所以空set定义为set() - set的元素要求必须可以hash
目前学过的不可hash的类型有list、set
元素不可以索引
set可以迭代 - add(elem)
增加一个元素到set中
如果元素存在,什么都不做
update(*others)
合并其他元素到set集合中来
参数others必须是可迭代对象
就地修改 - remove(elem)
从set中移除一个元素
元素不存在,抛出KeyError异常。为什么是KeyError?
discard(elem)
从set中移除一个元素
元素不存在,什么都不做
pop() -> item
移除并返回任意的元素。为什么是任意元素?
空集返回KeyError异常
clear()
移除所有元素 - set无法查询修改
- 集合运算符
- 并集 |
- 交集 &
- 差集 –
- 对称差集 ^
- <= 判断set1是否是set2的子集
- <判断set1是否是set2的真子集
- >=判断set1是否是set2的超集
- > 判断set1是否是set2的真超集
六,切片
- 要求 :
a)线性结构
可迭代 for … in
len()可以获取长度
通过下标可以访问
可以切片
b)学过的线性结构
列表、元组、字符串、bytes、bytearray - 切片
通过索引区间访问线性结构的一段数据
sequence[start:stop] 表示返回[start, stop)区间的子序列
支持负索引
start为0,可以省略
stop为末尾,可以省略
超过上界(右边界),就取到末尾;超过下界(左边界),取到开头
start一定要在stop的左边
[:] 表示从头至尾,全部元素被取出,等效于copy()方法
七,封装和结构
- 封装
封装
将多个值使用逗号分割,组合在一起
本质上,返回一个元组,只是省掉了小括号
python特有语法,被很多语言学习和借鉴
t1 = (1,2) # 定义为元组
t2 = 1,2 # 将1和2封装成元组
type(t1)
type(t2) - 封装和解构
举例
a = 4
b = 5
tem= a
a = b
b = temp
等价于
a, b = b, a
上句中,等号右边使用了封装,而左边就使用了解构 - 解构
把线性结构的元素解开,并顺序的赋给其它变量
左边接纳的变量数要和右边解开的元素个数一致
举例
lst = [3, 5]
first, second = lst
print(first, second) - Python3的解构
使用 *变量名 接收,但不能单独使用
被 *变量名 收集后组成一个列表
举例
lst = list(range(1, 101, 2))
head, *mid, tail = lst
*lst2 = lst
*body, tail = lst
head, *tail = lst
head, *m1, *m2, tail = lst
head, *mid, tail = “abcdefghijklmn”
type(mid) - 丢弃变量
这是一个惯例,是一个不成文的约定,不是标准
如果不关心一个变量,就可以定义改变量的名字为_
_是一个合法的标识符,也可以作为一个有效的变量使用,但是定义成下划线就是希望不要被使用,除非你明确的知道这个数据需要使用
八,冒泡法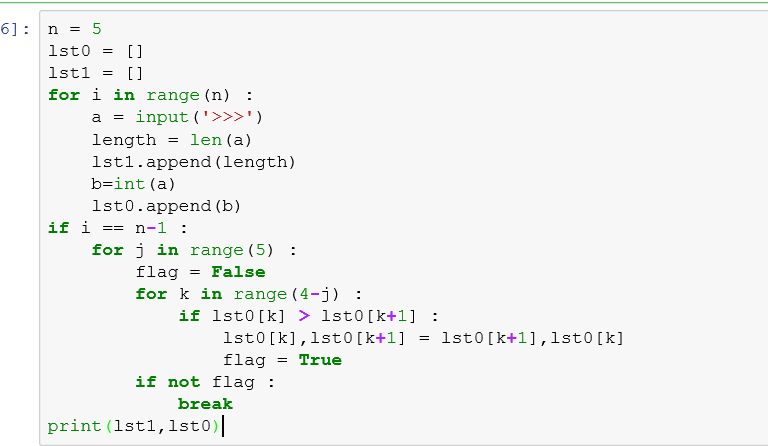

-
注意冒泡法优化的方法以及打标记的位置
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/93875
