

讲完了SSI,ESI,下面就要讲讲CSI了 ,CSI是浏览器端的动静整合方案,当我文章发表后有朋友就问我,CSI技术是不是就是通过ajax来加载数据啊,我当时的回答只是说你的理解有点片面,那么到底什么是CSI技术了?这个其实要和动静资源整合的角度来定义。
CSI技术其实是在页面进行动静分离后,将页面加载分为两个步骤完成,第一步是加载静态资源,静态资源加载完毕后进行第二步骤加载动态资源。不过这个定义还是表述的不全面,不全面的地方就是我们要强调动静分离的目的,我们把页面里的动静资源拆分出来是为了将静态资源做有效的缓存,这个静态资源可能是在静态web容器上,也有可能是在CDN上,也有可能是在浏览器上,不管静态资源是如何缓存的,我们的目的都是为了让静态资源加载的速度更快,如果我们没有让静态资源加载变得高效,就算我们使用了CSI的形式来设计页面,其实也没有发挥CSI的优点,反倒还会一不小心引入CSI的缺点。那什么是CSI的缺点呢?具体如下:
CSI的缺点一:CSI不利于页面的SEO即搜索引擎优化。搜索引擎的网络爬虫一般是根据url访问页面,获取页面的内容后去掉没用的信息例如:css样式,js脚本,然后分析剩下的文本内容,因此假如页面的一部分内容需要进行异步加载,那么这个加载控制肯定是由javascript代码来完成的,因此网络爬虫爬下来的页面里异步加载的操作是没法执行的(听说有些高级的爬虫可以执行异步的操作,抓取异步的内容,即便有这个技术,大部分主流的爬虫还是会忽略掉javascript代码的也会忽略异步加载的内容的),这就会导致爬虫爬的页面里有部分信息丢失了,所以说CSI对SEO不太友好。不过这个缺点我们仔细分析下,可能并不会是那么严重,前面我们谈论了很多静态分离的策略,如果我们动静分离策略做的好,那么动态资源基本都是不能被缓存的内容,经常发生变化的内容,这些变化的内容本来就不需要被网络爬虫爬到,就算真的被爬到,搜索引擎有个查询结果指向了这个页面,我们点开这个页面结果也是在页面找不到被搜索的关键字,这种情形我相信很多朋友在使用搜索引擎时候都会碰到过。不过我想如果开发人员没有正确使用CSI,那么这块他们可能也不会处理的特别好,因此这个缺点还是很容易被引入的。
CSI的缺点二:我们那么费时费力想让自己的网站静态化,目的就是想让页面加载更快点,我们简简单单把页面加载分成了两个步骤进行,那么这么做就真的快吗?这可不一定啊,其实动静分离的做法和我上一个系列里讲到的数据库读写分离有类似之处,数据库读写分离我们是通过拆分原表的读写之间的关联关系,从而达到解决读的瓶颈问题,而网页的动静分离是因为静态资源很容易被优化,所以我们要拆分动静资源。所以当我们对资源进行了动静分离,但是又没有优化静态资源,这个一看就知道我们缺少一个加速页面加载速度的操作,那么真的能让页面加载快点,还真的很难说了,而且异步加载需要执行javascript代码才行,但是静态资源加载时候很容易造成javascript脚本被阻塞,如果阻塞的脚本正好是异步加载的部分,结果只会是比以前加载的更慢了。
由此可见,我在前面讲到的SSI和ESI技术对于我们在浏览器端发挥CSI技术优点是非常有必要的,SSI和ESI做好了能让动静分离出的静态资源加载的更加高效,这也就让CSI操作的第一个步骤变得高效,第一个步骤处理好了我们只要在页面控制好脚本阻塞对异步加载的影响,那么我们就可以达到提升整个页面加载效率的目的了。此外我觉得CSI对SEO有重大影响是个伪命题,假如使用CSI造成了SEO效果不佳,那么肯定是我们CSI方案设计的不到位。
有人认为CSI还会有个缺点,不过笔者我并不认为这是一个缺点,这其实是一个设计问题,好与坏是根据个人的操作习惯所决定的。这个别人认为的缺点是什么呢?它就是使用CSI技术时候,虽然页面很快的被加载出来了,但是动态内容那部分可能会显示一个正在加载的提示,那么这就导致页面用户友好性降低,其实这种同步和异步加载混搭操作实在太常见了,几乎所有大型门户网站,电商网站还有一大堆数不尽的网站都是采用同步和异步混搭的加载方式,假如这些网站不这么做,我相信这些网站例如首页加载一定会慢的让人吐血,因为它们很多网页里面内容实在太多,图片也都有点爆棚了,所以它们不得不使用同步和异步混搭的加载方式,甚至很多静态资源例如图片,flash这些东西也会采取异步加载方式。说到这里,估计有人还是觉得不服气,他就是不喜欢页面加载时候还要出现个正在加载提示,但是网页里又非常需要CSI带来的好处,那么我们该如何解决这个问题呢?这个问题很好解决,首先愿意使用CSI技术也就说明用户还是很愿意使用异步的加载技术的,不喜欢则是正在加载的提示,这说明用户想要在做同步加载操作时候不要掺杂异步操作,虽然现在ajax技术大行其道,但是ajax技术有个同步加载是没有办法解决的,那就是我们在浏览器地址栏里输入网站url请求页面 ,所以面对上面的需求我们只要保证这种同步操作只是一个纯粹的同步操作而不要掺杂异步加载即可,这个方案还是很好实施的,这里我就不再累述了。
动静分离后我们会把静态资源进行缓存,前面文章里讲了一大堆都是在讲服务端的静态资源缓存,现在讲到了CSI已经到了浏览器端,那么我们就得谈谈浏览器的缓存操作。页面的缓存操作就是使用http的expires和cache-control,我们首先看看下面的写法:
<meta http-equiv="pragma" content="no-cache"> <meta http-equiv="cache-control" content="no-cache"> <meta http-equiv="expires" content="0">
这是我现在做的java的web项目里,jsp和vm文件都会使用的meta配置,它的目的就是让页面不要被浏览器缓存,但是如果使用CSI技术,同时动静分离做的很好,那么在页面头部其实我们可以不再这么写了,我们可以让页面在合理的时间范围内被浏览器缓存,如果该页面做了缓存操作,那么以后我们再访问该页面,网页的加载效率就会变得更高了。
这里还有个问题,在雅虎优化网站的建议里,为了充分利用网页并行加载的特点,我们往往会把图片,外部的js和css文件放置在单独的静态web容器或CDN上,那么这些文件往往也是可以被浏览器缓存,这个我们又如何设置才能让浏览器知道要缓存它们呢?这里我们以apache为例,为了让静态资源被浏览器缓存,apache需要使用mod_expires模块,然后在apache的配置文件里添加如下配置:
<FilesMatch "\.(gif|jpg|png|js|css">ExpiresDefault "access plus 10 years"</FilesMatch>
那么浏览器访问此apache上的静态资源后,浏览器就会把图片和该服务器上的js和css文件缓存在浏览器里。
我们看看被缓存的静态资源是如何被使用的,如下图所示:
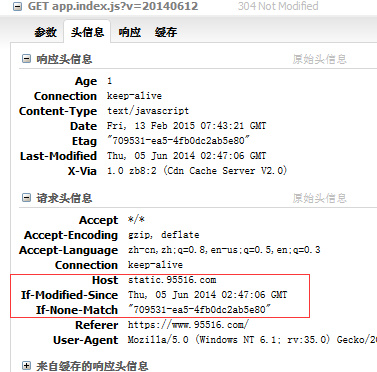

当http的响应码是304的时候,那么浏览器就会从缓存里读取资源了,这里有的朋友可能会感到奇怪为什么缓存的资源还要发送个http请求了?理解这个我们就要了解下缓存的机制,缓存的含义是临时保存某些东西,既然是临时保存,那么就应该有个保存的有效期,我们定义缓存的方式是通过http完成的,那么按道理检查缓存是否过期也应该是http来决定的,因此每次使用缓存时候我们要发个请求到服务端,服务端会检查下资源是否过期了,如果没有过期,服务端返回个304的响应码,304的返回响应是没有http报文体的,所以这个http请求的返回数据是非常小的,因此这个http效率还是很高的,如果服务端发现资源过期了那么服务端就会把新资源返回给浏览器了,其实这个检测资源是否过期的请求有个专有名词叫做条件Get请求。至于服务端是如何完成检查操作,本系列在讲web前端优化时候会详细阐述,这里就不深入了。看到这里估计有朋友又有疑问了,为什么缓存是否过期不能在浏览器端来做了?这主要是浏览器做这个检查非常不准,因为用户的电脑时钟不一定准确,或者用户电脑时钟和服务端不一致,如果再加上时区那么就更加麻烦了,所以缓存失效最好是在服务端进行,这样缓存的有效期的准确性才能得到保证。html5的出现,浏览器缓存的能力大大增强了,不过使用html5技术进行缓存我还没有深入研究过,所以这里也不讲述了,有兴趣的朋友可以自己研究下。
好了,CSI主题内容讲完了,讲到CSI技术和浏览器我们就可以开始本系列另一个重要内容前后端分离了,这将是我下篇的主题,我在自己博客里多次讲到前后端分离,马上又要再次讲了,这次讲是我这么长时间做前后端分离研究的大总结了。
最后,祝大家新年快乐,新的一年喜气洋洋,开开心心哦。
原创文章,作者:stanley,如若转载,请注明出处:http://www.178linux.com/925
