

目录:
一、报表之Excel操作XlsxWriter模块
二、Python与rrdtool的结合模块
三、构建集中式的病毒扫描机制
四、系统批量运维管理器paramiko详解
五、系统批量运维管理器Fabric详解
一、报表之Excel操作XlsxWriter模块
Excel是当今最流行的电子表格处理软件,支持丰富的计算函数及图表,在系统运营方面广泛用于运营数据报表,比如业务质量、资源利用、安全扫描等报表,同时也是应用系统常见的文件导出格式,以便数据使用人员做进一步加工处理。本节主要讲述利用Python操作Excel的模块XlsxWriter(https://xlsxwriter.readthedocs.org),可以操作多个工作表的文字、数字、公式、图表等。XlsxWriter模块具有以下功能:
·100%兼容的Excel XLSX文件,支持Excel 2003、Excel 2007等版本;
·支持所有Excel单元格数据格式;
·单元格合并、批注、自动筛选、丰富多格式字符串等;
·支持工作表PNG、JPEG图像,自定义图表;
·内存优化模式支持写入大文件。
1.XlsxWriter模块的安装方法如下:
# pip install XlsxWriter #pip安装方法 # easy_install XlsxWriter #easy_install安装方法 #源码安装方法 # curl -O -L http://github.com/jmcnamara/XlsxWriter/archive/master.tar.gz # tar zxvf master.tar.gz # cd XlsxWriter-master/ # sudo python setup.py install
下面通过一个简单的功能演示示例,实现插入文字(中英字符)、数字(求和计算)、图片、单元格格式等,代码如下:
【/home/test/XlsxWriter/simple1.py】
#coding: utf-8
import xlsxwriter
workbook = xlsxwriter.Workbook(’demo1.xlsx’) #创建一个Excel文件 worksheet =
workbook.add_worksheet() #创建一个工作表对象
worksheet.set_column(’A:A’, 20) #设定第一列(A)宽度为20像素
bold= workbook.add_format({‘bold’: True}) #定义一个加粗的格式对象
worksheet.write(’A1’, ‘Hello’) #A1单元格写入’Hello’
worksheet.write(’A2’, ‘World’, bold) #A2单元格写入’World’并引用加粗格式对象bold
worksheet.write(’B2’, u’中文测试’, bold) #B2单元格写入中文并引用加粗格式对象bold
worksheet.write(2, 0, 32) #用行列表示法写入数字’32’与’35.5′
worksheet.write(3, 0, 35.5) #行列表示法的单元格下标以0作为起始值,’3,0’等价于’A3’
worksheet.write(4, 0, ‘=SUM(A3:A4)’) #求A3:A4的和,并将结果写入’4,0’,即’A5’
worksheet.insert_image(’B5’, ‘img/python-logo.png’) #在B5单元格插入图片
workbook.close() #关闭Excel文件
程序生成的demo1.xlsx文档截图如图1-1所示。
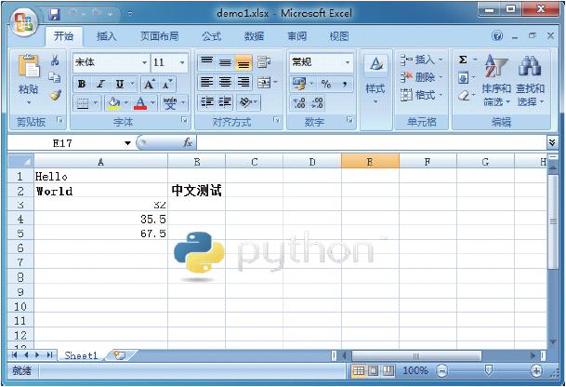
图3-1 demo1.xlsx文档截图
2.模块常用方法说明
2.1Workbook类
Workbook类定义:Workbook(filename[,options]),该类实现创建一个XlsxWriter的Workbook对象。Workbook类代表整个电子表格文件,并且存储在磁盘上。参数filename(String类型)为创建的Excel文件存储路径;参数options(Dict类型)为可选的Workbook参数,一般作为初始化工作表内容格式,例如值为{‘strings_to_numbers’:True}表示使用worksheet.write()方法时激活字符串转换数字。
·add_worksheet([sheetname])方法,作用是添加一个新的工作表,参数sheetname(String类型)为可选的工作表名称,默认为Sheet1。例如,下面的代码对应的效果图如图3-2所示。
worksheet1 = workbook.add_worksheet() # Sheet1 worksheet2 = workbook.add_worksheet('Foglio2') # Foglio2 worksheet3 = workbook.add_worksheet('Data') # Data worksheet4 = workbook.add_worksheet() #Sheet4
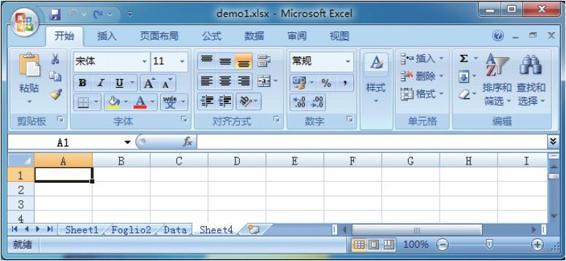
图3-2 添加新工作表
·add_format([properties])方法,作用是在工作表中创建一个新的格式对象来格式化单元格。参数properties(dict类型)为指定一个格式属性的字典,例如设置一个加粗的格式对象,workbook.add_format({‘bold’:True})。通过Format methods(格式化方法)也可以实现格式的设置,等价的设置加粗格式代码如下:
bold = workbook.add_format()
bold.set_bold()
更多格式化方法见http://xlsxwriter.readthedocs.org/working_with_formats.html。
·add_chart(options)方法,作用是在工作表中创建一个图表对象,内部是通过insert_chart()方法来实现,参数options(dict类型)为图表指定一个字典属性,例如设置一个线条类型的图表对象,代码为chart=workbook.add_chart({‘type’:’line’})。
·close()方法,作用是关闭工作表文件,如workbook.close()。
2.2Worksheet类
Worksheet类代表了一个Excel工作表,是XlsxWriter模块操作Excel内容最核心的一个类,例如将数据写入单元格或工作表格式布局等。Worksheet对象不能直接实例化,取而代之的是通过Workbook对象调用add_worksheet()方法来创建。Worksheet类提供了非常丰富的操作Excel内容的方法,其中几个常用的方法如下:
·write(row,col,*args)方法,作用是写普通数据到工作表的单元格,参数row为行坐标,col为列坐标,坐标索引起始值为0;*args无名字参数为数据内容,可以为数字、公式、字符串或格式对象。为了简化不同数据类型的写入过程,write方法已经作为其他更加具体数据类型方法的别名,包括:
·write_string()写入字符串类型数据,如:
worksheet.write_string(0, 0, 'Your text here');
·write_number()写入数字类型数据,如:
worksheet.write_number('A2', 2.3451);
·write_blank()写入空类型数据,如:
worksheet.write('A2', None);
·write_formula()写入公式类型数据,如:
worksheet.write_formula(2, 0, '=SUM(B1:B5)');
·write_datetime()写入日期类型数据,如:
worksheet.write_datetime(7, 0,datetime.datetime.strptime('2013-01-23', '%Y-%m-%d'),workbook.add_format({'num_format': 'yyyy-mm-dd'}));
·write_boolean()写入逻辑类型数据,如:
worksheet.write_boolean(0, 0, True);
·write_url()写入超链接类型数据,如:
worksheet.write_url('A1', 'ftp://www.python.org/')。
下列通过具体的示例来观察别名write方法与数据类型方法的对应关系,代码如下:
worksheet.write(0, 0, 'Hello') # write_string() worksheet.write(1, 0, 'World') # write_string() worksheet.write(2, 0, 2) # write_number() worksheet.write(3, 0, 3.00001) # write_number() worksheet.write(4, 0, '=SIN(PI()/4)') # write_formula() worksheet.write(5, 0, '') # write_blank() worksheet.write(6, 0, None) # write_blank()
上述示例将创建一个如图3-3所示的工作表。
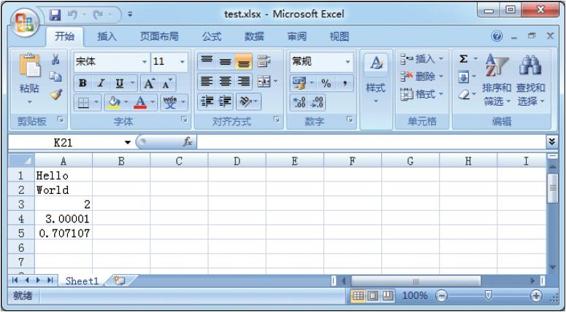
图3-3 创建单元格并写入数据的工作表
·set_row(row,height,cell_format,options)方法,作用是设置行单元格的属性。参数row(int类型)指定行位置,起始下标为0;参数height(float类型)设置行高,单位像素;参数cell_format(format类型)指定格式对象;参数options(dict类型)设置行hidden(隐藏)、level(组合分级)、collapsed(折叠)。操作示例如下:
worksheet.write('A1', 'Hello') #在A1单元格写入'Hello'字符串
cell_format = workbook.add_format({'bold': True}) #定义一个加粗的格式对象
worksheet.set_row(0, 40, cell_format) #设置第1行单元格高度为40像素,且引用加粗 格式对象
worksheet.set_row(1, None, None, {'hidden': True}) #隐藏第2行单元格
上述示例将创建一个如图3-4所示的工作表。
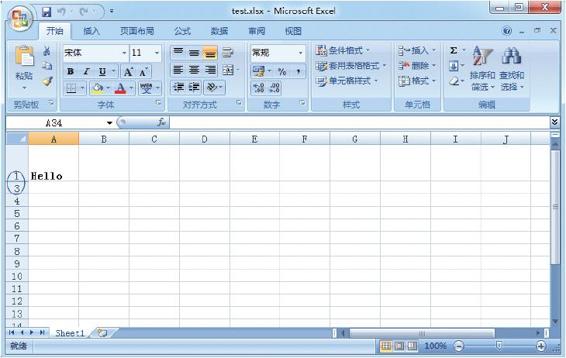
图3-4 设置行单元格属性后的效果
·set_column(first_col,last_col,width,cell_format,options)方法,作用为设置一列或多列单元格属性。参数first_col(int类型)指定开始列位置,起始下标为0;参数last_col(int类型)指定结束列位置,起始下标为0,可以设置成与first_col一样;参数width(float类型)设置列宽;参数cell_format(Format类型)指定格式对象;参数options(dict类型)设置行hidden(隐藏)、level(组合分级)、collapsed(折叠)。操作示例如下:
worksheet.write('A1', 'Hello') #在A1单元格写入'Hello'字符串
worksheet.write('B1', 'World') #在B1单元格写入'World'字符串
cell_format = workbook.add_format({'bold': True}) #定义一个加粗的格式对象设置0到1即(A到B) 列单元格宽度为10像素,且引用加粗格式对象
worksheet.set_column(0,1, 10,cell_format)
worksheet.set_column('C:D', 20) #设置C到D列单元格宽度为20像素
worksheet.set_column('E:G', None, None, {'hidden': 1}) #隐藏E到G列单元格
·insert_image(row,col,image[,options])方法,作用是插入图片到指定单元格,支持PNG、JPEG、BMP等图片格式。参数row为行坐标,col为列坐标,坐标索引起始值为0;参数image(string类型)为图片路径;参数options(dict类型)为可选参数,作用是指定图片的位置、比例、链接URL等信息。操作示例如下:
#在B5单元格插入python-logo.png图片,图片超级链接为http://python.org
worksheet.insert_image('B5', 'img/python-logo.png', {'url': 'http://python.org'})
2.3Chart类
Chart类实现在XlsxWriter模块中图表组件的基类,支持的图表类型包括面积、条形图、柱形图、折线图、饼图、散点图、股票和雷达等,一个图表对象是通过Workbook(工作簿)的add_chart方法创建,通过{type,’图表类型’}字典参数指定图表的类型,语句如下:
chart = workbook.add_chart({type, ‘column’}) #创建一个column(柱形)图表 更多图表类型说明:
·area:创建一个面积样式的图表;
·bar:创建一个条形样式的图表;
·column:创建一个柱形样式的图表;
·line:创建一个线条样式的图表;
·pie:创建一个饼图样式的图表;
·scatter:创建一个散点样式的图表;
·stock:创建一个股票样式的图表;
·radar:创建一个雷达样式的图表。
然后再通过Worksheet(工作表)的insert_chart()方法插入到指定位置,语句如下:
worksheet.insert_chart(’A7’, chart) #在A7单元格插入图表
下面介绍chart类的几个常用方法。
·chart.add_series(options)方法,作用为添加一个数据系列到图表,参数options(dict类型)设置图表系列选项的字典,操作示例如下:
chart.add_series({
'categories': '=Sheet1!$A$1:$A$5',
'values': '=Sheet1!$B$1:$B$5',
'line': {'color': 'red'},
})
add_series方法最常用的三个选项为categories、values、line,其中categories作为是设置图表类别标签范围;values为设置图表数据范围;line为设置图表线条属性,包括颜色、宽度等。
·其他常用方法及示例。
·set_x_axis(options)方法,设置图表X轴选项,示例代码如下,效果图如图3-7所示。
chart.set_x_axis({
'name': 'Earnings per Quarter', #设置X轴标题名称
'name_font': {'size': 14, 'bold': True}, #设置X轴标题字体属性
'num_font': {'italic': True }, #设置X轴数字字体属性
})
图3-7 设置图表X轴选项
·set_size(options)方法,设置图表大小,如chart.set_size({‘width’:720,’height’:576}),其中width为宽度,height为高度。
·set_title(options)方法,设置图表标题,如chart.set_title({‘name’:’Year End Results’}),效果图如图3-8所示。
图3-8 设置图表标题
·set_style(style_id)方法,设置图表样式,style_id为不同数字则代表不同样式,如chart.set_style(37),效果图如图3-9所示。
图3-9 设置图表样式
·set_table(options)方法,设置X轴为数据表格形式,如chart.set_table(),效果图如图3-10所示。
图3-10 设置X轴为数据表格形式
3.实践:定制自动化业务流量报表周报
本次实践通过定制网站5个频道的流量报表周报,通过XlsxWriter模块将流量数据写入Excel文档,同时自动计算各频道周平均流量,再生成数据图表。具体是通过workbook.add_chart({‘type’:’column’})方法指定图表类型为柱形,使用write_row、write_column方法分别以行、列方式写入数据,使用add_format()方法定制表头、表体的显示风格,使用add_series()方法将数据添加到图表,同时使用chart.set_size、set_title、大小及标题属性,最后通过insert_chart方法将图表插入工作表中。我们可以结合2.3节的内容来实现周报的邮件推送,本示例略去此功能。实现的代码如下:
【/home/test/XlsxWriter/simple2.py】
#coding: utf-8
import xlsxwriter
workbook = xlsxwriter.Workbook('chart.xlsx') #创建一个Excel文件 worksheet =
workbook.add_worksheet() #创建一个工作表对象
chart = workbook.add_chart({'type': 'column'}) #创建一个图表对象
#定义数据表头列表
title = [u'业务名称',u'星期一',u'星期二',u'星期三',u'星期四',u'星期五',u'星期六',u'星期日',u'平均流量'] buname= [u'业务官网',u'新闻中心',u'购物频道',u'体育频道',u'亲子频道'] #定义频道名称
#定义5频道一周7天流量数据列表
data = [
[150,152,158,149,155,145,148],
[89,88,95,93,98,100,99],
[201,200,198,175,170,198,195],
[75,77,78,78,74,70,79],
[88,85,87,90,93,88,84],
]
format=workbook.add_format() #定义format格式对象
format.set_border(1) #定义format对象单元格边框加粗(1像素)的格式
format_title=workbook.add_format() #定义format_title格式对象
format_title.set_border(1) #定义format_title对象单元格边框加粗(1像素)的格式
format_title.set_bg_color('#cccccc') #定义format_title对象单元格背景颜色为 #'#cccccc'的格式
format_title.set_align('center') #定义format_title对象单元格居中对齐的格式
format_title.set_bold() #定义format_title对象单元格内容加粗的格式
format_ave=workbook.add_format() #定义format_ave格式对象
format_ave.set_border(1) #定义format_ave对象单元格边框加粗(1像素)的格式
format_ave.set_num_format('0.00') #定义format_ave对象单元格数字类别显示格式
#下面分别以行或列写入方式将标题、业务名称、流量数据写入起初单元格,同时引用不同格式对象
worksheet.write_row('A1',title,format_title)
worksheet.write_column('A2', buname,format)
worksheet.write_row('B2', data[0],format)
worksheet.write_row('B3', data[1],format)
worksheet.write_row('B4', data[2],format)
worksheet.write_row('B5', data[3],format)
worksheet.write_row('B6', data[4],format)
#定义图表数据系列函数
def chart_series(cur_row):
worksheet.write_formula('I'+cur_row, \
'=AVERAGE(B'+cur_row+':H'+cur_row+')',format_ave) #计算(AVERAGE函数)频 道周平均流量
chart.add_series({
'categories': '=Sheet1!$B$1:$H$1', #将“星期一至星期日”作为图表数据标签(X轴)
'values': '=Sheet1!$B$'+cur_row+':$H$'+cur_row, #频道一周所有数据作 为数据区域
'line': {'color': 'black'}, #线条颜色定义为black(黑色)
'name': '=Sheet1!$A$'+cur_row, #引用业务名称为图例项
})
for row in range(2, 7): #数据域以第2~6行进行图表数据系列函数调用
chart_series(str(row))
#chart.set_table() #设置X轴表格格式,本示例不启用
#chart.set_style(30) #设置图表样式,本示例不启用
chart.set_size({'width': 577, 'height': 287}) #设置图表大小
chart.set_title ({'name': u'业务流量周报图表'}) #设置图表(上方)大标题
chart.set_y_axis({'name': 'Mb/s'}) #设置y轴(左侧)小标题
worksheet.insert_chart('A8', chart) #在A8单元格插入图表
workbook.close() #关闭Excel文档
上述示例将创建一个如图3-11所示的工作表。
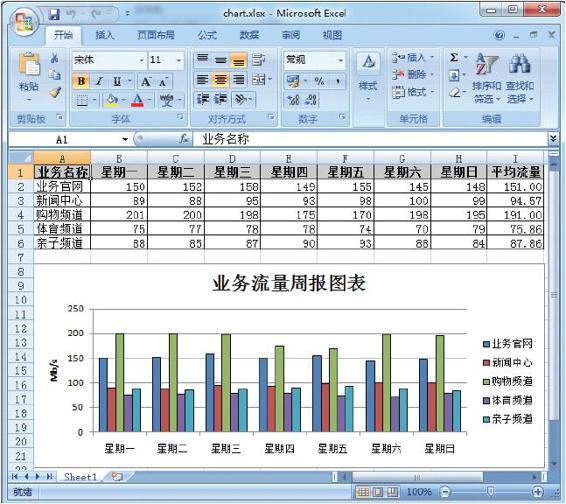
图3-11 业务流量周报图表工作表 参考提示
XlsxWrite模块的常用类与方法说明参考官网http://xlsxwriter.readthedocs.org。
二、Python与rrdtool的结合模块
rrdtool(round robin database)工具为环状数据库的存储格式,round robin是一种处理定量数据以及当前元素指针的技术。rrdtool主要用来跟踪对象的变化情况,生成这些变化的走势图,比如业务的访问流量、系统性能、磁盘利用率等趋势图,很多流行监控平台都使用到rrdtool,比较有名的为Cacti、Ganglia、Monitorix等。更多rrdtool介绍见官网http://oss.oetiker.ch/rrdtool/。rrdtool是一个复杂的工具,涉及较多参数概念,本节主要通过Python的rrdtool模块对rrdtool的几个常用方法进行封装,包括create、fetch、graph、info、update等方法,本节对rrdtool的基本知识不展开说明,重点放在Python rrdtool模块的常用方法使用介绍上。
1.rrdtool模块的安装方法:
easy_install python-rrdtool #pip安装方法
pip install python-rrdtool #easy_install安装方法#需要rrdtool工具及其他类包支持,
CentOS环境推荐使用yum安装方法 # yum install rrdtool-python
2.rrdtool模块常用方法说明
下面介绍rrdtool模块常用的几个方法,包括create(创建rrd)、update(更新rrd)、graph(绘图)、fetch(查询rrd)等。
2.1Create方法create filename[–start|-b start time][–step|-s step][DS:ds-name:DST:heartbeat:min:max][RRA:CF:xff:steps:rows]方法,创建一个后缀为rrd的rrdtool数据库,参数说明如下:
·filename创建的rrdtool数据库文件名,默认后缀为.rrd;
·–start指定rrdtool第一条记录的起始时间,必须是timestamp的格式;
·–step指定rrdtool每隔多长时间就收到一个值,默认为5分钟;
·DS用于定义数据源,用于存放脚本的结果的变量;
·DST用于定义数据源类型,rrdtool支持COUNTER(递增类型)、DERIVE(可递增可递减类型)、ABSOLUTE(假定前一个时间间隔的值为0,再计算平均值)、GUAGE(收到值后直接存入RRA)、COMPUTE(定义一个表达式,引用DS并自动计算出某个值)5种,比如网卡流量属于计数器型,应该选择COUNTER;
·RRA用于指定数据如何存放,我们可以把一个RRA看成一个表,保存不同间隔的统计结果数据,为CF做数据合并提供依据,定义格式为:[RRA:CF:xff:steps:rows];
·CF统计合并数据,支持AVERAGE(平均值)、MAX(最大值)、MIN(最小值)、LAST(最新值)4种方式。
2.2update方法
update filename[–template|-t ds-name[:ds-name]…]N|timestamp:value[:value…][timestamp:value[:value…]…]方法,存储一个新值到rrdtool数据库,updatev和update类似,区别是每次插入后会返回一个状态码,以便了解是否成功(updatev用0表示成功,–1表示失败)。参数说明如下:
·filename指定存储数据到的目标rrd文件名;
·-t ds-name[:ds-name]指定需要更新的DS名称;
·N|Timestamp表示数据采集的时间戳,N表示当前时间戳;
·value[:value…]更新的数据值,多个DS则多个值。
2.3graph方法
graph filename[-s|–start seconds][-e|–end seconds][-x|–x-grid x-axis grid and label][-y|–y-grid y-axis grid and label][–alt-y-grid][–alt-y-mrtg][–alt-autoscale][–alt-autoscale-max][–units-exponent]value[-v|–vertical-label text][-w|–width pixels][-h|–height pixels][-i|–interlaced][-f|–imginfo formatstring][-a|–imgformat GIF|PNG|GD][-B|–background value][-O|–overlay value][-U|–unit value][-z|–lazy][-o|–logarithmic][-u|–upper-limit value][-l|–lower-limit value][-g|–no-legend][-r|–rigid][–step value][-b|–base value][-c|–color COLORTAG#rrggbb][-t|–title title][DEF:vname=rrd:ds-name:CF][CDEF:vname=rpn-expression][PRINT:vname:CF:format][GPRINT:vname:CF:format][COMMENT:text][HRULE:value#rrggbb[:legend]][VRULE:time#rrggbb[:legend]][LINE{1|2|3}:vname[#rrggbb[:legend]]][AREA:vname[#rrggbb[:legend]]][STACK:vname[#rrggbb[:legend]]]方法,根据指定的rrdtool数据库进行绘图,关键参数说明如下:
·filename指定输出图像的文件名,默认是PNG格式;
·–start指定起始时间;·–end指定结束时间;
·–x-grid控制X轴网格线刻度、标签的位置;
·–y-grid控制Y轴网格线刻度、标签的位置;
·–vertical-label指定Y轴的说明文字;
·–width pixels指定图表宽度(像素);
·–height pixels指定图表高度(像素);
·–imgformat指定图像格式(GIF|PNG|GD);
·–background指定图像背景颜色,支持#rrggbb表示法;
·–upper-limit指定Y轴数据值上限;
·–lower-limit指定Y轴数据值下限;
·–no-legend取消图表下方的图例;
·–rigid严格按照upper-limit与lower-limit来绘制;
·–title图表顶部的标题;
·DEF:vname=rrd:ds-name:CF指定绘图用到的数据源;
·CDEF:vname=rpn-expression合并多个值;
·GPRINT:vname:CF:format图表的下方输出最大值、最小值、平均值等;
·COMMENT:text指定图表中输出的一些字符串;
·HRULE:value#rrggbb用于在图表上面绘制水平线;
·VRULE:time#rrggbb用于在图表上面绘制垂直线;
·LINE{1|2|3}:vname使用线条来绘制数据图表,{1|2|3}表示线条的粗细;
·AREA:vname使用面积图来绘制数据图表。
2.4fetch方法
fetch filename CF[–resolution|-r resolution][–start|-s start][–end|-e end]方法,根据指定的rrdtool数据库进行查询,关键参数说明如下:
·filename指定要查询的rrd文件名;
·CF包括AVERAGE、MAX、MIN、LAST,要求必须是建库时RRA中定义的类型,否则会报错;
·–start–end指定查询记录的开始与结束时间,默认可省略。
3.实践:实现网卡流量图表绘制
在日常运营工作当中,观察数据的变化趋势有利于了解我们的服务质量,比如在系统监控方面,网络流量趋势图直接展现了当前网络的吞吐。CPU、内存、磁盘空间利用率趋势则反映了服务器运行健康状态。通过这些数据图表管理员可以提前做好应急预案,对可能存在的风险点做好防范。本次实践通过rrdtool模块实现服务器网卡流量趋势图的绘制,即先通过create方法创建一个rrd数据库,再通过update方法实现数据的写入,最后可以通过graph方法实现图表的绘制,以及提供last、first、info、fetch方法的查询。图3-12为rrd创建到输出图表的过程。
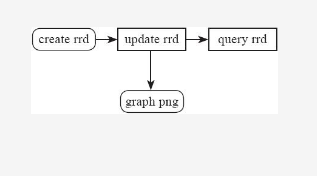
图3-12 创建、更新rrd及输出图表流程
第一步 采用create方法创建rrd数据库,参数指定了一个rrd文件、更新频率step、起始时间–start、数据源DS、数据源类型DST、数据周期定义RRA等,详细源码如下:
【/home/test/rrdtool/create.py】
# -*- coding: utf-8 -*- #!/usr/bin/python import rrdtool import time cur_time=str(int(time.time())) #获取当前Linux时间戳作为rrd起始时间 #数据写频率--step为300秒(即5分钟一个数据点) rrd=rrdtool.create('Flow.rrd','--step','300','--start',cur_time, #定义数据源eth0_in(入流量)、eth0_out(出流量);类型都为COUNTER(递增);600秒为心跳值, #其含义是600秒没有收到值,则会用UNKNOWN代替;0为最小值;最大值用U代替,表示不确定 'DS:eth0_in:COUNTER:600:0:U', 'DS:eth0_out:COUNTER:600:0:U', #RRA定义格式为[RRA:CF:xff:steps:rows], CF定义了AVERAGE、MAX、MIN三种数据合并方式 #xff定义为0.5,表示一个CDP中的PDP值如超过一半值为UNKNOWN,则该CDP的值就被标为UNKNOWN #下列前4个RRA的定义说明如下,其他定义与AVERAGE方式相似,区别是存最大值与最小值 # 每隔5分钟(1*300秒)存一次数据的平均值,600笔,即2.08天 # 每隔30分钟(6*300秒)存一次数据的平均值,存700笔,即14.58天(2周) # 每隔2小时(24*300秒)存一次数据的平均值,存775笔,即64.58天(2个月) # 每隔24小时(288*300秒)存一次数据的平均值,存797笔,即797天(2年) 'RRA:AVERAGE:0.5:1:600', 'RRA:AVERAGE:0.5:6:700', 'RRA:AVERAGE:0.5:24:775', 'RRA:AVERAGE:0.5:288:797', 'RRA:MAX:0.5:1:600', 'RRA:MAX:0.5:6:700', 'RRA:MAX:0.5:24:775', 'RRA:MAX:0.5:444:797', 'RRA:MIN:0.5:1:600', 'RRA:MIN:0.5:6:700', 'RRA:MIN:0.5:24:775', 'RRA:MIN:0.5:444:797') if rrd: print rrdtool.error()
第二步 采用updatev方法更新rrd数据库,参数指定了当前的Linux时间戳,以及指定eth0_in、eth0_out值(当前网卡的出入流量),网卡流量我们通过psutil模块来获取,如psutil.net_io_counters()[1]为入流量。详细源码如下:
【/home/test/rrdtool/update.py】
# -*- coding: utf-8 -*-
#!/usr/bin/python
import rrdtool
import time,psutil
total_input_traffic = psutil.net_io_counters()[1] #获取网卡入流量 total_output_traffic =
psutil.net_io_counters()[0] #获取网卡出流量
starttime=int(time.time()) #获取当前Linux时间戳 #将获取到的三个数据作为updatev的参数,返回{'return_value': 0L}则说明更新成功,反之失败
update=rrdtool.updatev('/home/test/rrdtool/Flow.rrd','%s:%s:%s' % (str(starttime),str(total_input_traffic),str(total_output_traffic)))
print update
将代码加入crontab,并配置5分钟作为采集频率,crontab配置如下:
*/5 * * * * /usr/bin/python /home/test/rrdtool/update.py > /dev/null 2>&1
第三步 采用graph方法绘制图表,此示例中关键参数使用了–x-grid定义X轴网格刻度;DEF指定数据源;使用CDEF合并数据;HRULE绘制水平线(告警线);GPRINT输出最大值、最小值、平均值等。详细源码如下:
【/home/test/rrdtool/graph.py】
# -*- coding: utf-8 -*- #!/usr/bin/python import rrdtool import time #定义图表上方大标题 title="Server network traffic flow ("+time.strftime('%Y-%m-%d', \ time.localtime(time.time()))+")" #重点解释"--x-grid","MINUTE:12:HOUR:1:HOUR:1:0:%H"参数的作用(从左往右进行分解) “MINUTE:12”表示控制每隔12分钟放置一根次要格线 “HOUR:1”表示控制每隔1小时放置一根主要格线 “HOUR:1”表示控制1个小时输出一个label标签 “0:%H”0表示数字对齐格线,%H表示标签以小时显示 rrdtool.graph( "Flow.png", "--start", "-1d","--vertical-label=Bytes/s",\ "--x-grid","MINUTE:12:HOUR:1:HOUR:1:0:%H",\ "--width","650","--height","230","--title",title, "DEF:inoctets=Flow.rrd:eth0_in:AVERAGE", #指定网卡入流量数据源DS及CF "DEF:outoctets=Flow.rrd:eth0_out:AVERAGE", #指定网卡出流量数据源DS及CF "CDEF:total=inoctets,outoctets,+", #通过CDEF合并网卡出入流量,得出总流量total "LINE1:total#FF8833:Total traffic", #以线条方式绘制总流量 "AREA:inoctets#00FF00:In traffic", #以面积方式绘制入流量 "LINE1:outoctets#0000FF:Out traffic", #以线条方式绘制出流量 "HRULE:6144#FF0000:Alarm value\\r", #绘制水平线,作为告警线,阈值为6.1k CDEF:inbits=inoctets,8,*", #将入流量换算成bit,即*8,计算结果给inbits "CDEF:outbits=outoctets,8,*", #将出流量换算成bit,即*8,计算结果给outbits "COMMENT:\\r", #在网格下方输出一个换行符 "COMMENT:\\r", "GPRINT:inbits:AVERAGE:Avg In traffic\: %6.2lf %Sbps", #绘制入流量平均值 "COMMENT: ", "GPRINT:inbits:MAX:Max In traffic\: %6.2lf %Sbps", #绘制入流量最大值 "COMMENT: ", "GPRINT:inbits:MIN:MIN In traffic\: %6.2lf %Sbps\\r", #绘制入流量最小值 "COMMENT: ", "GPRINT:outbits:AVERAGE:Avg Out traffic\: %6.2lf %Sbps", #绘制出流量平均值 "COMMENT: ", "GPRINT:outbits:MAX:Max Out traffic\: %6.2lf %Sbps", #绘制出流量最大值 "COMMENT: ", "GPRINT:outbits:MIN:MIN Out traffic\: %6.2lf %Sbps\\r") #绘制出流量最小值
上代码将生成一个Flow.png文件,如图3-13所示。
提示查看rrd文件内容有利于观察数据的结构、更新等情况,rrdtool提供几个常用命令:
·info查看rrd文件的结构信息,如rrdtool info Flow.rrd;
·first查看rrd文件第一个数据的更新时间,如rrdtool first Flow.rrd;
·last查看rrd文件最近一次更新的时间,如rrdtool last Flow.rrd;
·fetch根据指定时间、CF查询rrd文件,如rrdtool fetch Flow.rrd AVERAGE。
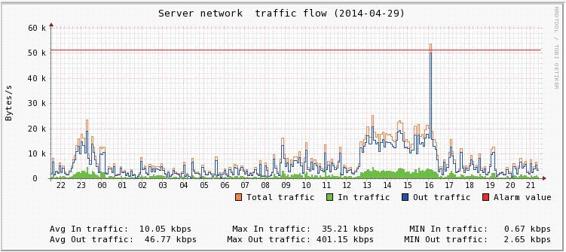
图3-13 graph.py执行输出图表 参考提示
rrdtool参数说明参考http://bbs.chinaunix.net/thread-2150417-1-1.html和http://oss.oetiker.ch/rrdtool/doc/index.en.html。
三、构建集中式的病毒扫描机制
Clam AntiVirus(ClamAV)是一款免费而且开放源代码的防毒软件,软件与病毒库的更新皆由社区免费发布,官网地址:http://www.clamav.net/lang/en/。目前ClamAV主要为Linux、Unix系统提供病毒扫描、查杀等服务。pyClamad(http://xael.org/norman/python/pyclamd/)是一个Python第三方模块,可让Python直接使用ClamAV病毒扫描守护进程clamd,来实现一个高效的病毒检测功能,另外,pyClamad模块也非常容易整合到我们已有的平台当中。下面详细进行说明。
1.pyClamad模块的安装:
# 1、客户端(病毒扫描源)安装步骤
# yum install -y clamav clamd clamav-update #安装clamavp相关程序包
# chkconfig --levels 235 clamd on #添加扫描守护进程clamd系统服务
# /usr/bin/freshclam #更新病毒库,建议配置到crontab中定期更新
# setenforce 0 #关闭SELinux,避免远程扫描时提示无权限的问题
# 更新守护进程监听IP配置文件,根据不同环境自行修改监听的IP,“0.0.0.0”为监听所有主机IP
# sed -i -e '/^TCPAddr/{ s/127.0.0.1/0.0.0.0/; }' /etc/clamd.conf
# /etc/init.d/clamd start #启动扫描守护进程
# 2、主控端部署pyClamad环境步骤
# wget http://xael.org/norman/python/pyclamd/pyClamd-0.3.4.tar.gz # tar -zxvf pyClamd-0.3.4.tar.gz # cd pyClamd-0.3.4 # python setup.py install
2.模块常用方法说明
pyClamad提供了两个关键类,一个为ClamdNetworkSocket()类,实现使用网络套接字操作clamd;另一个为ClamdUnixSocket()类,实现使用Unix套接字类操作clamd。两个类定义的方法完全一样,本节以ClamdNetworkSocket()类进行说明。
·__init__(self,host=’127.0.0.1’,port=3310,timeout=None)方法,是ClamdNetworkSocket类的初始化方法,参数host为连接主机IP;参数port为连接的端口,默认为3310,与/etc/clamd.conf配置文件中的TCPSocket参数要保持一致;timeout为连接的超时时间。
·contscan_file(self,file)方法,实现扫描指定的文件或目录,在扫描时发生错误或发现病毒将不终止,参数file(string类型)为指定的文件或目录的绝对路径。
·multiscan_file(self,file)方法,实现多线程扫描指定的文件或目录,多核环境速度更快,在扫描时发生错误或发现病毒将不终止,参数file(string类型)为指定的文件或目录的绝对路径。
·scan_file(self,file)方法,实现扫描指定的文件或目录,在扫描时发生错误或发现病毒将终止,参数file(string类型)为指定的文件或目录的绝对路径。
·shutdown(self)方法,实现强制关闭clamd进程并退出。
·stats(self)方法,获取Clamscan的当前状态。
·reload(self)方法,强制重载clamd病毒特征库,扫描前建议做reload操作。
·EICAR(self)方法,返回EICAR测试字符串,即生成具有病毒特征的字符串,便于测试。
3.实践:实现集中式的病毒扫描
本次实践实现了一个集中式的病毒扫描管理,可以针对不同业务环境定制扫描策略,比如扫描对象、描述模式、扫描路径、调度频率等。示例实现的架构见图4-1,首先业务服务器开启clamd服务(监听3310端口),管理服务器启用多线程对指定的服务集群进行扫描,扫描模式、扫描路径会传递到clamd,最后返回扫描结果给管理服务器端。

图4-1 集群病毒扫描架构图
本次实践通过ClamdNetworkSocket()方法实现与业务服务器建立扫描socket连接,再通过启动不同扫描方式实施病毒扫描并返回结果。实现代码如下:【/home/test/pyClamad/simple1.py】
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
import pyclamd
from threading import Thread
class Scan(Thread):
def __init__ (self,IP,scan_type,file):
"""构造方法,参数初始化"""
Thread.__init__(self)
self.IP = IP
self.scan_type=scan_type
self.file = file self.connstr=""
self.scanresult=""
def run(self):
"""多进程run方法"""
try:
cd = pyclamd.ClamdNetworkSocket(self.IP,3310) #创建网络套接字连接对象
if cd.ping(): #探测连通性
self.connstr=self.IP+" connection [OK]"
cd.reload() #重载clamd病毒特征库,建议更新病毒库后做reload()操作
if self.scan_type=="contscan_file": #选择不同的扫描模式
self.scanresult="{0}\n".format(cd.contscan_file(self.file))
elif self.scan_type=="multiscan_file":
self.scanresult="{0}\n".format(cd.multiscan_file(self.file))
elif self.scan_type=="scan_file":
self.scanresult="{0}\n".format(cd.scan_file(self.file))
time.sleep(1) #线程挂起1秒
else:
self.connstr=self.IP+" ping error,exit"
return except Exception,e:
self.connstr=self.IP+" "+str(e)
IPs=['192.168.1.21','192.168.1.22'] #扫描主机列表
scantype="multiscan_file" #指写扫描模式,支持multiscan_file、contscan_file、scan_file
scanfile="/data/www" #指定扫描路径
i=1
threadnum=2 #指定启动的线程数
scanlist = [] #存储扫描Scan类线程对象列表
for ip in IPs:
currp = Scan(ip,scantype,scanfile)#创建扫描Scan类对象,参数(IP,扫描模式,扫描路径)
scanlist.append(currp) #追加对象到列表
if i%threadnum==0 or i==len(IPs): #当达到指定的线程数或IP列表数后启动、退出线程
for task in scanlist:
task.start() #启动线程
for task in scanlist:
task.join() #等待所有子线程退出,并输出扫描结果
print task.connstr #打印服务器连接信息
print task.scanresult #打印扫描结果
scanlist = []
i+=1
通过EICAR()方法生成一个带有病毒特征的文件/tmp/EICAR,代码如下:
void = open(’/tmp/EICAR’,’w’).write(cd.EICAR())
生成带有病毒特征的字符串内容如下,复制文件/tmp/EICAR到目标主机的扫描目录当中,以便进行测试。
#cat /tmp/EICAR
u’X5O!P%@AP[4\\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*’
最后,启动扫描程序,在本次实践过程中启用两个线程,可以根据目标主机数量随意修改,代码运行结果如图4-2,其中192.168.1.21主机没有发现病毒,192.168.1.22主机发现了病毒测试文件EICAR。 图4-2 集中式病毒扫描程序运行结果 参考提示
pyClamad模块方法说明参考http://xael.org/norman/python/pyclamd/pyclamd.html。
四、系统批量运维管理器paramiko详解
paramiko是基于Python实现的SSH2远程安全连接,支持认证及密钥方式。可以实现远程命令执行、文件传输、中间SSH代理等功能,相对于Pexpect,封装的层次更高,更贴近SSH协议的功能,官网地址:http://www.paramiko.org。
1.paramiko的安装
paramiko支持pip、easy_install或源码安装方式,很方便解决包依赖的问题,具体安装命令如下(根据用户环境,自行选择pip或easy_install):
pip install paramiko
easy_install paramiko paramiko
依赖第三方的Crypto、Ecdsa包及Python开发包python-devel的支持,源码安装步骤如下:
# yum -y install python-devel # wget http://ftp.dlitz.net/pub/dlitz/crypto/pycrypto/pycrypto-2.6.tar.gz # tar -zxvf pycrypto-2.6.tar.gz # cd pycrypto-2.6 # python setup.py install # cd .. # wget https://pypi.python.org/packages/source/e/ecdsa/ecdsa-0.10.tar.gz --no-check-certificate # tar -zxvf ecdsa-0.10.tar.gz # cd ecdsa-0.10 # python setup.py install # cd .. # wget https://github.com/paramiko/paramiko/archive/v1.12.2.tar.gz # tar -zxvf v1.12.2.tar.gz # cd paramiko-1.12.2/ # python setup.py install
校验安装结果,导入模块没有提示异常则说明安装成功:
# python
Python 2.6.6 (r266:84292, Jul 10 2013, 22:48:45)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import paramiko
>>>
下面介绍一个简单实现远程SSH运行命令的示例。该示例使用密码认证方式,通过exec_command()方法
源码如下:
【/home/test/paramiko/simple1.py】
#!/usr/bin/env python import paramiko hostname='192.168.1.21' username='root' password='SKJh935yft #' paramiko.util.log_to_file('syslogin.log') #发送paramiko日志到syslogin.log文件 ssh=paramiko.SSHClient() #创建一个ssh客户端client对象 ssh.load_system_host_keys() #获取客户端host_keys,默认~/.ssh/known_hosts,非默认路 径需指定 ssh.connect(hostname=hostname,username=username,password=password) #创建ssh连接 stdin,stdout,stderr=ssh.exec_command('free -m') #调用远程执行命令方法exec_command() print stdout.read() #打印命令执行结果,得到Python列表形式,可以使用stdout.readlines() s sh.close() #关闭ssh连接
程序的运行结果截图如图6-1所示。

图6-1 程序运行结果
2.核心组件
paramiko包含两个核心组件,一个为SSHClient类,另一个为SFTPClient类,下面详细介绍。
2.1SSHClient类
SSHClient类是SSH服务会话的高级表示,该类封装了传输(transport)、通道(channel)及SFTPClient的校验、建立的方法,通常用于执行远程命令,下面是一个简单的例子:
client = SSHClient()
client.load_system_host_keys()
client.connect(’ssh.example.com’)
stdin, stdout, stderr = client.exec_command(’ls -l’)
下面介绍SSHClient常用的几个方法。
1.connect方法
connect方法实现了远程SSH连接并校验。
方法定义:
connect(self, hostname, port=22, username=None, password=None, pkey=None, key_filename=None, timeout=None, allow_agent=True, look_for_keys=True, compress=False)
参数说明:
·hostname(str类型),连接的目标主机地址;
·port(int类型),连接目标主机的端口,默认为22;
·username(str类型),校验的用户名(默认为当前的本地用户名);
·password(str类型),密码用于身份校验或解锁私钥;
·pkey(PKey类型),私钥方式用于身份验证;
·key_filename(str or list(str)类型),一个文件名或文件名的列表,用于私钥的身份验证;
·timeout(float类型),一个可选的超时时间(以秒为单位)的TCP连接;
·allow_agent(bool类型),设置为False时用于禁用SSH代理;
·look_for_keys(bool类型),设置为False时用来禁用在~/.ssh中搜索私钥文件;
·compress(bool类型),设置为True时打开压缩。
2.exec_command方法
远程命令执行方法,该命令的输入与输出流为标准输入(stdin)、输出(stdout)、错误(stderr)的Python文件对象,方法定义:
exec_command(self, command, bufsize=-1)
参数说明:
·command(str类型),执行的命令串;
·bufsize(int类型),文件缓冲区大小,默认为–1(不限制)。
3.load_system_host_keys方法
加载本地公钥校验文件,默认为~/.ssh/known_hosts,非默认路径需要手工指定,方法定义:
load_system_host_keys(self, filename=None)
参数说明:
filename(str类型),指定远程主机公钥记录文件。
4.set_missing_host_key_policy方法
设置连接的远程主机没有本地主机密钥或HostKeys对象时的策略,目前支持三种,分别是AutoAddPolicy、RejectPolicy(默认)、WarningPolicy,仅限用于SSHClient类,分别代表的含义如下:
·AutoAddPolicy,自动添加主机名及主机密钥到本地HostKeys对象,并将其保存,不依赖load_system_host_keys()的配置,即使~/.ssh/known_hosts不存在也不产生影响;
·RejectPolicy,自动拒绝未知的主机名和密钥,依赖load_system_host_keys()的配置;
·WarningPolicy,用于记录一个未知的主机密钥的Python警告,并接受它,功能上与AutoAddPolicy相似,但未知主机会有告警。使用方法如下:
ssh=paramiko.SSHClient()
missing_host_key_policy(paramiko.AutoAddPolicy())
2.2SFTPClient类
SFTPClient作为一个SFTP客户端对象,根据SSH传输协议的sftp会话,实现远程文件操作,比如文件上传、下载、权限、状态等操作,下面介绍SFTPClient类的常用方法。
1.from_transport方法
创建一个已连通的SFTP客户端通道,方法定义:
from_transport(cls, t)
参数说明:
t(Transport),一个已通过验证的传输对象。
例子说明:
t = paramiko.Transport(("192.168.1.22",22)) t.connect(username="root", password="KJSdj348g") sftp =paramiko.SFTPClient.from_transport(t)
2.put方法
上传本地文件到远程SFTP服务端,方法定义:
put(self, localpath, remotepath, callback=None, confirm=True)
参数说明:
·localpath(str类型),需上传的本地文件(源);
·remotepath(str类型),远程路径(目标);
·callback(function(int,int)),获取已接收的字节数及总传输字节数,以便回调函数调用,默认为None;
·confirm(bool类型),文件上传完毕后是否调用stat()方法,以便确认文件的大小。
例子说明:
localpath=’/home/access.log’ remotepath=’/data/logs/access.log’ sftp.put(localpath,remotepath)
3.get方法
SFTP服务端下载文件到本地,方法定义:
get(self, remotepath, localpath, callback=None)
参数说明:
·remotepath(str类型),需下载的远程文件(源);
·localpath(str类型),本地路径(目标);
·callback(function(int,int)),获取已接收的字节数及总传输字节数,以便回调函数调用,默认为None。
例子说明:
remotepath='/data/logs/access.log' localpath='/home/access.log' sftp.get(remotepath, localpath)
4.其他方法
SFTPClient类其他常用方法说明:
·Mkdir,在SFTP服务器端创建目录,如sftp.mkdir(”/home/userdir”,0755)。
·remove,删除SFTP服务器端指定目录,如sftp.remove(”/home/userdir”)。
·rename,重命名SFTP服务器端文件或目录,如sftp.rename(”/home/test.sh”,”/home/testfile.sh”)。
·stat,获取远程SFTP服务器端指定文件信息,如sftp.stat(”/home/testfile.sh”)。
·listdir,获取远程SFTP服务器端指定目录列表,以Python的列表(List)形式返回,如sftp.listdir(”/home”)。
5.SFTPClient类应用示例
下面为SFTPClient类的一个完整示例,实现了文件上传、下载、创建与删除目录等,需要注意的是,put和get方法需要指定文件名,不能省略。详细源码如下:
#!/usr/bin/env python
import paramiko
username = "root"
password = "KJsd8t34d"
hostname = "192.168.1.21"
port = 22
try:
t = paramiko.Transport((hostname, port))
t.connect(username=username, password=password)
sftp =paramiko.SFTPClient.from_transport(t)
sftp.put("/home/user/info.db", "/data/user/info.db") #上传文件
sftp.get("/data/user/info_1.db", "/home/user/info_1.db") #下载文件
sftp.mkdir("/home/userdir",0755) #创建目录 sftp.rmdir("/home/userdir") #删除目录
sftp.rename("/home/test.sh","/home/testfile.sh") #文件重命名 print
sftp.stat("/home/testfile.sh") #打印文件信息
print sftp.listdir("/home") #打印目录列表
t.close();
except Exception, e:
print str(e)
3.paramiko应用示例
3.1 实现密钥方式登录远程主机
实现自动密钥登录方式,第一步需要配置与目标设备的密钥认证支持,具体见9.2.5节,私钥文件可以存放在默认路径“~/.ssh/id_rsa”,当然也可以自定义,如本例的“/home/key/id_rsa”,通过paramiko.RSAKey.from_private_key_file()方法引用,详细代码如下:【/home/test/paramiko/simple2.py】
#!/usr/bin/env python import paramiko import os hostname='192.168.1.21' username='root' paramiko.util.log_to_file('syslogin.log') ssh=paramiko.SSHClient() ssh.load_system_host_keys() privatekey = os.path.expanduser('/home/key/id_rsa') #定义私钥存放路径 key = paramiko.RSAKey.from_private_key_file(privatekey) #创建私钥对象key s sh.connect(hostname=hostname,username=username,pkey = key) stdin,stdout,stderr=ssh.exec_command('free -m') print stdout.read() ssh.close()
程序执行结果见图6-1。
3.2 实现堡垒机模式下的远程命令执行
堡垒机环境在一定程度上提升了运营安全级别,但同时也提高了日常运营成本,作为管理的中转设备,任何针对业务服务器的管理请求都会经过此节点,比如SSH协议,首先运维人员在办公电脑通过SSH协议登录堡垒机,再通过堡垒机SSH跳转到所有的业务服务器进行维护操作,如图6-2所示。
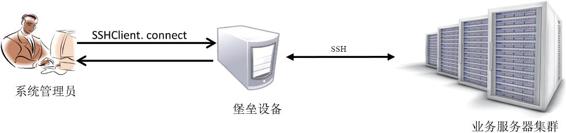
图6-2 堡垒机模式下的远程命令执行我们可以利用paramiko的invoke_shell机制来实现通过堡垒机实现服务器操作,原理是SSHClient.connect到堡垒机后开启一个新的SSH会话(session),通过新的会话运行”ssh user@IP”去实现远程执行命令的操作。实现代码如下:【/home/test/paramiko/simple3.py】
#!/usr/bin/env python import paramiko import os,sys,time blip="192.168.1.23" #定义堡垒机信息 bluser="root" blpasswd="KJsdiug45" hostname="192.168.1.21" #定义业务服务器信息 username="root" password="IS8t5jgrie" port=22 passinfo='\'s password: ' #输入服务器密码的前标志串 paramiko.util.log_to_file('syslogin.log') ssh=paramiko.SSHClient() #ssh登录堡垒机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(hostname=blip,username=bluser,password=blpasswd) channel=ssh.invoke_shell() #创建会话,开启命令调用 channel.settimeout(10) #会话命令执行超时时间,单位为秒 buff = '' resp = '' channel.send('ssh '+username+'@'+hostname+'\n') #执行ssh登录业务主机 while not buff.endswith(passinfo): #ssh登录的提示信息判断,输出串尾含有"\'s password:"时 try: #退出while循环 resp = channel.recv(9999) except Exception,e: print 'Error info:%s connection time.' % (str(e)) channel.close() ssh.close() sys.exit() buff += resp if not buff.find('yes/no')==-1: #输出串尾含有"yes/no"时发送"yes"并回车 channel.send('yes\n') buff='' channel.send(password+'\n') #发送业务主机密码 buff='' while not buff.endswith('# '): #输出串尾为“#”说明校验通过并退出while循环 resp = channel.recv(9999) if not resp.find(passinfo)==-1: #输出串尾含有"\'s password: "时说明密码不正确, 要求重新输入 print 'Error info: Authentication failed.' channel.close() #关闭连接对象后退出 ssh.close() sys.exit() buff += resp channel.send('ifconfig\n') #认证通过后发送ifconfig命令来查看结果 buff='' try: while buff.find('# ')==-1: resp = channel.recv(9999) buff += resp except Exception, e: print "error info:"+str(e) print buff #打印输出串 channel.close() ssh.close()
运行结果如下:
# python /home/test/paramiko/simple3.py
ifconfig
eth0 Link encap:Ethernet HWaddr 00:50:56:28:63:2D
inet addr:192.168.1.21 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::250:56ff:fe28:632d/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3523007 errors:0 dropped:0 overruns:0 frame:0
TX packets:6777657 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:606078157 (578.0 MiB) TX bytes:1428493484 (1.3 GiB) lo
Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0 … …
显示“inet addr:192.168.1.21”说明命令已经成功执行。
3.3实现堡垒模式下的远程文件上传
实现堡垒机模式下的文件上传,原理是通过paramiko的SFTPClient将文件从办公设备上传至堡垒机指定的临时目录,如/tmp,再通过SSHClient的invoke_shell方法开启ssh会话,执行scp命令,将/tmp下的指定文件复制到目标业务服务器上,如图6-3所示。
本示例具体使用sftp.put()方法上传文件至堡垒机临时目录,再通过send()方法执行scp命令,将堡垒机临时目录下的文件复制到目标主机,详细的实现源码如下:【/home/test/paramiko/simple4.py】
#!/usr/bin/env python
import paramiko
import os,sys,time
blip=”192.168.1.23″ #定义堡垒机信息
bluser=”root”
blpasswd=” IS8t5jgrie”
hostname=”192.168.1.21″ #定义业务服务器信息
username=”root”
password=” KJsdiug45″
tmpdir=”/tmp”
remotedir=”/data”
localpath=”/home/nginx_access.tar.gz” #本地源文件路径
tmppath=tmpdir+”/nginx_access.tar.gz” #堡垒机临时路径
remotepath=remotedir+”/nginx_access_hd.tar.gz” #业务主机目标路径
port=22
passinfo=’\’s password: ‘
paramiko.util.log_to_file(’syslogin.log’)
t = paramiko.Transport((blip, port))
t.connect(username=bluser, password=blpasswd)
sftp =paramiko.SFTPClient.from_transport(t)
sftp.put(localpath, tmppath) #上传本地源文件到堡垒机临时路径
sftp.close()
ssh=paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(hostname=blip,username=bluser,password=blpasswd)
channel=ssh.invoke_shell()
channel。settimeout(10)
buff = ” resp = ”
#scp中转目录文件到目标主机
channel.send(’scp ‘+tmppath+’ ‘+username+’@’+hostname+’:’+remotepath+’\n’)
while not buff.endswith(passinfo):
try:
resp = channel.recv(9999)
except Exception,e:
print ‘Error info:%s connection time.’ % (str(e))
channel.close()
ssh.close()
sys.exit()
buff += resp
if not buff.find(’yes/no’)==-1:
channel.send(’yes\n’)
buff=”
channel.send(password+’\n’)
buff=”
while not buff.endswith(’# ‘):
resp = channel.recv(9999)
if not resp.find(passinfo)==-1:
print ‘Error info: Authentication failed.’
channel.close()
ssh.close()
sys.exit()
buff += resp
print buff
channel.close()
ssh.close()
运行结果如下,如目标主机/data/nginx_access_hd.tar.gz存在,则说明文件已成功上传。
# python /home/test/paramiko/simple4.py
nginx_access.tar.gz 100% 1590KB 1.6MB/s 00:00
当然,整合以上两个示例,再引入主机清单及功能配置文件,可以实现更加灵活、强大的功能,大家可以自己动手,在实践中学习,打造适合自身业务环境的自动化运营平台。
常用类说明与应用案例参考http://docs.paramiko.org/en/1.13/官网文档。
五、系统批量运维管理器Fabric详解
Fabric是基于Python(2.5及以上版本)实现的SSH命令行工具,简化了SSH的应用程序部署及系统管理任务,它提供了系统基础的操作组件,可以实现本地或远程shell命令,包括命令执行、文件上传、下载及完整执行日志输出等功能。Fabric在paramiko的基础上做了更高一层的封装,操作起来会更加简单。Fabric官网地址为:http://www.fabfile.org。
1.Fabric的安装
Fabric支持pip、easy_install或源码安装方式,很方便解决包依赖的问题,具体安装命令如下(根据用户环境,自行选择pip或easy_install):
pip install fabric
easy_install fabric
Fabric依赖第三方的setuptools、Crypto、paramiko包的支持,源码安装步骤如下:
# yum -y install python-setuptools # wget https://pypi.python.org/packages/source/F/Fabric/Fabric-1.8.2.tar.gz --no-check-certificate # tar -zxvf Fabric-1.8.2.tar.gz # cd Fabric-1.8.2 # python setup.py install
校验安装结果,如果导入模块没有提示异常,则说明安装成功:
# python
Python 2.6.6 (r266:84292, Jul 10 2013, 22:48:45)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import fabric
>>>
简单的入门示例:
【/home/test/fabric/fabfile.py】
#!/usr/bin/env python
from fabric.api import run
def host_type(): #定义一个任务函数,通过run方法实现远程执行‘uname -s’命令
run(’uname -s’)
其中,fab命令引用默认文件名为fabfile.py,如果使用非默认文件名称,则需通过“-f”来指定,如:fab-H SN2013-08-021,SN2013-08-022-f host_type.py host_type。如果管理机与目标主机未配置密钥认证信任,将会提示输入目标主机对应账号登录密码。
2.fab常用参数
fab作为Fabric程序的命令行入口,提供了丰富的参数调用,命令格式如下:
fab [options] <command>[:arg1,arg2=val2,host=foo,hosts=’h1;h2’,…] …
下面列举了常用的几个参数,更多参数可使用fab-help查看。
·-l,显示定义好的任务函数名;
·-f,指定fab入口文件,默认入口文件名为fabfile.py;
·-g,指定网关(中转)设备,比如堡垒机环境,填写堡垒机IP即可;
·-H,指定目标主机,多台主机用“,”号分隔;
·-P,以异步并行方式运行多主机任务,默认为串行运行;
·-R,指定role(角色),以角色名区分不同业务组设备;
·-t,设置设备连接超时时间(秒);
·-T,设置远程主机命令执行超时时间(秒);
·-w,当命令执行失败,发出告警,而非默认中止任务。
有时候我们甚至不需要写一行Python代码也可以完成远程操作,直接使用命令行的形式,例如:
# fab -p Ksdh3458d(密码) -H 192.168.1.21,192.168.1.22 — ‘uname -s’
3 fabfile的编写
fab命令是结合我们编写的fabfile.py(其他文件名须添加-f filename引用)来搭配使用的,部分命令行参数可以通过相应的方法来代替,使之更加灵活,例如“-H 192.168.1.21,192.168.1.22”,我们可以通过定义env.hosts来实现,如“env.hosts=[‘192.168.1.21’,’192.168.1.22’]”。fabfile的主体由多个自定义的任务函数组成,不同任务函数实现不同的操作逻辑,下面详细介绍。
3.1 全局属性设定
evn对象的作用是定义fabfile的全局设定,支持多个属性,包括目标主机、用户、密码、角色等,各属性说明如下:
·env.host,定义目标主机,可以用IP或主机名表示,以Python的列表形式定义,如env.hosts=[‘192.168.1.21’,’192.168.1.22’]。
·env.exclude_hosts,排除指定主机,如env.exclude_hosts=[‘192.168.1.22’]。
·env.user,定义用户名,如env.user=”root”。
·env.port,定义目标主机端口,默认为22,如env.port=”22″。
·env.password,定义密码,如env.password=’KSJ3548t7d’。
·env.passwords,与password功能一样,区别在于不同主机不同密码的应用场景,需要注意的是,配置passwords时需配置用户、主机、端口等信息,如:
env.passwords = {
'root@192.168.1.21:22': 'SJk348ygd',
'root@192.168.1.22:22': 'KSh458j4f',
'root@192.168.1.23:22': 'KSdu43598'
}
·env.gateway,定义网关(中转、堡垒机)IP,如env.gateway=’192.168.1.23’。
·env.deploy_release_dir,自定义全局变量,格式:env.+“变量名称”,如env.deploy_release_dir、env.age、env.sex等。
·env.roledefs,定义角色分组,比如web组与db组主机区分开来,定义如下:
env.roledefs = {
‘webservers’: [‘192.168.1.21’, ‘192.168.1.22’, ‘192.168.1.23’, ‘192.168.1.24’], ‘dbservers’: [‘192.168.1.25’, ‘192.168.1.26’]
}
引用时使用Python修饰符的形式进行,角色修饰符下面的任务函数为其作用域,下面来看一个示例:
@roles(’webservers’)
def webtask():
run(’/etc/init.d/nginx start’)
@roles(’dbservers’)
def dbtask():
run(’/etc/init.d/mysql start’)
@roles (’webservers’, ‘dbservers’)
def pubclitask():
run(’uptime’)
def deploy():
execute(webtask)
execute(dbtask)
execute(pubclitask)
在命令行执行#fab deploy就可以实现不同角色执行不同的任务函数了。
3.2 常用API
Fabric提供了一组简单但功能强大的fabric.api命令集,简单地调用这些API就能完成大部分应用场景需求。Fabric支持常用的方法及说明如下:
·local,执行本地命令,如:local(’uname-s’);
·lcd,切换本地目录,如:lcd(’/home’);
·cd,切换远程目录,如:cd(’/data/logs’);
·run,执行远程命令,如:run(’free-m’);
·sudo,sudo方式执行远程命令,如:sudo(’/etc/init.d/httpd start’);
·put,上传本地文件到远程主机,如:put(’/home/user.info’,’/data/user.info’);
·get,从远程主机下载文件到本地,如:get(’/data/user.info’,’/home/root.info’);
·prompt,获得用户输入信息,如:prompt(’please input user password:’);
·confirm,获得提示信息确认,如:confirm(“Tests fsiled.Continue[Y/N]?”);
·reboot,重启远程主机,如:reboot();
·@task,函数修饰符,标识的函数为fab可调用的,非标记对fab不可见,纯业务逻辑;
·@runs_once,函数修饰符,标识的函数只会执行一次,不受多台主机影响。下面结合一些示例来帮助大家理解以上常用的API。
3.3 示例1:查看本地与远程主机信息
本示例调用local()方法执行本地(主控端)命令,添加“@runs_once”修饰符保证该任务函数只执行一次。调用run()方法执行远程命令。详细源码如下:【/home/test/fabric/simple1.py】
#!/usr/bin/env python
from fabric.api import *
env.user=’root’
env.hosts=[‘192.168.1.21’,’192.168.1.22′]
env.password=’LKs934jh3′
@runs_once #查看本地系统信息,当有多台主机时只运行一次
def local_task(): #本地任务函数
local(”uname -a”)
def remote_task():
with cd(”/data/logs”): #“with”的作用是让后面的表达式的语句继承当前状态,实现
run(”ls -l”) # “cd /data/logs && ls -l”的效果
通过fab命令分别调用local_task任务函数运行
调用local_task任务函数运行结果结果中显示了“[192.168.1.21]Executing task’local_task’”,但事实上并非在主机192.168.1.21上执行任务,而是返回Fabric主机本地“uname-a”的执行结果。
3.4示例2:动态获取远程目录列表
本示例使用“@task”修饰符标志入口函数go()对外部可见,配合“@runs_once”修饰符接收用户输入,最后调用worktask()任务函数实现远程命令执行,详细源码如下:【/home/test/fabric/simple2.py】
#!/usr/bin/env python
from fabric.api import *
env.user=’root’
env.hosts=[‘192.168.1.21’,’192.168.1.22′]
env.password=’LKs934jh3′
@runs_once #主机遍历过程中,只有第一台触发此函数
def input_raw():
return prompt(”please input directory name:”,default=”/home”)
def worktask(dirname):
run(”ls -l “+dirname)
@task #限定只有go函数对fab命令可见
def go():
getdirname = input_raw()
worktask(getdirname)
该示例实现了一个动态输入远程目录名称,再获取目录列表的功能,由于我们只要求输入一次,再显示所有主机上该目录的列表信息,调用了一个子函数input_raw()同时配置@runs_once修饰符来达到此目的。
4.Fabric应用示例
下面介绍几个比较典型的应用Fabric的示例,涉及文件上传与校验、环境部署、代码发布的功能,读者可以在此基础进行功能扩展,写出更加贴近业务场景的工具平台。
4.1 示例1:文件打包、上传与校验
我们时常做一些文件包分发的工作,实施步骤一般是先压缩打包,再批量上传至目标服务器,最后做一致性校验。本案例通过put()方法实现文件的上传,通过对比本地与远程主机文件的md5,最终实现文件一致性校验。详细源码如下:
【/home/test/fabric/simple4.py】
#!/usr/bin/env python
from fabric.api import *
from fabric.context_managers import *
from fabric.contrib.console import confirm
env.user=’root’
env.hosts=[‘192.168.1.21’,’192.168.1.22′]
env.password=’LKs934jh3′
@task
@runs_once
def tar_task(): #本地打包任务函数,只限执行一次
with lcd(”/data/logs”):
local(”tar -czf access.tar.gz access.log”)
@task
def put_task(): #上传文件任务函数
run(”mkdir -p /data/logs”)
with cd(”/data/logs”):
with settings(warn_only=True): #put(上传)出现异常时继续执行,非终止
result = put(”/data/logs/access.tar.gz”, “/data/logs/access.tar.gz”)
if result.failed and not confirm(”put file failed, Continue[Y/N]?”):
abort(”Aborting file put task!”) #出现异常时,确认用户是否继续,(Y继续)
@task
def check_task(): #校验文件任务函数
with settings(warn_only=True): #本地local命令需要配置capture=True才能捕获返回值
lmd5=local(”md5sum /data/logs/access.tar.gz”,capture=True).
split(’ ‘)[0]
rmd5=run(”md5sum /data/logs/access.tar.gz”).split(’ ‘)[0]
if lmd5==rmd5: #对比本地及远程文件md5信息
print “OK”
else:
print “ERROR”
本示例通过定义三个功能任务函数,分别实现文件的打包、上传、校验功能,且三个功能相互独立,可分开运行,如:
fab -f simple4.py tar_task #文件打包
fab -f simple4.py put_task #文件上传
fab -f simple4.py check_task #文件校验
当然,我们也可以组合在一起运行,再添加一个任务函数go,代码如下:
@task
def go():
tar_task()
put_task()
check_task()
运行fab-f simple4.py go就可以实现文件打包、上传、校验全程自动化。
4.2 示例2:部署LNMP业务服务环境
业务上线之前最关键的一项任务便是环境部署,往往一个业务涉及多种应用环境,比如Web、DB、PROXY、CACHE等,本示例通过env.roledefs定义不同主机角色,再使用“@roles(’webservers’)”修饰符绑定到对应的任务函数,实现不同角色主机的部署差异,详细源码如下:
【/home/test/fabric/simple5.py】
#!/usr/bin/env python
from fabric.colors import *
from fabric.api import *
env.user=’root’
env.roledefs = { #定义业务角色分组
‘webservers’: [‘192.168.1.21’, ‘192.168.1.22’],
‘dbservers’: [‘192.168.1.23’]
}
passwords = {
‘root@192.168.1.21:22’: ‘SJk348ygd’,
‘root@192.168.1.22:22’: ‘KSh458j4f’,
‘root@192.168.1.23:22’: ‘KSdu43598’
}
@roles(’webservers’) #webtask任务函数引用’webservers’角色修饰符
def webtask(): #部署nginx php php-fpm等环境
print yellow(”Install nginx php php-fpm…”)
with settings(warn_only=True):
run(”yum -y install nginx”)
run(”yum -y install php-fpm php-mysql php-mbstring php-xml php-mcrypt php-gd”)
run(”chkconfig –levels 235 php-fpm on”)
run(”chkconfig –levels 235 nginx on”)
@roles(’dbservers’) # dbtask任务函数引用’dbservers’角色修饰符
def dbtask(): #部署mysql环境
print yellow(”Install Mysql…”)
with settings(warn_only=True):
run(”yum -y install mysql mysql-server”)
run(”chkconfig –levels 235 mysqld on”)
@roles (’webservers’, ‘dbservers’) # publictask任务函数同时引用两个角色修饰符
def publictask(): #部署公共类环境,如epel、ntp等
print yellow(”Install epel ntp…”)
with settings(warn_only=True):
run(”rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel- release-6-8.noarch.rpm”)
run(”yum -y install ntp”)
def deploy():
execute(publictask)
execute(webtask)
execute(dbtask)
本示例通过角色来区别不同业务服务环境,分别部署不同的程序包。我们只需要一个Python脚本就可以完成不同业务环境的定制。
4.3 示例3:生产环境代码包发布管理
程序生产环境的发布是业务上线最后一个环节,要求具备源码打包、发布、切换、回滚、版本管理等功能,本示例实现了这一整套流程功能,其中版本切换与回滚使用了Linux下的软链接实现。详细源码如下:
【/home/test/fabric/simple6.py】
#!/usr/bin/env python
from fabric.api import *
from fabric.colors import *
from fabric.context_managers import *
from fabric.contrib.consoleimport confirm
import time
env.user=’root’
env.hosts=[‘192.168.1.21’,’192.168.1.22′]
env.password=’LKs934jh3’
env.project_dev_source = ‘/data/dev/Lwebadmin/’ #开发机项目主目录
env.project_tar_source = ‘/data/dev/releases/’ #开发机项目压缩包存储目录
env.project_pack_name = ‘release’ #项目压缩包名前缀,文件名为release.tar.gz
env.deploy_project_root = ‘/data/www/Lwebadmin/’ #项目生产环境主目录
env.deploy_release_dir = ‘releases’ #项目发布目录,位于主目录下面
env.deploy_current_dir = ‘current’ #对外服务的当前版本软链接
env.deploy_version=time.strftime(”%Y%m%d”)+”v2″ #版本号
@runs_once
def input_versionid(): #获得用户输入的版本号,以便做版本回滚操作
return prompt(”please input project rollback version ID:”,default=””)
@task
@runs_once
def tar_source(): #打包本地项目主目录,并将压缩包存储到本地压缩包目录
print yellow(”Creating source package…”)
with lcd(env.project_dev_source):
local(”tar -czf %s.tar.gz .” % (env.project_tar_source + env.project_pack_name))
print green(”Creating source package success!”)
@task
def put_package(): #上传任务函数
print yellow(”Start put package…”)
with settings(warn_only=True):
with cd(env.deploy_project_root+env.deploy_release_dir):
run(”mkdir %s” % (env.deploy_version)) #创建版本目录
env.deploy_full_path=env.deploy_project_root + env.deploy_release_dir +
“/”+env.deploy_version
with settings(warn_only=True): #上传项目压缩包至此目录
result = put(env.project_tar_source + env.project_pack_name +”.tar.gz”, env.deploy_full_path)
if result.failed and no(”put file failed, Continue[Y/N]?”):
abort(”Aborting file put task!”)
with cd(env.deploy_full_path): #成功解压后删除压缩包
run(”tar -zxvf %s.tar.gz” % (env.project_pack_name))
run(”rm -rf %s.tar.gz” % (env.project_pack_name))
print green(”Put & untar package success!”)
@task
def make_symlink(): #为当前版本目录做软链接
print yellow(”update current symlink”)
env.deploy_full_path=env.deploy_project_root + env.deploy_release_dir + “/”+env.deploy_version
with settings(warn_only=True): #删除软链接,重新创建并指定软链源目录,新版本生效
run(”rm -rf %s” % (env.deploy_project_root + env.deploy_current_dir))
run(”ln -s %s %s” % (env.deploy_full_path, env.deploy_project_root + env.deploy_current_dir))
print green(”make symlink success!”)
@task
def rollback(): #版本回滚任务函数
print yellow(”rollback project version”)
versionid= input_versionid() #获得用户输入的回滚版本号
if versionid==”:
abort(”Project version ID error,abort!”)
env.deploy_full_path=env.deploy_project_root + env.deploy_release_dir +
“/”+versionid
run(”rm -f %s” % env.deploy_project_root + env.deploy_current_dir)
run(”ln -s %s %s” % (env.deploy_full_path, env.deploy_project_root + env.
deploy_current_dir)) #删除软链接,重新创建并指定软链源目录,新版本生效
print green(”rollback success!”)
@task
def go(): #自动化程序版本发布入口函数
tar_source()
put_package()
make_symlink()
本示例实现了一个通用性很强的代码发布管理功能,支持快速部署与回滚,无论发布还是回滚,都可以通过切换current的软链来实现,非常灵活。该功能的流程图如图7-5所示。
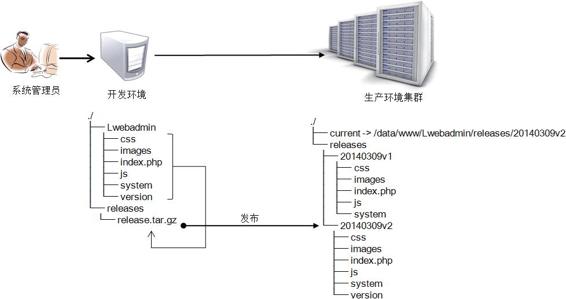
图7-5 生产环境代码包发布管理流程图
在生产环境中Nginx的配置如下:
server_name domain.com
index index.html index.htm index.php;
root /data/www/Lwebadmin/current;
将站点根目录指向“/data/www/Lwebadmin/current”,由于使用Linux软链接做切换,管理员的版本发布、回滚操作用户无感知,同时也规范了我们业务上线的流程。
参考提示 fab常用参数说明参考http://docs.fabfile.org/en/1.8/官网文档。
原创文章,作者:nene,如若转载,请注明出处:http://www.178linux.com/91163

