

一、grep
grep常用于文本搜索。通过自定义的模式(pattern),筛选出使用者需要的文本内容。除了有grep,还有egrep和fgrep。其中egrep = grep –E,而fgrep则是不支持正则表达式。
grep语法:grep [option] pattern [file]
常用option如下:
-i:忽略字符的大小
-n:显示匹配的行号
-c:统计匹配的行数
-o:只显示匹配到的内容
-q:静默模式,不显示出任何信息
-e:实现多个选项的or的关系
-w:匹配整个单词
-v:显示除pattern外的内容
-F:相当于fgrep
-E:相当于egrep
二、正则表达式
1、匹配字符:
. 匹配任意单个字符
[] 匹配中括号内指定范围的任意单个字符
[^] 匹配中括号指定范围外的任意单个字符
[:alnum:] 匹配字母和数字
[:alpha:] 匹配任何英文
[:lower:] 小写英文字母
[:upper:] 大写英文字母
[:blank:] 空白字符(空格和字表符)
[:space:] 水平和垂直的空白字符(范围比blank的广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃等)
[:digit:] 十进制数字
[:xdigit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印的字符
[:punct:] 标点符号
2、匹配次数:
* 匹配前面的字符任意次,包括0次。
\? 匹配前面的字符0或1次
\+ 匹配前面的字符至少一次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符从m到n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
3、定位
^ 定位行首,处于pattern的最左侧
$ 定位行尾,用于pattern的最右侧
\<或\b 词首,用于pattern中单词的左侧
\>或\b 词尾,用于pattern中单词的右侧
\<pattern\> 匹配整个单词
4、分组
\( \)将一个或多个字符捆绑在一起,当作一个整体进行处理。
三、小结
通过一和二的简单介绍,现在将两者结合在一起,并把学习后得到的一些理解写下来。
1、pattern可以直接为想要得到的内容,如图1。


图1
2、[ ]中括号里表示的是匹配的内容的范围,用此括号匹配的结果是一个字符。比如[a-d]表示的是英文abcd这个范围。[ ]不只表示一种范围、内容,可以有多种,比如[a-z[:punct:]0-9]表示的是标点符号、英文字母a至z还有数字0-9。但是没有[0-10]或者是[0-100]等类似的范围,因为在pattern中把需要被过滤的内容都当作字符,而内容中的数字也被拆成一个个字符,没有大小可言,简单点说就是100其实是三个字符1、0、0。还有,单独用类似上文“二”中的[:digit:]这样的内容是会出错的,需要在[:digit:]外再加一个中括号才能表示匹配得到的是一个在digit范围内的字符,如图2。
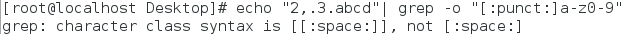
图2
3、再次强调一点,[ ]表示的是匹配得到一个字符,是一个。因此,需要得到多个字符,得用上文
“二”的第二点知识,如图3。

图3
4、\< \>中间括起来的可以为英文和数字,但是不能是别的标点符号,如图4。

图4
“\<\>”和“\>”是把一串连续的英文数字当作整体,而“\<”不是,如图5最后两个命令都匹配不到内容,是因为“\<\>”和“\>”认为存在abcd但不存在abc。

图5
5、\(和\)必须成对出现,并且他们被当作一个整体进行处理,并且分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量,命名方式:\1,\2,\3…
示例:\(string1\+\(string2\)*\)
\1:string1\+\(string2\)*
\2:string2
6、 grep –E 作用:除了\<和\>,其他的例如{ }、( ),没有添加-E时,\{\}表示范围,添加了-E选项后,直接{}表示范围。
原创文章,作者:Eminem,如若转载,请注明出处:http://www.178linux.com/83170
