

正则表达式
简介
REGEXP:由一类特殊字符及文本字符由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)
不表示字符字面意义,而表示控制或通配的功能。
程序支持:grep,sed,awk,vim,less,nginx,varnish等,下面将介绍grep中正则表达式的用法。
正则表达式分基本正则表达式(BRE)和扩展正则表达式(ERE)
正则表达式引擎:采用不同算法,检查处理正则表达式的软件模块PCRE(Perl Compatible Regular Expressions)
元字符分类:字符匹配、匹配次数、位置锚定、分组
BRE元字符
字符匹配:
[:alnum:] 字母和数字,即a-z,A-Z,0-9
[:upper:] 大写字母,即A-Z
[:space:] 水平和垂直的空白字符,包括空格键,[tab],CR等
[:xdigit:] 十六进制数字,包括:0-9,A-F,a-f的数字与字符
匹配次数:
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次(贪婪模式:尽可能长的匹配)
.* 任意长度的任意 。 例如:a*,可以表示a,aa,aaa,aaaaa,aaaa…a.
\? 匹配其前面的字符0或1次 。 例如:ab\?c ,表示ac,abc
\+ 匹配其前面的字符至少一次 。 例如:ab\+c 表示abc,abbc,abbbc等。 \+匹配前面一个字符
最少1次,最多任意次,不包括0次。
\{n\} 匹配前面的字符n次。 例如: ab\{2\}c ,表示在a与c之间有两个b,
即abbc
{m,n} 匹配前面的字符至少m次,至多n次 。 例:ab{1,3} c,表示在a与c之间有1个到3个b,即 abc,abbc,abbbc
\{,n\} 匹配前面的字符至多n次 例:ab\{,3\}c,表示ac,abc,abbc,abbbc。
最多3次,可以包括0次。
{m,} 匹配前面的字符至少m次 例:ab{2,}c,表示a与c之间最少有2个b,即 abbc,abbbc,abbbbc,abbb…c
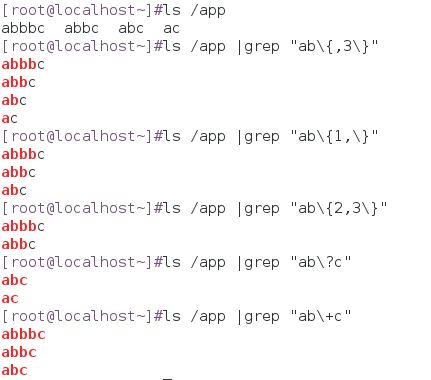
示例:在/app下先创建一些文件,运用BRE中匹配次数,进行简单的操作。如下图:

位置锚定:
定位出现的位置
^ 行首锚定,用于模式的最左侧 例:^content,匹配行首为content的行
$ 行尾锚定,用于模式的最右侧 例:txt$,匹配行末为txt结尾的行;^$匹配空白行
^PATTERN$ 用于模式匹配整行 ;^$匹配空行;^[[:space:]]*$匹配空白行
\< 或 \b 词首锚定,用于单词模式的左侧 例:\<th匹配… this…,但不匹配tenth等
\> 或 \b 词尾锚定;用于单词模式的右侧 例:p\>匹配leap,但不匹配parent等
\<PATTERN\> 匹配整个单词 例:\bat\b 匹配… at …, 但不匹配 cat 、batch等
下面我们在/etc/passwd文件中,运用BRE位置锚定来过滤查看一些文件的内容。如下图:
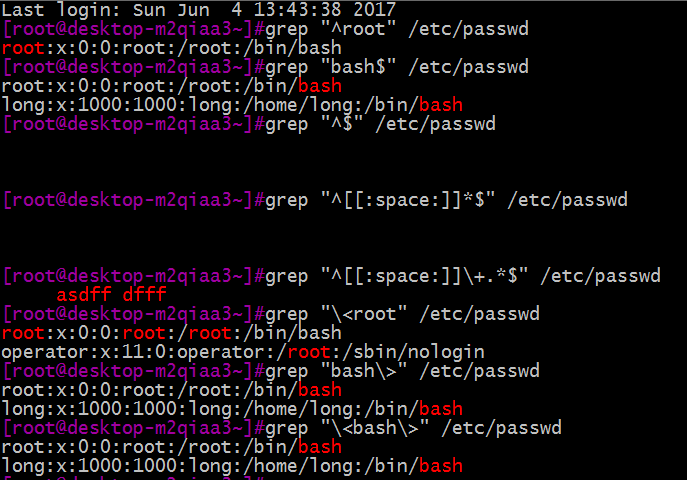
从上图中可以看出,^$,^[[:space:]]$只匹配空行;\<bash\>,只匹配带有整个单词bash的行,不匹配包含bash单词的 行,如sbin的行。
分组:
\(\) 将一个或多个字符捆绑在一起,当作一个整体进 行处理,如:\(root\)\+ ;
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …;
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符。
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
示例:\(root\)*\1
下面通过一些例子来简单介绍分组的基本用法,还是以/etc/passwd文件为例。如下图:
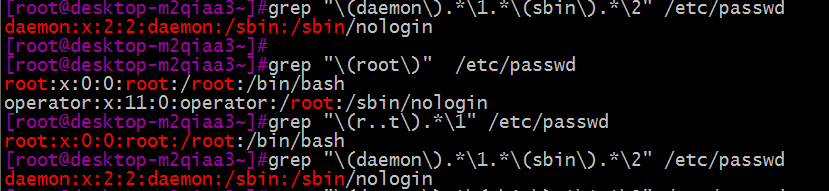
上图中:第一个组\(daemon\) ,\1表示调用第一个组匹配到的字符,不是模式本身;虽然都是daemon,但是意思不 一样。\2表示调用第二个组匹配到的字符。

或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
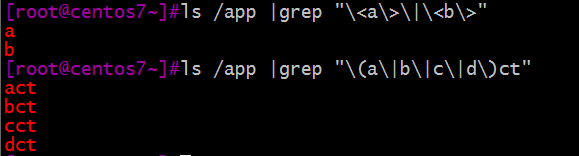
例:在/app下创建a、 b、 act、 bct、 cct、 dct 六个文件,运用正则表达式元字符或者,来进行些简单操作。如下图:
扩展正则表达式
元字符:
字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
位置锚定:
^ :行首
$ :行尾
\<, \b :语首
\>, \b :语尾
次数匹配:
*:匹配前面字符任意次
?: 0或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
分组:
() 后向引用:\1, \2, …
或者: a|b: a或b C|cat: C或cat
(C|c)at:Cat或cat
扩展正则表达式与基本正则表达式用法差不多;区别在于反斜杠”\“的不同。基本正则表达式元字符中,次数匹配,分组和或者都加反斜杠”\“;
而扩展正则表达式中,次数匹配,分组和或者都不需要加”\“。具体用法参考基本正则表达式,这里就不举例说明了。
原创文章,作者:shenjialong,如若转载,请注明出处:http://www.178linux.com/77432
