

文本处理工具之grep
一、grep的简介
1、grep是一个文本过滤器的工具,它根据用户指定的模式(pattern)对目标文本进行匹配检查,并将匹配的行打印到标准输出或输出重定向。
2、模式:由文本字符或正则表达式组成
3、正则表达式分两类:
基本正则表达式
扩展正则表达式
二、grep工具
grep的基本语法
grep [OPTIONS] PATTERN [FILE…]
选项:
-i:忽略字符大小写
-v:显示不能被模式匹配的行
-o:仅显示匹配的字符串
-q:静默模式,不输出任何信息(多用于脚本)
-c:显示统计到的行数,等同于wc -l
-e:指定多个搜索条件
-A #:匹配到的后#行
-B #:匹配到的前#行
-C #:匹配到的前后个#行
-E :是扩展正表达式
-n :表示显示行号
三、基本正则表达式的元字符
1、字符匹配:
. :任意单个字符
[] :匹配范围内任意单个字符,(如:[abc]表示可以是a 或b或c中的任意一个)
[^]:匹配范围外的任意单个字符
几种常用的特殊的字符集:
[:alnum:] 数字和字符
[:alpha:] 英文大小写字符 a-z A-Z
[:lower:] 小写字母
[:upper:] 大写字母
[:space:] 专门匹配空格
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:punct:] 标点符号
2、次数匹配
* :表是其前字符任意次
\?:表示其前字符0次或一次
\+:表示其前字符至少一次
\{m\}:表示其前字符m次
\{m,n\}:表示其前字符至少m最多n次
\{0,n\}:表示其前字符最多n次
\{m,\}:表示其前字符至少m次
3、位置锚定:
^ :锚定行首 (如:“^root”表示以“root”字符串作为行的开头)
$ :锚定行尾 (如:“root$”表示以“root”字符串作为行的行尾)
\<或\b:词首锚定
\>或\b:词尾锚定
^$:表示空行,但不包含空白字符
^[[:space:]]*$:表示空行,包含空白字符
\<PATTERN\>等同于\bPATTERN\b:表示匹配整个单词
4、分组
\(\)
分组是将一个或多个字符绑定在一起,当作一个整体来处理(比如后向引用:\1 \2 …)。
示例 :\(adc\(xyz\)\)利用后向引用
\1:表示第一个左括号以及与其匹配的右括号之间的匹配到的内容。本例中\1表示:abc\(xyz\)
\2:表示第二个左括号以及与其匹配的右括号之间的匹配到的内容。本例中\1表示:xyz
5、基本正则表达式的使用
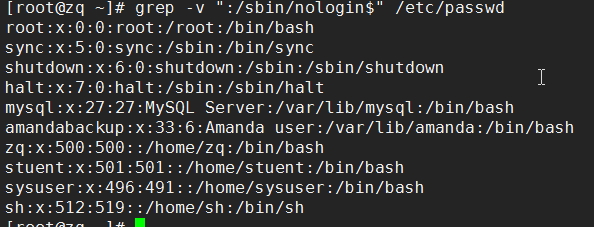
(1)显示/etc/passwd中不以/sbin/nologin结尾的行

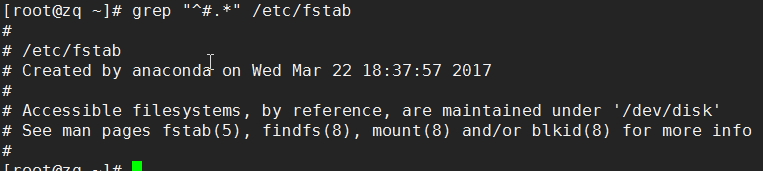
(2) 显示/etc/fstab文件中以#号开头的行
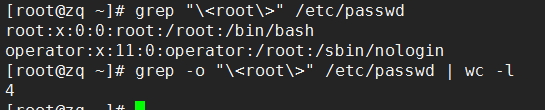
(3)显示root单词在/etc/passwd的文件中出现的次数
(4)找出当前系统上用户名和其默认shell相同的用户

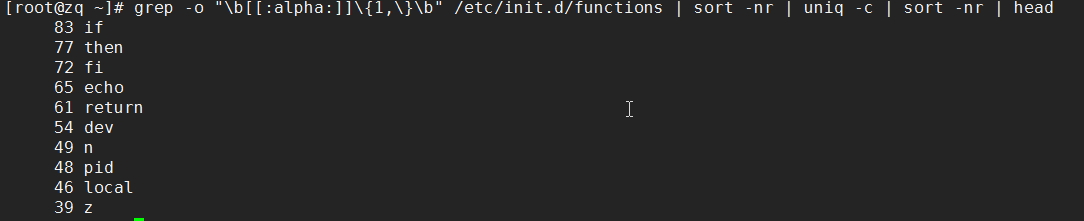
(5)统计/etc/init.d/functions文件中每个单词出现的次数,并统计出前十名
四、扩展正则表达式
1、字符匹配:
. :任意单个字符
[] :匹配范围内任意单个字符,(如:[abc]表示可以是a 或b或c中的任意一个)
[^]:匹配范围外的任意单个字符
2、次数匹配
* :表是其前字符任意次
?:表示其前字符0次或一次
+:表示其前字符至少一次
{m}:表示其前字符m次
{m,n}:表示其前字符至少m最多n次
{0,n}:表示其前字符最多n次
{m,}:表示其前字符至少m次
3、位置锚定
扩展正则表达式中的位置锚定和基本正则表达式相同
4、分组
():与基本正则表达式相比去掉了“\”转义,用法和基本正则表达式相同
5、扩展正则表达式也可以用 “egrep”这个文本处理工具,它等同于 “grep -E”
它俩的用法一致
6、扩展正则表达式的使用
(1)取出路径/etc/passwd的基名和路径名

(2)在/etc/passwd文件中以root开头行,并且行内至少再有一个root单词的行

(3)显示/etc/fstab 文件中以#开头其后跟了至少一个空白字符的行

原创文章,作者:zq,如若转载,请注明出处:http://www.178linux.com/74857
