

awk:文本三剑客之一
#报告生成器,主要用来实现格式化文本输出,它能够实现在处理文本文件时对文档中的某字段有条件显示并以非常美观的文本;
它是编程语言的解释器;它也是一种完整的编程语言,它支持条件判断、循环、变量、数组、函数等等各种各样的编程语言所能实现的功能。
用法:awk [options] ‘program’ FILE …
program: PATTERN{ACTION STATEMENTS}
PATTERN:awk在数据中查找的内容
ACTION STATEMENTS:动作语句,对查找的内容执行的一系列命令,多为awk内置的命令print和printf;多个语句之间用分号分隔;
注意:program中的字符串要加双引号。
选项:
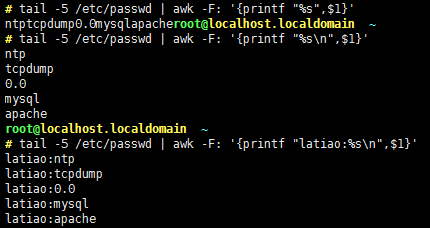
-F:指明从文件中输入数据时用到的字段分隔符;默认空白字符且不限制空白字符的个数,即同一行中一个空白字符、两个空白字符、三个空白字符等都是分隔符;
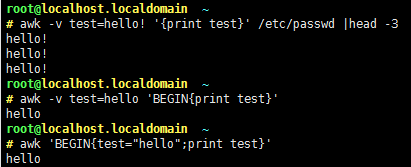
-v var=value: 自定义变量;

awk的print子命令
用法:print item1, item2, …
要点:
输出时默认以空白为分隔符;
输出的各item可以字符串,也可以是数值,还可以是当前记录的字段(例如$1、$2等等)、变量或awk的表达式;其中数值在输出时会被隐式转换成字符串以字符格式输出,但该数值参与运算时依然是数值;变量要想替换值一般不能用引号引起来;
省略item相当于print $0(即打印整行);
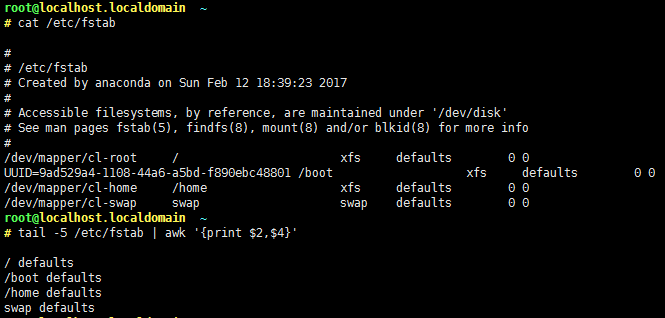
备注:打印/etc/fstab文件中后5行的第2和4字段;
AWK的变量:有内建变量和自定义变量两类;awk中引用变量不需要加$,只有引用字段变量时才用加$,例如$1、$2;
①内建变量
FS:input field seperator,输入字段分隔符,默认为空白字符;
OFS:output field seperator,输出字段分隔符,默认为空白字符;
RS:input record seperator,输入行分隔符,默认为换行符;
ORS:output record seperator,输出行分隔符,默认为换行符;
NF:number of field,每行字段数量
{print NF}:打印行的字段数量
{print $NF}:打印行的最后一个字段值
NR:number of record, 行数或行号
FNR:各文件分别计数;行数或行号
FILENAME:文件名;
ARGC:命令行参数的个数;
ARGV:保存了命令行参数的数组;
修改内建变量默认值:例如,#awk -v FS=”:”或#awk -F:(修改输入分隔符为冒号)
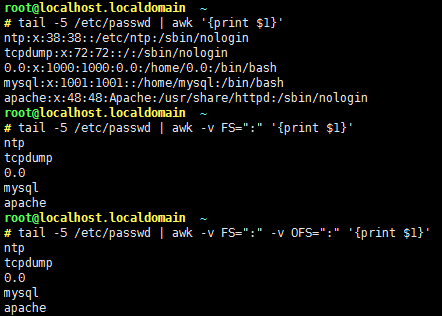
可以看到效果。。。。。。
②自定义变量
有两种方法:
1>-v var=value
变量名区分字符大小写;
2>在program中直接定义
awk的printf子命令:格式化输出
用法:printf FORMAT, item1, item2, …
要点:
FORMAT必须给出;
FORMAT中需要分别为后面的每个item指定一个格式符
不会自动换行需要显式给出换行控制符\n
格式符:每一个格式符还可以有它的修饰符
%c: 显示字符的ASCII码;
%d, %i: 显示十进制整数;
%e, %E: 科学计数法数值显示;
%f:显示为浮点数;
%g, %G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%: 显示%自身;
修饰符:用于格式符前面控制格式符显示的机制
#[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度,例如%3.1f
-: 左对齐,默认右对齐;
+:显示数值的符号;
注意:几乎所有的编程语言都支持格式化输出(包括bash);bash中也支持使用print和printf,不仅仅是echo;
awk中的操作符
①算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y:加,减,乘,除,次方,取模
-x:正数转换为负数;
+x: 字符串转换为数值;
②字符串操作符:默认只有一个,即没有符号的操作符(表示字符串连接);
③赋值操作符:=, +=, -=, *=, /=, %=, ^=(次方等),++, —
④比较操作符:>, >=, <, <=, !=, ==
⑤模式匹配符:
~:是否匹配
!~:是否不匹配
⑥逻辑操作符:&&,||,!
⑦函数调用:规范的函数调用方式,区别于bash中的函数调用;
function_name(argu1, argu2, …):“argu1, argu2, …”为向函数传递的参数;
⑧条件表达式:selector?if-true-expression:if-false-expression
selector是条件表达式,若selector为真则执行if-true-expression,否则执行if-false-expression;
PATTERN:实现地址定界的功能
①empty:空模式,即匹配每一行;
②/regular expression/:正则表达式,仅处理能够被此处的正则表达式匹配到的行;“//”为模式符号,凡是正则表达式都要放在模式符号中;
③relational expression: 关系表达式,结果有“真”有“假”,结果为“真”才会被处理;结果为非0值或非空字符串为真,否则为假;
④line ranges:行范围;
startline,endline:/pat1/,/pat2/
注意:不支持直接给出数字的格式
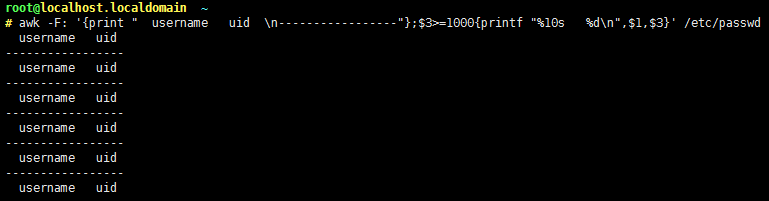
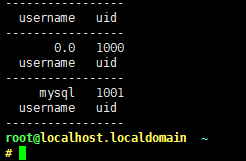
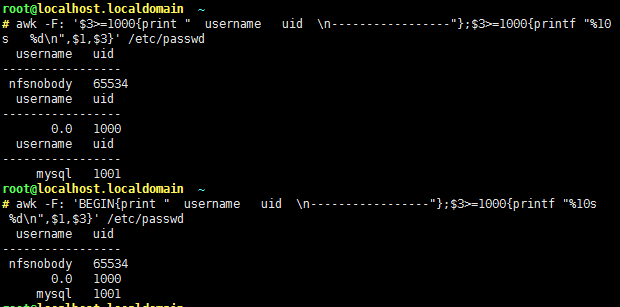
⑤BEGIN/END模式
BEGIN{}: 仅在开始处理文件中的文本之前执行一次,比如打印表头;若不对文件做处理则运行在BEGIN模式中;
END{}:仅在文本处理完成之后命令结束之前执行一次,比如打印处理结果;
蛮有意思的0.0
常用的action,有如下几类;
①Expressions:表达式,例如“a=6”;
②Control statements:控制语句,例如if, while等;
③Compound statements:组合语句,即把多个语句组合起来当一个代码块,通常用花括号括起来;
④Input statements:输入语句;
⑤Output statements:输出语句;
awk控制语句
if(condition) {statments}(只有一个语句花括号可以省略,下同):
if(condition) {statments} else {statements}
while(conditon) {statments}
do {statements} while(condition)
for(expr1;expr2;expr3) {statements}
break
continue
delete array[index]:删除数组中的某个元素
delete array:删除整个数组
exit
{statements}
控制语句
(1)if-else:很少用到多分支语句
语法:if(condition) statement [else statement]
使用场景:对awk取得的整行或某个字段做条件判断;
(2)while循环
语法:while(condition) statement,条件“真”,进入循环;条件“假”,退出循环;若首次条件判断为假,则循环体执行0次。
使用场景:对一行内的多个字段逐一进行类似处理时以及对数组中的各元素逐一进行类似处理时使用
(3)do-while循环
语法:do statement while(condition),与while的区别在于先执行一次循环体再判断;
(4)for循环:比while循环更简洁更易懂
语法:for(expr1;expr2;expr3) statement
详解:for(variable assignment变量赋值;condition条件判断;iteration process变量迭代) {for-body循环体}
特殊用法:能够遍历数组中的元素;
语法:for(var in array_name) {for-body}
示例:
(5)switch语句:多分支if语句,类似bash中case语句,但是关键字不同;常用于字符串等值比较或模式匹配判断;
语法:switch(expression) {case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; …; default: statement}:expression和“VALUE1 or /REGEXP/”
(6)break和continue
break [n]:跳出n层循环,控制行内循环(即字段间循环);
continue:跳出当前循环直接进入下一轮循环,控制行内循环;
(7)next:控制awk的内生循环(即行间循环)提前结束对本行的处理而直接进入下一行;
备注:使用while、do-while、for编写的循环控制awk的行内循环;
(8)array:较多使用关联数组;
关联数组:array[index-expression]
index-expression:
①可使用任意字符串,字符串要加双引号;
②如果某数组元素事先不存在,在引用时awk会自动创建此元素并将其值初始化为“空串”,当把该“空串”当数值使用时其值为零;
数组元素赋值详见“2016.01.05-bash编程之数组和字符串处理(1)”
数组元素引用使用print而非$;
判断数组中是否存在某元素要使用“index in array”格式进行判断;
遍历数组中的每个元素要使用for循环,格式为“for(var in array) {for-body}”,var会遍历array的每个索引;
函数
(1)内置函数
数值处理:
rand():返回0和1之间一个随机数,此处的随机指首次随机;
字符串处理:
length([s]):返回指定字符串的长度;
sub(r,s,[,t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容;该功能sed和grep更易用;
gsub(r,s,[,t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容;该功能sed和grep更易用;
split(s,a[,r]):以r为分隔符切割字符s并将切割后的结果保存至a所表示的数组中;awk中的数组下标从1开始;
(2)自定义函数:极少用;
原创文章,作者:All well,如若转载,请注明出处:http://www.178linux.com/73872
