

Redis基于keepalived的高可用实现
方案拓扑图
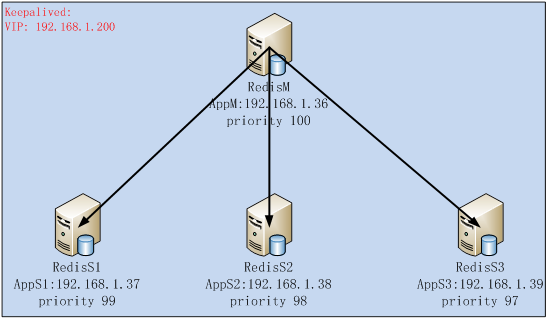

测试方案
1. 手动关闭AppM keepalived进程确认keepalived主从变化,AppS1是否变更为主
2. 开启keepalived,手动关闭 AppM redis进程确认ipvsadm ip池是否剔除AppM
3. 开启AppM redis进程,确认AppM是否变更为主
环境准备
服务器信息

配置服务器host
在Manager机器上配置好hosts后通过ansible下发到所有应用服务器
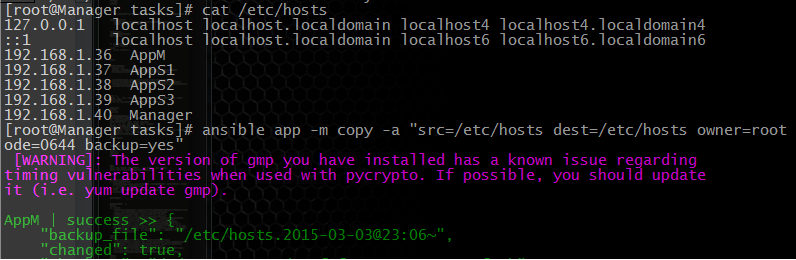
# ansible app -m copy -a "src=/etc/hosts dest=/etc/hosts owner=root group=root mode=0644 backup=yes"
//抽查对应服务器确认host无误后继续
安装配置keepalived
//安装keepalived ipvsadm
# ansible app -m command -a 'yum install keepalived ipvsadm -y'
//分发配置文件
# ansible AppM -m copy -a 'src=/data/ansible/config/keepalived/keepalived.conf-redis-Mrds dest=/etc/keepalived/keepalived.conf backup=yes' # ansible apps -m copy -a 'src=/data/ansible/config/keepalived/keepalived.conf-redis-Srds dest=/etc/keepalived/keepalived.conf backup=yes'
//登录AppS2
AppS3修改priority值
//运行keepalived
# ansible app -m command -a 'service keepalived restart' # ansible app -m command -a 'pidof keepalived'

//ip池

测试
1. 手动关闭AppM keepalived进程确认keepalived主从变化,AppS1是否变更为主


a> Vip资源已切换至AppS1,但同时我们也发现redis主从并没有切换
2. 开启keepalived,手动关闭 AppM redis进程确认ipvsadm ip池是否剔除AppM

3. 开启AppM redis进程,确认AppM是否变更为主

Redis会立刻同步服务到ip池
小总
a> Keepalived相对heartbeat要轻量简单,ipvsadm也由keepalived协助完成
b> Keepalived的redis应用场景需多master且mater互为同步,或
c> Keepalived的响应速度极快,异常进程或实例恢复后都能迅速发现并实施既定措施
d> 想通过redis自带的sentinel和keepalived结果会有些难度,也不建议
附件
keepalived.conf-redis-Srds
global_defs {
notification_email {
lisongtao@ihuilian.com
}
notification_email_from sa@ihuilian.com
smtp_server smtp.exmail.qq.com
smtp_connect_timeout 30
router_id LVS_DEVEL ##自定义的字符串
}
###在哪里找到自定义配置规范
#vrrp_script chk_nginx_down { #定义可以手动控制状态的脚本
# script "killall -0 nginx"
# interval 1 #检查时间间隔
# weight - 13 #如果检测失败,优先级-13
#}
vrrp_script chk_redis_down { #定义可以手动控制状态的脚本
script "killall -0 redis-server"
interval 1 #检查时间间隔
weight -2 #如果检测失败,优先级-13
}
vrrp_instance VI_1 {
state BACKUP ###MASTER/BACKUP必须大写,且当MASTER恢复时,会自动恢复为MASTER状态
interface eth0
virtual_router_id 51 ###同一个vrrp使用相同的vrrp,整个vrrp内唯一
priority 99 ###数字越大优先级越高,且要MASTER要高于SLAVE,和sentinel恰好相反...>O<
advert_int 1 ###Timeout时长秒为单位
authentication { ###MASTER和SLAVE密码相同方可正常通信
auth_type pass
auth_pass huilian
}
virtual_ipaddress { ###每个地址占一行,不能指定子网掩码,与lvs客户端设定的VIP一致
192.168.1.200
#192.168.200.17
#192.168.200.18
}
###跟global_defs中定义的vrrp_script chk_nginx_down对应
#track_script { #引用定义的脚本
# chk_nginx_down
#}
track_script { #引用定义的脚本
chk_redis_down
}
#notify_master "/etc/keepalived/notify.sh master"
#notify_backup "/etc/keepalived/notify.sh backup"
#notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.1.200 6379{ ###IP和vrrp_instance中定义的vip需一致,IP PORT
delay_loop 6 ###健康检查时间/秒
#lb_algo wlc ###负载均衡调度算法,常用rr/wlc
lb_algo rr ###负载均衡调度算法,常用rr/wlc
lb_kind DR ###负载均衡转发规则, DR,NAT,TUN3
nat_mask 255.255.255.0
#persistence_timeout 50 ###会话保持时长
protocol TCP ###协议类型转发
real_server 192.168.1.36 6379{ ###real server IP PORT
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.37 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.38 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.39 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
}
keepalived.conf-redis-Mrds
global_defs {
notification_email {
lisongtao@ihuilian.com
}
notification_email_from sa@ihuilian.com
smtp_server smtp.exmail.qq.com
smtp_connect_timeout 30
router_id LVS_DEVEL ##自定义的字符串
}
###在哪里找到自定义配置规范
#vrrp_script chk_nginx_down { #定义可以手动控制状态的脚本
# script "killall -0 nginx"
# interval 1 #检查时间间隔
# weight - 13 #如果检测失败,优先级-13
#}
vrrp_script chk_redis_down { #定义可以手动控制状态的脚本
script "killall -0 redis-server"
interval 1 #检查时间间隔
weight -2 #如果检测失败,优先级-13
}
vrrp_instance VI_1 {
state MASTER ###MASTER/BACKUP必须大写,且当MASTER恢复时,会自动恢复为MASTER状态
interface eth0
virtual_router_id 51 ###同一个vrrp使用相同的vrrp,整个vrrp内唯一
priority 100 ###数字越大优先级越高,且要MASTER要高于SLAVE,和sentinel恰好相反...>O<
advert_int 1 ###Timeout时长秒为单位
authentication { ###MASTER和SLAVE密码相同方可正常通信
auth_type pass
auth_pass huilian
}
virtual_ipaddress { ###每个地址占一行,不能指定子网掩码,与lvs客户端设定的VIP一致
192.168.1.200
#192.168.200.17
#192.168.200.18
}
###跟global_defs中定义的vrrp_script chk_nginx_down对应
#track_script { #引用定义的脚本
# chk_nginx_down
#}
track_script { #引用定义的脚本
chk_redis_down
}
#notify_master "/etc/keepalived/notify.sh master"
#notify_backup "/etc/keepalived/notify.sh backup"
#notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.1.200 6379{ ###IP和vrrp_instance中定义的vip需一致,IP PORT
delay_loop 6 ###健康检查时间/秒
#lb_algo wlc ###负载均衡调度算法,常用rr/wlc
lb_algo rr ###负载均衡调度算法,常用rr/wlc
lb_kind DR ###负载均衡转发规则, DR,NAT,TUN3
nat_mask 255.255.255.0
#persistence_timeout 50 ###会话保持时长
protocol TCP ###协议类型转发
real_server 192.168.1.36 6379{ ###real server IP PORT
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.37 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.38 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
real_server 192.168.1.39 6379{
weight 1 ###数值越大,权重越大
TCP_CHECK {
connect_timeout 1 #表示3秒无响应,则超时
nb_get_retry 3 #表示重试次数
delay_before_retry 3 #表示重试间隔
connect_port 6379 #表示重试间隔
}
}
}
下章节预告:
twemproxy + keepalived 实现redis的分布式高可用
原创文章,作者:stanley,如若转载,请注明出处:http://www.178linux.com/703
