

调度算法(ipvs
scheduler)
起点公平:平均分配,不管分别干的怎么样。
结果公平:谁现在还剩下的在处理的少,就分配给谁。
根据其调度时是否考虑各RS当前的负载状态,可分为静态方法和动态方法两种:
静态方法
静态方法:仅根据算法本身进行调度;
RR
RR:roundrobin,轮询;
轮询调度也叫1:1调度,调度器通过轮询调度算法将外部用户请求按顺序1:1的分配到集群中的每个Real Server上,,而不管服务器上实际的负载状况和连接状态。
注重“起点公平”。
WRR
WRR:Weighted RR,加权轮询;
根据Real Server的不同处理能力来调度访问请求。可以对每台Real Server设置不同的调度权值,对于性能相对较好的Real Server可以设置较高的权值,而对于处理能力较弱的Real Server,可以设置较低的权值,这样保证了处理能力强的服务器处理更多的访问流量。充分合理的利用了服务器资源。同时,调度器还可以自动查询Real Server的负载情况,并动态地调整其权值。
注重“结果公平”。
SH
SH:Source Hashing,主要用于实现session sticky(基于IP或者基于Cookie,这里SH使用的是基于IP的),源IP哈希
调度器自己维护一个IP表,将第一次请求被调度到哪里,记录下来。而第一次去到哪一个RS,就是使用WRR调度算法。SH方法,就是在WRR基础上,做了会话绑定。
这个方法的粒度,过于粗糙。只有需要维持会话(会话绑定)的场景,才会这么实现。
DH
DH:Destination Hashing;目标地址哈希。
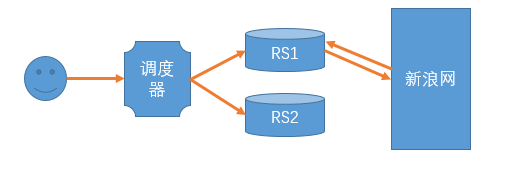

如果调度器背后是两台缓存服务器。那么如何提高缓存命中率呢?
只要访问的目标网站相同,调度器就转给同一个RS。比如所有需要新浪的资源,始终都转发到同一个服务器来处理。该服务器处理完后,进行缓存,这样之后请求同样内容的请求,就直接从缓存返回了。
这种应用场景,多数为缓存代理。
第一次访问时,使用WRR算法来决定调度到哪一个RS。
动态方法
动态方法:主要根据每RS当前的负载状态来调度算法进行调度。
LC
LC:Least Connection 最少连接
计算当前的负载Overhead=Active*256+Inactive来实现
分别给两个服务器50个链接做处理,第一个有40个,10个非活动,第二个50个,但是只有10个活动,40个非活动。
WLC
WLC:Weighted LC:加权LC
Overhead=(Active*256+Inactive)/weight
不同的服务器,有可能处理能力不同。那么就给他们不同的权值,处理能力高的,给高的权值,这样在分配的时候,处理能力高的服务器就会获得较多的请求数量。
SED
SED:Shortest Expect Delay 最短期望延迟
Overhead=(Active+1)*256/weight
在WLC算法中,如果计算结果相同时(比如说active和inactive都为0),LVS有一个“自上而下”的挑选方法。但是权重更大的,说明处理能力更强,应该给处理能力强的。而WLC不能够做到,但是SED算法能够做到。
非活动链接,占用资源非常小,所以不加非活动资源了。
NQ
Nq:Nerver Queus: 永不排队
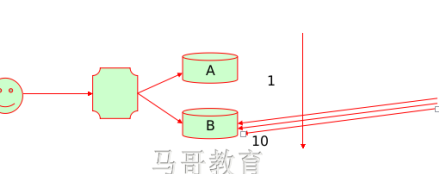
在SED算法中,A和B计算结果相同时(假设都为0),新的前几个链接请求来时,根据SED算法和WLC算法,都会分配给B,A就空闲了。所有就有了NQ。
NQ让每一个服务器都来至少有一个活动的链接在处理。
以上几种算法中,最常用的是WLC。因为服务器处理性能是很重要的指标,而计算结果相同的概率并不高却要浪费多一些的CPU资源。
LBLC
LBLC:Locality-based least connection(其实就是动态的DH算法) 基于本地的最少连接
相当于DH+LC
DH在做调度时,只根据目标站点进行调度,并不考虑RS的承受能力。是基于WRR算法的。而LBLC也是根据目标站点进行调度,但是第一次访问时,使用LC算法决定调度到哪一个RS。
LBLCR
LBLCR:Replicated and Locality-based least
connection:带复制功能的LBLC
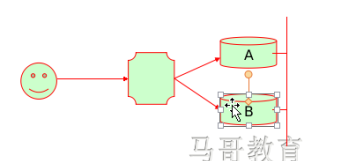
假设一种情况,这一段时间得到请求访问的都是曾经访问过的资源的(比如是新浪的资源,而该资源缓存在A中),按照LBLC或者DH算法,他们直接在调度器中调度到A来处理。那么A的压力就会非常大,而B就非常轻松。这种情况下LBLCR算法就显示出了他的好处。
LBLCR算法,要求A和B的缓存内容共享,并且在极不均衡的情况下,将一些链接从A转给B,B从A处取得缓存资源,并处理。
总结
Dh、LBLC、LBLCR被调度的主机通常是缓存服务器。
SH只是用来做会话绑定的。
其他算法更多的考虑的是公平调度。
原创文章,作者:m20-吴清玲,如若转载,请注明出处:http://www.178linux.com/55234
