

RAID简介
RAID(Redundant Arry of Independent Disks)独立冗余阵列,旧称(Redundant Arry of Inexpensive Disks)廉价冗余阵列,其主要目的是将多个硬盘组成在一起来达到提高I/O、读写、冗余性。
RAID分为硬件RAID和软件RAID
硬件RAID通过RAID卡连接多个硬盘、或者主板中集成了RAID控制器来实现RAID的相关功能。
软件RAID则通过软件层面模拟实现RAID的相关功能。
RAID常见级别介绍
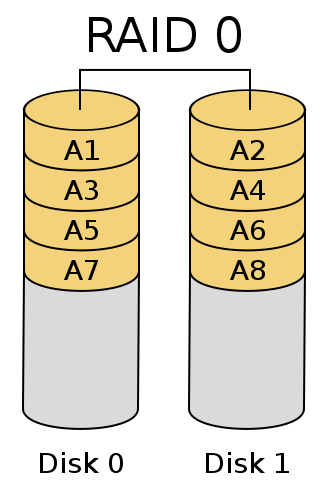
RAID-0
将多块硬盘平行组织起来并行处理以提高性能
简单来说就是将要处理的数据块(chunk)分别在两个硬盘上同时处理, Disk0处理A1,Disk1处理A2,从而实现提高硬盘性能,但是这样的话硬盘性能虽然提高了但是可靠性大大降低,由于RAID-0的特性,只要有一块硬盘损坏,这个磁盘阵列上的所有数据都可能会丢失,生产环境中一般不会使用。
RAID-0总结
1、提高了磁盘读、写、IO性能,理论为硬盘原速度的*硬盘数
2、无容错能力
3、最少使用2块硬盘
4、硬盘可用空间,为所有硬盘中空间最小的硬盘空间乘以硬盘总数, 公式 N*min(Disk0..DiskN)
 本文图片转自维基百科
本文图片转自维基百科
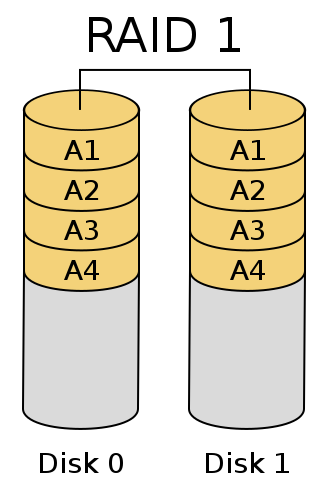
RAID-1
将多个硬盘相互做成镜像,提高冗余能力,读取速度
简单的来说就是两个(一般情况下RAID-1都是两个硬盘组成)或多个硬盘做成镜像,例如:给Disk0写入数据的时候,Disk1也写入数据,当Disk0损坏,Disk1的数据还保存着。这样极大提高了冗余能力,读取时两个硬盘也可以并行读取来提高读取性能,但是写入速度略有下降。
RAID-1总结
1、提高了读性能,写性能下降
2、极大提高了容错能力
3、最少使用2块硬盘
4、硬盘可用空间,为所有硬盘中空间最小硬盘的空间大小, 公式 1*min(Disk0..DiskN)
 本文图片转自维基百科
本文图片转自维基百科
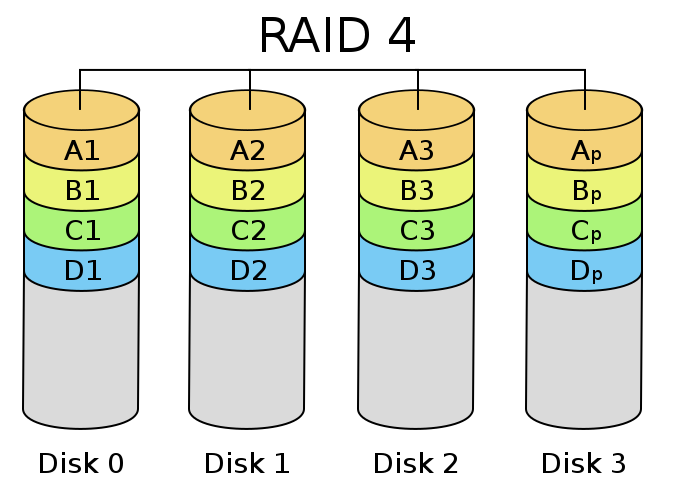
RAID-4
由3块或3块以上设备组成,并行处理提高磁盘性能,一个硬盘存储冗余校验码,通过异或运算还原数据
简单来说就是三个或三个以上的硬盘组成一组设备可以实现当某一个硬盘损坏可以使其数据通过异或运算还原,通过读写并行处理提高性能,但是因为冗余校验码都是存放在单一硬盘上,所以此硬盘性能可能会很差,并且易损坏。
RAID-4总结:
1、提高了读写、IO性能,但是存放校验码的硬盘性能差
2、提高硬盘容错能力,但是使用一块硬盘存放校验码,要是此硬盘损坏后果可想而知
3、最少使用3块硬盘
4、最大硬盘使用空间,为所有硬盘中空间最小的硬盘的空间大小乘以硬盘数减去1, 公式(N-1)*min(Disk1..DiskN)
 本文图片转自维基百科
本文图片转自维基百科
RAID-5
相比于RAID-4而言,冗余校验码分别存放在每个硬盘中
简单的来说,RAID-5就是RAID-4的升级版,弥补了RAID-4的缺陷,将RAID-4中被诟病的缺点:“冗余校验码存放在一个硬盘上”得以解决,RAID-5采用将冗余校验码分别存放在每一个磁盘上来达到负载均衡的效果,而且极大的提高了整体性能,但是只能提供一块硬盘的冗余。
RAID-5总结
1、提高了读写、IO性能
2、提高了容错能力,相比于RAID-4而言提高整体稳定性
3、最少使用3块硬盘
4、最大硬盘使用空间,为所有硬盘中空间最小的硬盘的空间大小乘以硬盘数减去1, 公式(N-1)*min(Disk1..DiskN)
 本文图片转自维基百科
本文图片转自维基百科
RAID-10/01
简单的来说,RAID-10/01是两种混合型RAID,RAID-10先将所有硬盘分成N组组成RAID-1提高冗余性,然后将其按组组成RAID-0提高硬盘性能,最多可支持半数硬盘损坏而不丢失数据。RAID-01先将所有硬盘分成N组组成RAID0提高性能,然后将其按组组成RAID-1提高冗余性,运气不好两块硬盘损坏就可能导致全部硬盘数据丢失。
RAID-10总结
1、提高了读写、IO性能
2、提高了容错能力,最多支持半数硬盘损坏
3、最少使用4块硬盘
4、最大硬盘使用空间,为所有硬盘中空间最小的硬盘的空间大小乘以2, 公式(N*min(Disk0..Disk1))/2
RAID-01总结
1、提高了读写、IO性能
2、提高了容错能力,但是效果不是很好,因为先使用不可靠的RAID-0在使用可靠的RAID1,就好像建房子地基偷工减料,而顶层却建的很结实
3、最少使用4块硬盘
4、最大硬盘使用空间,为所有硬盘中空间最小的硬盘的空间大小乘以2, 公式(N*min(Disk0..Disk1))/2
 本文图片转自维基百科
本文图片转自维基百科
 本文图片转自维基百科
本文图片转自维基百科
实战:在CentOS 6.7中使用mdadm建立软RAID
mdadm介绍:
Linux中可以通过md模块来实现软RAID,我们在用户空间用mdadm来管理创建软RAID设备
mdadm
命令的语法格式:mdadm [mode] <raiddevice> [options] <component-device>
支持的RAID级别:LINEAR, RAID0, RAID1, RAID4, RAID5,RAID6,RAID10
模式:
创建模式:-C
装配模式:-A
监控模式:-F
管理模式:-f, -r, -a
<raiddevice>:/dev/md#
<component-devices>:任意块设备
-C:创建模式
-n #:使用#个块设备来创建此RAID
-l #:指明要创建的RAID的级别
-a {yes|no}:是否自动创建目标RAID设备的设备文件
-c CHUNK_SIZE:指明块大小
-x #:指明空闲盘的个数
-D:查看raid的详细信息
mdadm -D /dev/md#
管理模式
-f:当作错误的磁盘来对待
-r:移除
-a:添加磁盘
系统环境:
分区信息 [root@server2 ~]# fdisk -l Disk /dev/sda: 21.5 GB, 21474836480 bytes 255 heads, 63 sectors/track, 2610 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x0002777c Device Boot Start End Blocks Id System /dev/sda1 * 1 26 208813+ 83 Linux /dev/sda2 27 1985 15735667+ 83 Linux /dev/sda3 1986 2247 2104515 82 Linux swap / Solaris Disk /dev/sdb: 21.5 GB, 21474836480 bytes 255 heads, 63 sectors/track, 2610 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0xdee177d5 Device Boot Start End Blocks Id System
实现目标:创建一个可用空间为8G的RAID1设备, 要求其chunk大小为128K, 文件系统为ext4, 开机可自动挂载至/backup目录
创建相应分区,关于此操作如果有疑问可以查看我的相关博文
[root@server2 ~]# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-2610, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-2610, default 2610): +8G
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (1046-2610, default 1046):
Using default value 1046
Last cylinder, +cylinders or +size{K,M,G} (1046-2610, default 2610): +8G
Command (m for help): t
Partition number (1-4): 1
Hex code (type L to list codes): fd #创建软RAID必须要将FileSystem ID调整为fd,否则在使用过程中可能会出错
Changed system type of partition 1 to fd (Linux raid autodetect)
Command (m for help): t
Partition number (1-4): 2
Hex code (type L to list codes): fd
Changed system type of partition 2 to fd (Linux raid autodetect)
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
通告内核重读分区表
[root@server2 ~]# partx -a /dev/sdb BLKPG: Device or resource busy error adding partition 1 BLKPG: Device or resource busy error adding partition 2
使用mdadm命令创建RAID1
[root@server2 ~]# mdadm -C /dev/md0 -a yes -c 128 -n 2 -l 1 /dev/sdb{1,2} #这里用分区创建RAID,不推荐,为了实验效果,请见谅
mdadm: /dev/sdb1 appears to contain an ext2fs file system
size=10490412K mtime=Mon Jan 4 13:26:31 2016
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
查看创建的RAID设备
[root@server2 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Mon Jan 4 13:28:54 2016 Raid Level : raid1 Array Size : 8385728 (8.00 GiB 8.59 GB) Used Dev Size : 8385728 (8.00 GiB 8.59 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Mon Jan 4 13:29:36 2016 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Name : server2.example.com:0 (local to host server2.example.com) UUID : a6177d12:198d6c82:3e2f5ac9:5f3925b3 Events : 17 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 18 1 active sync /dev/sdb2
格式化RAID设备
[root@server2 ~]# mke2fs -t ext4 /dev/md0 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 524288 inodes, 2096432 blocks 104821 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2147483648 64 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 20 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
设置RAID设备开机自动挂载
[root@server2 ~]# blkid /dev/md0 #建议使用UUID方式挂载 /dev/md0: UUID="f1f1a7f7-ea47-4bff-b28f-65e74fcdc0a0" TYPE="ext4" [root@server2 ~]# vim /etc/fstab # # /etc/fstab # Created by anaconda on Sat Jan 2 05:05:04 2016 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # UUID=3f5cfd75-ff54-4784-9aa3-47cbc77eed5a / ext4 defaults 1 1 UUID=0f99960c-0db8-44a9-81b6-f1adfcb0fc6c /boot ext4 defaults 1 2 UUID=bbcb90b4-d4a4-4a72-b66c-061afc7ce4e6 swap swap defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 UUID="f1f1a7f7-ea47-4bff-b28f-65e74fcdc0a0" /backup ext4 defaults 0 0
验证是否能够挂载
[root@server2 ~]# mount -a [root@server2 ~]# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda2 15357672 3527392 11043500 25% / tmpfs 502384 0 502384 0% /dev/shm /dev/sda1 198123 36589 151094 20% /boot /dev/md0 8123000 18420 7685296 1% /backup
测试RAID1效果
[root@server2 ~]# cd /backup/ [root@server2 backup]# ls lost+found [root@server2 backup]# touch RAID-1-TEST #在RAID设备中创建文件 [root@server2 backup]# ls lost+found RAID-1-TEST [root@server2 backup]# cd / [root@server2 /]# mdadm -f /dev/md0 /dev/sdb1 #模拟sdb1损坏 mdadm: set /dev/sdb1 faulty in /dev/md0 [root@server2 /]# mdadm -D /dev/md0 #查看md0信息 /dev/md0: Version : 1.2 Creation Time : Mon Jan 4 13:28:54 2016 Raid Level : raid1 Array Size : 8385728 (8.00 GiB 8.59 GB) Used Dev Size : 8385728 (8.00 GiB 8.59 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Mon Jan 4 13:36:04 2016 State : clean, degraded Active Devices : 1 Working Devices : 1 Failed Devices : 1 Spare Devices : 0 Name : server2.example.com:0 (local to host server2.example.com) UUID : a6177d12:198d6c82:3e2f5ac9:5f3925b3 Events : 44 Number Major Minor RaidDevice State 0 0 0 0 removed 1 8 18 1 active sync /dev/sdb2 2 8 17 - faulty /dev/sdb1 #提示报错 [root@server2 /]# cd /backup/ [root@server2 backup]# ls #发现数据并未丢失 lost+found RAID-1-TEST
总结:RAID的确可以提高生产环境中磁盘的性能和可靠性,但是不推荐使用软RAID的方式来实现,数据无价!
原创文章,作者:Net18-AnyISalIn,如若转载,请注明出处:http://www.178linux.com/12262
