

ELK6.2.2(elasticsearch+logstash+kibana)开源日志分析平台搭建(零):源起


1现状:
我司目前日志情况是,在各个IDC部署四个大业务线程序。日志统一打印到各自IDC的/logdata目录。此目录为百T级别的gluster。在其中,日志按照机器名称=》程序名称的目录结构存放。在同一目录下,分别为同一程序的运行日志(process.log),错误日志(error.log),下行日志(submit.log),上行日志(recv.log)等类别的日志,并按照日期切分。
[superuser@ft3q-app47 logs]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-LogVol01
1.1T 106G 920G 11% /
/dev/sda1 190M 41M 140M 23% /boot
tmpfs 24G 0 24G 0% /dev/shm
192.168.193.201:/logdata
110T 45T 65T 41% /logdata
192.168.173.201:/logdata
37T 11T 27T 28% /logdata-1- 2出现的问题:
2.1运维同事目前还是用传统的查询文件方式查看日志。cat error.log_yyyy_mm_dd|grep “keyword”。在分布式、微服务的环境下, 比较繁琐,而且还容易遗漏,最重要的是效率低。
2.2询问一条消息的消息轨迹时无从下手,分别经过的服务端、逻辑和网关模块因为分布式太多了。
- 3痛点:
3.1从海量分散文件中,迅速、准确地找到包含某关键词的日志。
3.2完整找出某关键词在某一时间段内出现在的每个日志中,即消息轨迹。
- 4解决方案:
构建我司自己的日志分析系统。
- 5方案一
5.1splunk
Splunk是大数据领域第一家在纳斯达克上市公司,Splunk提供一个机器数据的引擎。使用 Splunk可收集、索引和利用所有应用程序、服务器和设备(物理、虚拟和云中)生成的快速移动型计算机数据 。从一个位置搜索并分析所有实时和历史数据。 使用 Splunk 处理计算机数据,可让您在几分钟内(而不是几个小时或几天)解决问题和调查安全事件。监视您的端对端基础结构,避免服务性能降低或中断。以较低成本满足合规性要求。关联并分析跨越多个系统的复杂事件。获取新层次的运营可见性以及 IT 和业务智能。
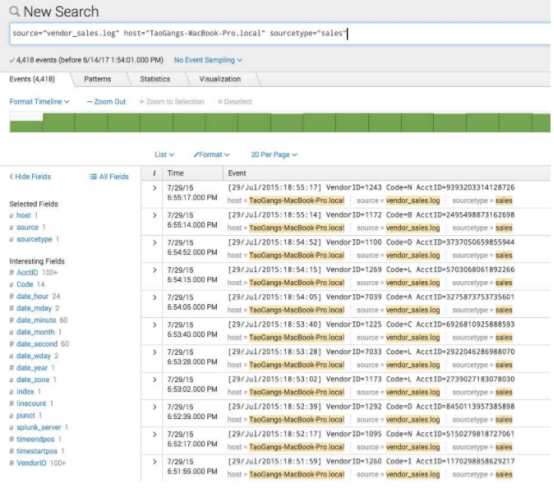
但因为其要求每日数据量小于500M,否则收费,每月225美元,并且其可拓展性差。我司每日某一业务线日志量就可达300G。所以我们不用。(还不是因为要钱嘛)
5.2ELK stack
ELK 是elastic公司提供的一套完整的日志收集、展示解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana
ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。ELK 是elastic公司提供的一套完整的日志收集、展示解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
Kibana为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
其特点是代码开源,并且是JAVA写的,有完善的REST API,我们可以拓展程序。所以选择ELK进行日志分析。
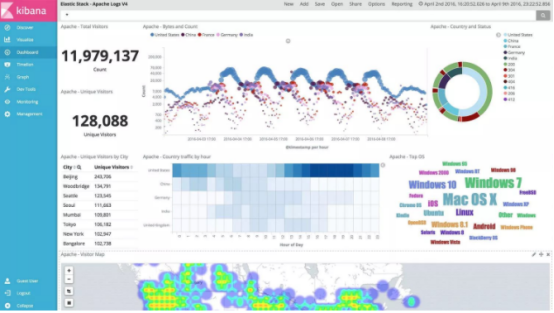
- 6规划一:ELK读取分散文件
方案设计:
在不改动现有平台的情况下,增加一套ELK读取分散的文件。通过logstash组件读取每个文件建立索引入es,运维人员可通过kibana方便查询。架构如下:
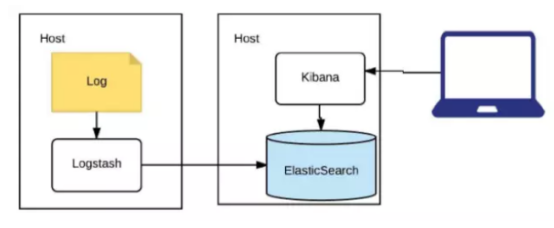
优点:现有程序完全没有改动。
缺点:
1日志还是零散分部,cluster有报出文件性能差问题。
2日志占用空间,导入ES后索引占用空间,即数据冗余。
3 Logstash Agent的维护不是很理想,Logstash是基于Ruby的,启动它就要有几十兆内存被jvm吃掉,我们想避免在每个机器上都要起一个Logstash。并且在我们使用过程中Logstash非常不稳定,莫名其妙就死掉了,还需要一个守护进程守护它。
4log标准化。现阶段各程序日志还是不标准。
- 6规划二:增加KAFKA
日志直接写入KAFKA,logstash抽取KAFKA数据入ES,运维人员可通过kibana方便查询。架构如下:
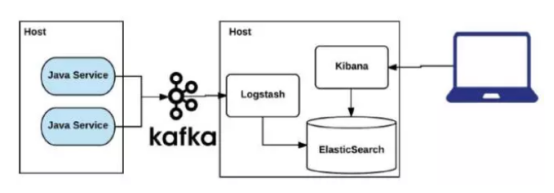
此架构避免了单个logstash读取多文件会卡的问题。使用kafak,可以让统一模块如cmpp服务端写入同一kafka话题(topic),使得负载均衡的模块可以完整地录入。Logstash通过读取一个topic赋予一个确定的索引如 logstash-server-cmpp,在以后查询中就可以批量查询同一功能的日志了。
优点:
1去除日志gluster。
2日志规范化后,可以精细查询每条日志。并且可以分词检索。
3完整,精确。消息轨迹可以查询出来。
4建立相应索引后,可以快速检索。
缺点:
1需要对现有程序进行改动,1建立标准化日志打印公共包2引入kafka包3修改log4j配置文件
2申请资源,每个IDC需要搭建至少一套kafka、ELK。
对现有平台的影响:
1、程序改动。程序必须改动,可以分批次地灰度上线。
2、容错机制。kafka使用集群部署,一般不会挂掉。如果kafka挂掉,程序可以运行。
3、性能。底层使用apach自己的kafka-clients,性能应该能保证。经测试,单个log入单个topic速度在700/s。
4、运维人员查询机制。由以往登入跳板机,grep各模块文件,转换到查询模块索引,指定某字段为某值,web页面查询。
5、报警机制改变。以往基于error日志文件。现在可以使用ES自带的查询API监控某一个TOPIC,出现关键字报警。
6、配套程序开发。定时删除kafka数据,定时删除es索引,监控程序等。
- 7规划三:每个IDC分业务搭建多套ELK
日志量大以后,每个IDC内部根据业务进行细分,分出多套日志系统。架构如下:
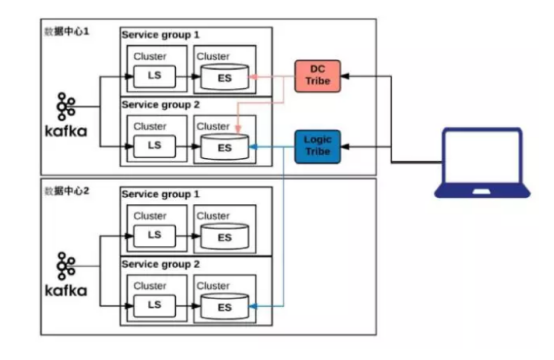
根据LinkedIn(领英)的使用情况来看,有20多个针对不同业务模块的ELK集群,1000+服务器,主要都是Elasticsearch。1分钟之内生产系统发生的log这边就可以搜索,所有的log保留7到14天。现在大概有500亿的索引文档,500到800T,之前测试时推到1500到2000T都是可以工作的。
- 8目前测试情况:
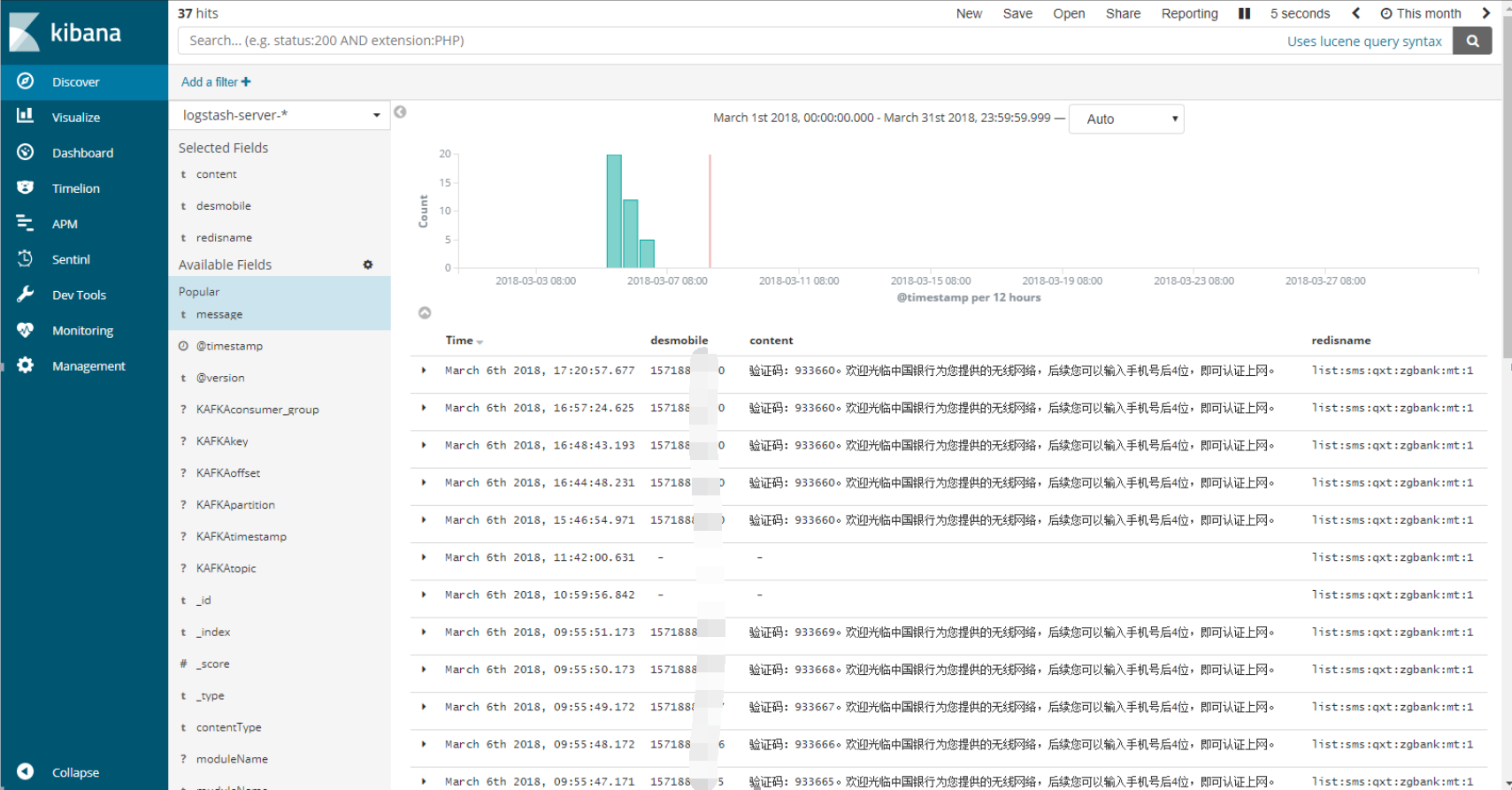
ft3q IDC的tapp21-tapp23部署3台kafka集群。tapp25部署ELK。测试程序分别模拟服务端、逻辑、网关发送至3个topic,logstash消费信息并且赋予3种索引。其中submit明细我做了分词,将手机号、内容、redis队列名解析出来。
ELK6.2.2(elasticsearch+logstash+kibana)开源日志分析平台搭建(一):es简单搭建
1物理环境
物理机配置
| IP | CPU | 内存 | 硬盘 |
|---|---|---|---|
| 192.168.193.47 | E5-2650v2 | 48G | 1TB |
| 192.168.193.147 | E5-2650v2 | 48G | 1TB |
| 192.168.193.48 | E5-2640v3 | 64G | 1TB |
| 192.168.193.148 | E5-2640v3 | 64G | 1TB |
因为强调elk比较吃机器,所以网络部门同事给了不错的机器。应该可以运行elk。
[superuser@ft3q-app47 elk]$ top
top - 16:59:37 up 87 days, 22:55, 1 user, load average: 27.89, 24.80, 24.19
Tasks: 622 total, 2 running, 620 sleeping, 0 stopped, 0 zombie
Cpu(s): 3.5%us, 3.0%sy, 0.0%ni, 92.7%id, 0.8%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 49397260k total, 48563720k used, 833540k free, 253412k buffers
Swap: 16777212k total, 3753420k used, 13023792k free, 15169808k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30512 superuse 20 0 86.3g 20g 460m S 176.5 44.3 9889:16 java
1086 root 20 0 0 0 0 S 2.6 0.0 271:20.94 jbd2/dm-1-8
2707 root 20 0 0 0 0 S 2.0 0.0 28:19.76 kondemand/2
2713 root 20 0 0 0 0 S 2.0 0.0 37:24.09 kondemand/8规划一下,在前3台安装ES集群。最后一台安装filebeat,packagebeat等小东西。
2安装java
因为是java写的,所以首先需要安装java。安装方法我就不写了。
[superuser@ft3q-app47 logs]$ java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)3官网找到最新版下载地址,下载。目前是6.2.2
[superuser@ft3q-app47 elk]$ pwd
/home/superuser/elk
[superuser@ft3q-app47 elk]$ ll
总用量 28
drwxr-xr-x 6 superuser superuser 4096 3月 22 13:25 cerebro-0.7.2
drwxr-xr-x 9 superuser superuser 4096 3月 14 16:01 es
drwxr-xr-x 5 superuser superuser 4096 3月 20 10:11 filebeat
drwxrwxr-x 12 superuser superuser 4096 3月 14 17:22 kibana
drwxrwxr-x 11 superuser superuser 4096 3月 22 10:18 logstash
drwxrwxr-x 14 superuser superuser 4096 3月 22 17:10 logstash_bank
drwxr-xr-x 4 superuser superuser 4096 3月 19 14:26 packetbeat
[superuser@ft3q-app47 elk]$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.2.tar.gz4解压并改名
[superuser@ft3q-app47 elk]$ tar -zxvf elasticsearch-6.2.2.tar.gz
[superuser@ft3q-app47 elk]$ mv elasticsearch-6.2.2 es5修改config/elasticsearch.yml配置文件
[superuser@ft3q-app47 es]$ vim config/elasticsearch.yml
#集群名称
cluster.name: ft3q
#节点名称
node.name: node-47
#如果是master节点设置成true 如果是
node.master: true
#如果是data节点设置成true
node.data: true
#数据储存路径
path.data: /home/superuser/elk/es/data
#日志储存路径
path.logs: /home/superuser/elk/es/logs
#监听地址
network.host: 192.168.193.47
#交互端口
http.port: 9200
#集群的三个节点
discovery.zen.ping.unicast.hosts: ["192.168.193.47", "192.168.193.147","192.168.193.48"]
#至少要发现集群可做master的节点数
discovery.zen.minimum_master_nodes: 2
#不锁内存
bootstrap.memory_lock: false
#Centos6不支持SecComp
bootstrap.system_call_filter: false
#如果启用了 HTTP 端口,那么此属性会指定是否允许跨源 REST 请求。
http.cors.enabled: true
#如果 http.cors.enabled 的值为 true,那么该属性会指定允许 REST 请求来自何处。
http.cors.allow-origin: "*"
#增大bulk队列大小
thread_pool.bulk.queue_size: 20000
#设置恢复时的吞吐量(例如:100mb,默认为0无限制.如果机器还有其他业务在跑的话还是限制一下的好)
indices.recovery.max_bytes_per_sec: 100mb
#可以使用值:eg:50mb 或者 30%(节点 node heap内存量),默认是:unbounded
indices.fielddata.cache.size: 50mb
#集群发现超时时间
discovery.zen.ping_timeout: 200s
#集群ping间隔
discovery.zen.fd.ping_interval: 30s
#超时
discovery.zen.fd.ping_timeout: 200s
6修改config/jvm.options配置文件
-Xms20g
-Xmx20g主要就是这两个值,根据自己的机器来配置。
7修改系统参数
如果现在启动es,仍然会报一些错,根据错误信息,修改系统参数。切换到root。
7.1max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
方案:vi /etc/sysctl.conf
fs.file-max=655350
保存之后sysctl -p使设置生效
vi /etc/security/limits.conf 新增
* soft nofile 655350
* hard nofile 655350
保存之后sysctl -p使设置生效
7.2max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
方案:vi /etc/sysctl.conf
vm.max_map_count=655360
保存之后sysctl -p使设置生效
可能还会遇到max number of threads [1024] for user [huang] is too low, increase to at least [4096]
需要修改用户的最大可用线程数,vim /etc/security/limits.d/90-nproc.conf
可能还会遇到system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
Centos6不支持SecComp,而ES5.2.0以后默认bootstrap.system_call_filter为true
禁用:在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
8终于可以启动
以后台方式启动
[superuser@ft3q-app47 es]$ ./bin/elasticsearch -d9验证一下
[superuser@ft3q-app47 es]$ curl 192.168.193.47:9200
{
"name" : "node-47",
"cluster_name" : "ft3q",
"cluster_uuid" : "vAUZvtDIQoWGReAgGu19Vw",
"version" : {
"number" : "6.2.2",
"build_hash" : "10b1edd",
"build_date" : "2018-02-16T19:01:30.685723Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
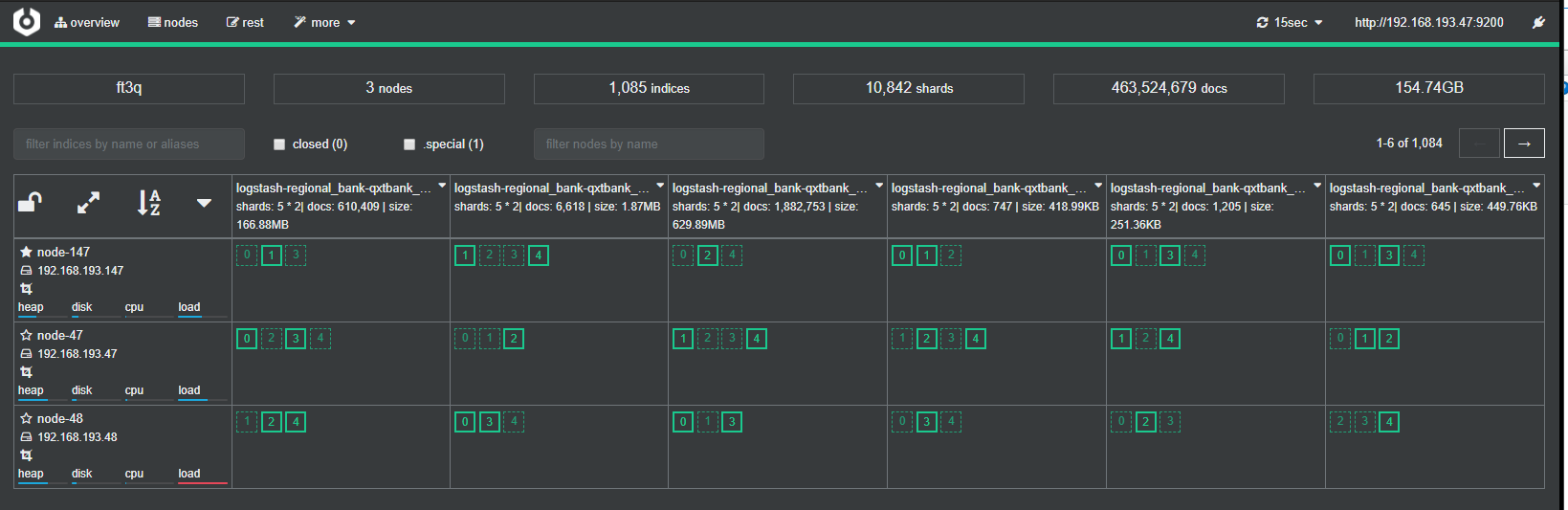
10其他两台也照此安装,最后可以看到,这三台组成集群,5分片*2副本,显示绿色。
ELK6.2.2(elasticsearch+logstash+kibana)开源日志分析平台搭建(二):kibana简单搭建
1下载,解压,重命名
[superuser@ft3q-app48 es]$ wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.2-linux-x86_64.tar.gz[superuser@ft3q-app48 es]$ tar -zxvf kibana-6.2.2-linux-x86_64.tar.gz[superuser@ft3q-app48 es]$ mv kibana-6.2.2-linux-x86_64 kibana2配置
[superuser@ft3q-app47 kibana]$ vim config/kibana.yml
#端口
server.port: 5601
#监听地址 本机
server.host: "0.0.0.0"
#命名
server.name: "kibanaServer47"
#es集群地址
elasticsearch.url: "http://192.168.193.47:9200"
#kibana入es的索引
kibana.index: ".kibana"
#x-pack插件安装后的用户名,密码
elasticsearch.username: "kibana"
elasticsearch.password: "kibana"
3启动,后台运行
[superuser@ft3q-app47 kibana]$ nohup ./bin/kibana &4查看运行情况
浏览器查看 http://192.168.193.47:5601
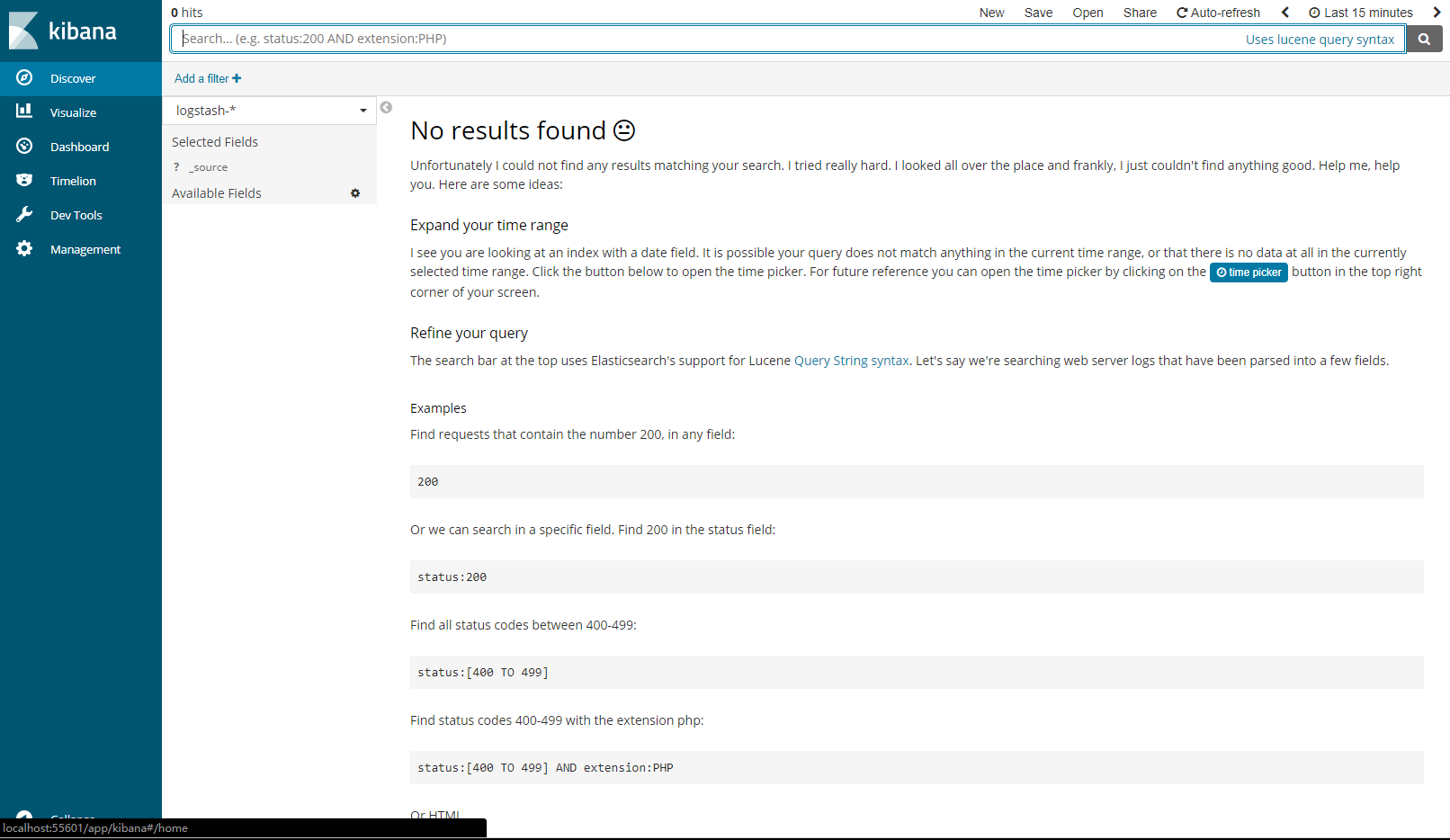
完美!
ELK(elasticsearch+logstash+kibana)开源日志分析平台搭建(四):logstash解析日志
前文已经简单搭建好了elk,现在就入数据这一方面,我们简单分析。
1现状:我司java程序全部使用log4j2经行日志写文件。其基本例子如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- status:log4j自身日志,monitorInterval:自动检测配置文件是否改变,单位:s -->
<configuration status="info" monitorInterval="5" shutdownHook="disable">
<Properties>
<!-- 配置日志文件输出目录 -->
<Property name="LOG_HOME">/logdata-local/path/to/log/</Property>
</Properties>
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout charset="UTF-8" pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} - %msg%n"/>
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) -->
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
</Console>
<!-- 服务端主日志 -->
<RollingFile name="asyncservice" fileName="${LOG_HOME}/service.log"
filePattern="${LOG_HOME}/service_%d{yyyy-MM-dd}_%i.log">
<Filters>
<!-- 打印除error日志所有日志 -->
<ThresholdFilter level="error" onMatch="DENY" onMismatch="NEUTRAL"/>
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<PatternLayout charset="UTF-8"
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="10"/>
</RollingFile>
<!-- 服务端错误日志 -->
<RollingFile name="asyncerror" fileName="${LOG_HOME}/error.log"
filePattern="${LOG_HOME}/error_%d{yyyy-MM-dd}_%i.log">
<Filters>
<!-- 打印error日志 -->
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<ThresholdFilter level="error" onMatch="DENY" onMismatch="ACCEPT"/>
</Filters>
<PatternLayout charset="UTF-8"
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true"
interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="8"/>
</RollingFile>
<RollingFile name="asyncmonitor" fileName="${LOG_HOME}/monitor.log"
filePattern="${LOG_HOME}/report_%d{yyyy-MM-dd}_%i.log">
<PatternLayout charset="UTF-8" pattern="%d{HH:mm:ss.SSS} - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="8"/>
</RollingFile>
<Async name="service" bufferSize="102400">
<AppenderRef ref="asyncservice"/>
</Async>
<Async name="error" bufferSize="102400">
<AppenderRef ref="asyncerror"/>
</Async>
<Async name="monitor" bufferSize="102400">
<AppenderRef ref="asyncmonitor"/>
</Async>
</appenders>
<loggers>
<Logger name="monitor" level="info" additivity="false">
<AppenderRef ref="monitor"/>
</Logger>
<root level="info">
<AppenderRef ref="Console"/>
<AppenderRef ref="service"/>
<AppenderRef ref="error"/>
</root>
</loggers>
</configuration>
其中主要使用了log4j2的异步缓冲池,5秒刷新配置,自动分日期打包文件等特性。
2目标
我们主要关注
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"
打出来的日志基本是这样:
2018-03-27 21:22:19.048 [pool-4-thread-1] INFO com.common.monitor.MonitorService [] - 监控redis连接#执行结果:OK,监控状态:redis状态:true(0,0)我决定使用logstash的grok插件,过滤信息
3成果
input{
file {
path => ["/logdata-local/*/*.log"]
exclude => "*_*.log"
max_open_files => "18600"
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}
filter{
grok {
match =>{
"message" =>"%{TIMESTAMP_ISO8601:logtime}\s\[%{DATA:logthread}\]\s%{LOGLEVEL:loglevel}\s\s%{DATA:logclass}\s\[\].{4}%{GREEDYDATA:logcontent}"
}
remove_field => ["message"]
}
date {
match => ["logtime", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
mutate {
add_field => { "filepath" => "%{path}" }
}
mutate{
split => ["filepath","/"]
add_field => {
"idx" => "%{[filepath][1]}-%{[filepath][2]}-%{[filepath][3]}"
}
add_field => {
"filename" => "%{[filepath][3]}"
}
}
mutate{
lowercase => [ "idx" ]
}
}
output {
elasticsearch {
hosts => ["192.168.193.47:9200","192.168.193.47:9200","192.168.193.47:9200"]
index => "logstash-bank-%{idx}-%{+YYYY.MM.dd}"
user => elastic
password => elastic
}
}过滤器意思将其自动生成的message信息解析,然后移除。将文件路径的“/”转化为“-”建立索引。索引不能有大写,最后都小写化。
解析出的日志时间,覆盖原始的@timestamp字段。
其基本将每条日志的时间、线程、日志级别、类和内容字段分析了出来,以后看运维同事有什么查询需求,将规范化内容再细化解析。
4kibana呈现
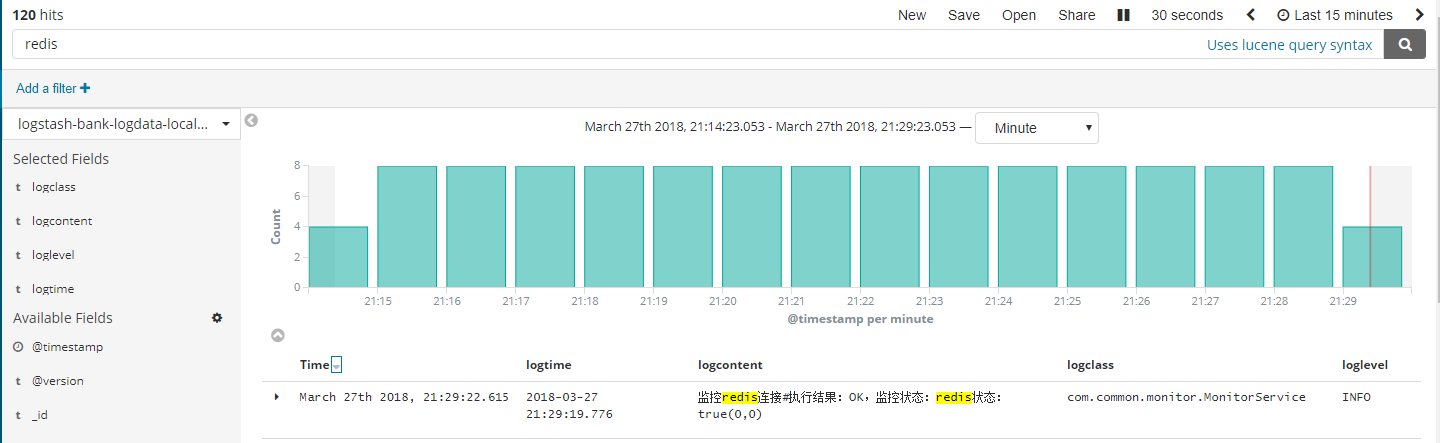
这样日志就像数据库一样,可以按照字段查询了。
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/104259
